IBM专家亲自解读 Spark2.0 操作指南
Spark 背景介绍
1、什么是Spark
在Apache的网站上,有非常简单的一句话,”Spark is a fast and general engine ”,就是Spark是一个统一的计算引擎,而且突出了fast。那么具体是做什么的呢?是做large-scale的processing,即大数据的处理。
“Spark is a fast and general engine for large-scale processing”这句话非常简单,但是它突出了Spark的一些特点:第一个特点就是spark是一个并行式的、内存的计算密集型的计算引擎。
那么来说内存的,因为Spark是基于Map Reduce的,但是它的空间数据不是存在于HDFS上面,而是存在于内存中,所以他是一个内存式的计算,这样就导致Spark的计算速度非常得快,同时它可以部署在集群上,所以它可以分布到各个的节点上,并行式地计算;Spark上还有很多机器学习和数据挖掘的学习包,用户可以利用学习包进行数据的迭代式计算,所以它又是一个计算密集型的计算工具。
2、Spark的发展历程
了解完什么是Spark之后,我们看一下Spark的发展历程。
Spark 2009年作为研究项目创建,13年成为Apache的孵化项目,14年成为Apache的顶级项目,Spark2.0还没有正式发布,目前只有比较draft的版本。
3、Spark2.0的最新特性
Spark2.0是刚出的,今天主要讲解它的两个部分,一个是它的new feature,就是它有哪些新的特性;另一部分是community,大家知道Spark是一个开源社区,社区对Spark的发展功不可没。

在feature这一部分,可以看到,Spark2.0中有比较重要的两个部分,其中一个就是Structured API。
Spark2.0统一了DataFrame和Dataset,并且引入了新的SparkSession。SparkSession提供了一个新的切入点,这个切入点统一了sql和sql context,对用户来说是透明的,用户不需要再去区分用什么context或者怎么创建,直接用SparkSession就可以了。还有一个是结构化的流,streaming。在Spark2.0中,流和bash做了一个统一,这样的话对用户来说也是透明的,就不在区分什么是流处理,什么是批量处理的数据了。
后面几个特性,比如MLlib,相信对data scientists非常有吸引力。MLlib可以将用户训练过的模型存储下来,等需要的时候再导入所需要的训练模型;从R上来说,原来SparkR上支持的只是单机单节点的,不支持分布式的计算,但是R的分布式的开发在Spark2.0中是非常有力的feature。此外,在Spark2.0中,SQL 2003的support可以让Spark在对结构化的数据进行处理的时候,基本上支持了所有的SQL语句。
4、为什么使用Spark

在传统方法中,MapReduce需要大量的磁盘I/O,从对比图中可以看到,MapReduce会将大量的数据存在HDFS上,而Spark因为是内存式的,就不需要大量的磁盘I/O,这一块就会非常快。
性能方面,在通用的任务上,Spark可以提高20-100倍的速度,因此Spark性能的第一点就是快;第二个就是比较高效,用过Scala开发程序的人应该有感受,Spark语法的表达非常强大,原来可能用十行去描述一段匹配的代码,Scala可能一行就可以做到,所以它效率非常地高,包括它也支持一些主流的编程的语言,java,Python,Scala,还有R等。
此外,Spark2.0可以利用已有的资产。大家知道hadoop的生态系统是非常有吸引力的,Spark可以很好地和hadoop的生态系统结合在一起。上面我们提到了社区的贡献,社区的贡献者不断得对Spark进行 improvement,使得Spark的发展越来越好,而且速度越来愈快。
以上这些特点导致了Spark现在越来越流行,更多的data scientists包括学者都愿意去使用Spark,Spark让大数据的计算更简单,更高效,更智能。
5、IBM对Spark的支持

IBM内部对Spark也是越来越重视,主要支持力度体现在社区培育、产品化和Spark Core上。社区方面,big data university的在线课程内容十分丰富,包括数据科学家、包括最基础的语言的开发,包括Spark、Hadoop生态基础的培训都很多,所以它培训了超过了一百万的数据科学家,并且赞助了AMP Lab,AMP Lab就是Spark开源社区的开发者。
第二个就是对Spark Core的贡献,因为在IBM内部,已经建立了Spark技术中心,超过了300名的工程师在进行Spark Core的开发。并且IBM开源的机器学习库,也成为了databricks的合作伙伴。
产品方面,在CDL就有一些Spark产品,集成到IBM本身的AOP环境里面,(注:AOP也是一个开源的软件包),包括Big Insight里面都集成了Spark的元素,IBM总共投入了超过3500名的员工在Spark的相关工作上。
Spark 基础
1、Spark核心组件
在Spark Build-in组件中,最基础的就是Spark Core,它是所有应用程序架构的基础。SparkSQL、Spark Streaming、MLLib、GraphX都是Spark Build-in组件提供的应用组件的子架构。
SparkSQL是对结构化数据的处理,Spark Streaming是对实时流数据的处理 ,MLLib就是对机器学习库的处理,GraphX是对并行图计算的处理。
不管是哪一个应用上的子架构,它都是基于RDD上的应用框架。实际上用户可以基于RDD来开发出不同领域上的子框架,运用Spark Build-in组件来执行。
2、Spark应用程序的架构
在每一个Spark应用程序中,只有一个Driver Program,和若干个Executor。大家可以看到右边的Work Node,我们可以认为Work Node就是一个物理机器,所有的应用程序都是从Driver开始的,Driver Program会先初始化一个SparkContext,作为应用程序的入口,每一个Spark应用程序只有一个SparkContext。SparkContext作为入口,再去初始化一些作业调度和任务调度,通过Cluster Manager将任务分配到各个节点上,由Worker Node上面的执行器来执行任务。一个Spark应用程序有多个Executor,一个Executor上又可以执行多个task,这就是Spark并行计算的框架。
此外,Executor除了可以处理task,还可以将数据存在Cache或者HDFS上面。
3、Spark运行模式
一般我们看到的是下图中的前四种Spark运行模式:Local、standalone、Yarn和Mesos。Cloud就是一种外部base的Spark的运行环境。

Local就是指本地的模式,用户可以在本地上执行Spark程序,Local[N]即指的是使用多少个线程;Standalone是Spark自己自带的一个运行模式,需要用户自己去部署spark到相关的节点上;Yarn和Mesos是做资源管理的,它也是Hadoop生态系统里面的,如果使用Yarn和Mesos,那么就是这两者去做资源管理,Spark来做资源调度。
不管是那种运行模式,它都还细分为两种,一种是client模式:一种是cluster模式,那么怎么区分这两种模式呢?可以用到架构图中的Driver Program。Driver Program如果在集群里面,那就是cluster模式;如果在集群外面,那就是client模式。
4、弹性分布式数据集RDD

RDD有几个特点,一是它不可变,二是它被分区。我们在java或者C++里,所用的基本数据集、数组都可以被更改,但是RDD是不能被更改的,它只能产生新的RDD,也就是说Scala是一种函数式的编程语言。函数式的编程语言不主张就地更改现有的所有的数据,而是在已有的数据上产生一个新的数据,主要是做transform的工作,即映射的工作。
RDD不可更改,但可以分布到不同的Partition上,对用户来说,就实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD本身是一个抽象的概念,它不是真实存在的,那么它分配到各个节点上,对用户来说是透明的,用户只要按照自己操作本地数据集的方法去操作RDD就可以了,不用管它是怎么分配到各个Partition上面的。
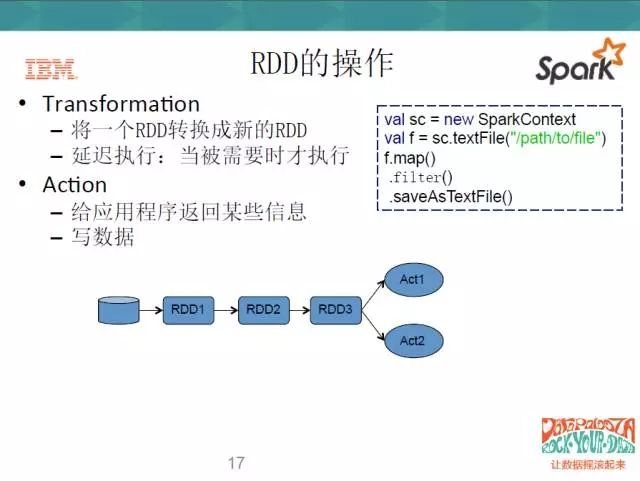
在操作上,RDD主要有两种方式,一种是Transform,一种是Action。Transform的操作呢,就是将一个RDD转换成一个新的RDD,但是它有个特点,就是延迟执行;第二种操作就是Action,用户要么写数据,要么给应用程序返回某些信息。当你执行Action的时候,Transform才会被触发,这也就是延迟执行的意思。
看一下右边的代码,这是一个Scala的代码,在第一行,它去创建了一个Spark的Context,去读一个文件。然后这个文件做了三个操作,第一个是map,第二个是filter,第三个是save,前面两个动作就是一个Transform,map的意思就是映射,filter就是过滤,save就是写。当我”写”的这个程度执行到map和filter这一步时,它不会去执行,等我的save动作开始的时候,它才会执行去前面两个。
5、Spark程序的执行
了解了RDD和Spark运行原理之后,我们来从整体看一下Spark程序是怎么执行的。

还是之前的三行代码,前两步是Transform,最后一步是Action。那么这一系列RDD就做一系列的Transform,从第一步开始转;DAG就是一个调度器,Spark context会初始化一个任务调度器,任务调度器就会将RDD的一系列转换切分成不同的阶段,由任务调度器将不同的阶段上分成不同的task set,通过Cluster Manager去调度这些task,把这些task set分布到不同的Executor上去执行。
6、Spark DataFrame
很多人会问,已经有RDD,为什么还要有DataFrame?DataFrame API是2015年发布的,Spark1.3之后就有,它是以命名列的方式去组织分布式的数据集。
Spark上面原来主要是为了big data,大数据平台,它很多都是非结构化数据。非结构化数据需要用户自己去组织映射,而DataFrame就提供了一些现成的,用户可以通过操作关系表去操作大数据平台上的数据。这样很多的data scientists就可以使用原来使关系数据库的只是和方式去操作大数据平台上的数据。
DataFrame支持的数据源也很多,比如说JSON、Hive、JDBC等。
DataFrame还有存在的另外一个理由:我们可以分析上表,蓝色部分代表着RDD去操纵不同语言的同样数量集时的性能。可以看到,RDD在Python上的性能比较差,Scala的性能比较好一些。但是从绿色的部分来看,用DataFrame来编写程序的时候,他们的性能是一样的,也就是说RDD在操作不同的语言时,性能表现不一样,但是用DataFrame去操作时,性能表现是一样的,并且性能总体要高于RDD。
下面是DataFrame的一个简单示例。

右边同样是用Scala写的一段代码,这就是sqlContext,因为它支持JSON文件,直接点JsonFile,读进来这个json文件。下面直接对这个DataFrame
df.groupBy(“ages”).count().show(),show出来的方式就是一个表的方式。这个操作就很简单,用户不用再做map操作,如果是用RDD操作的话,用户需要自己对数列里的每一块数据作处理。
7、Spark编程语言
在编程语言上,Spark目前支持的有以下四种:
8、Spark使用方式
使用上,如果本地有Spark集群,就有两种操作方式:一种是用Spark-shell,即交互式命令行;交互式的命令操作很简单,就和java一样,一行一行敲进去,它会交互式地告诉你,一行一行包括的是什么;这个地方也可以把一段代码复制过去,边运行边调试。一般来讲,交互式命令用Local模式就可以了。
第二种是直接用Spark-submit,一般在开发工程项目时使用较多;Spark-submit有几个必要的参数,一个是master,就是运行模式必须有;还有几个参数也必须有,比如class,java包的位置等。此外可以根据Spark-submit后面的help命令,来查看submit有多少参数,每个参数是什么意思。
此外可以通过Web-based NoteBook来使用Spark,在IBM的workbench上提供了Jupyter和Zepplin两种NoteBook的方式。
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>