Handoop安装并启动(centos6.5+HDFS HA+Fedaration+YARN)
所需环境:四台主机(笔者用四台VMware虚拟机代替),centos6.5系统,hadoop-2.7.1软件包,jdk1.8.0_91
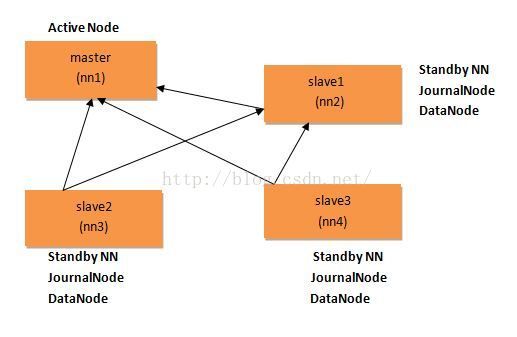
准备工作:创建四台虚拟主机,使用NAT模式访问网络。
1)在四台虚拟机中安装好hadoop和jdk软件;
2)更改每个主机的主机名:
[master]下:gedit/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
NTPSERVERARGS=iburst
[slave1]下:gedit/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
NTPSERVERARGS=iburst
[slave2]下:gedit/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
NTPSERVERARGS=iburst
[slave3]下:gedit/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave3
NTPSERVERARGS=iburst
3)更改各个主机的hosts文件:
[zq@master~]$ sudo gedit /etc/hosts
[sudo]password for zq:
在hosts文件中加入:
192.168.44.142 master
192.168.44.140 slave1
192.168.44.143 slave2
192.168.44.141 slave3
同理,在slave1,slave2,slave3中的hosts文件中添加同样ip。
4)关闭各个主机的防火墙:sudoservice iptables stop
开始配置安装:
1.设置免密码登录,如上图的结构图所示,ssh免密码登录使master可以免密码访问slave1,slave2,slave3即可,这里不进行详细解说。
2.在hadoop的配置文件中新建文件fairscheduler.xml:
[zq@master ~]$ cd/home/zq/soft/hadoop-2.7.1/etc/hadoop/
[zq@master hadoop]$ touch fairscheduler.xml
[zq@master hadoop]$ gedit fairscheduler.xml
配置fairscheduler.xml文件:
<?xml version="1.0"?> <allocations> <queue name="infrastructure"> <minResources>102400 mb, 50 vcores</minResources> <maxResources>153600mb, 100 vcores</maxResources> <maxRunningApps>200</maxRunningApps> <minSharePreemptionTimeout>300</minSharePreemptionTimeout> <weight>1.0</weight> <aclSubmitApps>root,yarn,search,hdfs,zq</aclSubmitApps> </queue> <queue name="tools"> <minResources>102400 mb,30 vcores</minResources> <maxResources>153600 mb, 50 vcores</maxResources> </queue> <queue name="sentiment"> <minResources>102400 mb,30 vcores</minResources> <maxResources>153600 mb, 50 vcores</maxResources> </queue> </allocations>
3.配置hadoop文件:core-site.xml:
[zq@master hadoop-2.7.1]$ sudo geditcore core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
<description>master=8020</description>
</property>
</configuration>
fs.default.name是定义master的url和端口号,读者可以将master改为自己设置的主机名或地址。
4.配置hadoop文件:hdfs-site.xml:
[zq@master hadoop-2.7.1]$ sudo gedithdfs-site.xml
<configuration><span style="color:#FF0000;">
分配集群cluster1,cluster2</span>
<property>
<name>dfs.nameservices</name>
<value>cluster1,cluster2</value>
<description>nameservices</description>
</property>
<!-- config cluster1-->
<span style="color:#FF0000;">为集群cluster1分配NameNode,名为nn1和nn2</span>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
<description>namenodes.cluster1</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>master:8020</value>
<description>rpc-address.cluster1.nn1</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>slave1:8020</value>
<description>rpc-address.cluster1.nn2</description>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>master:50070</value>
<description>http-address.cluster1.nn1</description>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>slave1:50070</value>
<description>http-address.cluster1.nn2</description>
</property>
<!-- config cluster2-->
<span style="color:#FF0000;">为集群cluster2分配NameNode,名为nn3和nn4</span>
<property>
<name>dfs.ha.namenodes.cluster2</name>
<value>nn3,nn4</value>
<description>namenodes.cluster2</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn3</name>
<value>slave2:8020</value>
<description>rpc-address.cluster2.nn3</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn4</name>
<value>slave3:8020</value>
<description>rpc-address.cluster2.nn4</description>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.nn3</name>
<value>slave2:50070</value>
<description>http-address.cluster2.nn3</description>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.nn4</name>
<value>slave3:50070</value>
<description>http-address.cluster2.nn4</description>
</property>
<!--namenode dirs-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/zq/soft/hadoop-2.7.1/hdfs/name</value>
<description>dfs.namenode.name.dir</description>
</property>
<span style="color:#FF0000;">创建Name存储路径,读者需更改为自己的路径</span>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>
qjournal://slave1:8485;slave2:8485;slave3:8485/cluster1
</value>
<description>shared.edits.dir</description>
</property>
<span style="color:#FF0000;">**这里必须注意,根据结构图,master和slave1共享cluster1,slave2和slave3共享cluster2</span>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:///home/zq/soft/hadoop-2.7.1/hdfs/data</value>
<description>data.dir</description>
</property>
<span style="color:#FF0000;">创建data路径</span>
</configuration>
5.配置hadoop文件:yarn-site.xml:
[zq@master hadoop-2.7.1]$ sudo gedit yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>hostname=master</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
<description>address=master:8032</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.addresss</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
<description>scheduler.address=master:8030</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.addresss</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
<description>webapp.address=master:8088</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.addresss</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
<description>https.addresss=8090</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.addresss</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.addresss</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
<description>admin.addresss</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>org.apache.hadoop.yarn.server.resourcemanager</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
<description>scheduler.fair.allocation.file=.xml</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/zq/soft/hadoop-2.7.1/yarn/local</value>
<description>nodemanager.local-dirs</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>yarn.log-aggregation-enable</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>remote-app-log-dir=/tmp/logs</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>30720</value>
<description>resource.memory-mb=30720</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>12</value>
<description>resource.cpu-vcores</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
<description>aux-services</description>
</property>
</configuration>
6.配置hadoop文件:mapred-site.xml
[zq@master hadoop-2.7.1]$ sudo gedit mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>slave1:10020</value>
<description>slave1=10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>slave1:19888</value>
<description>slave2=19888</description>
</property>
</configuration>
7.配置hadoop文件:hadoop-env.sh
[zq@master hadoop-2.7.1]$ sudo gedit hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/zq/soft/jdk1.8.0_91
8. 配置hadoop文件:slaves
[zq@master hadoop-2.7.1]$ gedit slaves
slave1
slave2
slave3
9.利用scp命令将以上所有配置文件拷贝到slave1,slave2,slave3中:
[zq@master etc]$ scp hadoop/*zq@slave1:/home/zq/soft/hadoop-2.7.1/etc/hadoop
[zq@master etc]$ scp hadoop/*zq@slave2:/home/zq/soft/hadoop-2.7.1/etc/hadoop
[zq@master etc]$ scp hadoop/*zq@slave3:/home/zq/soft/hadoop-2.7.1/etc/hadoop
10.至此,hadoop的所有配置已经完成。接下来开始启动hadoop服务:
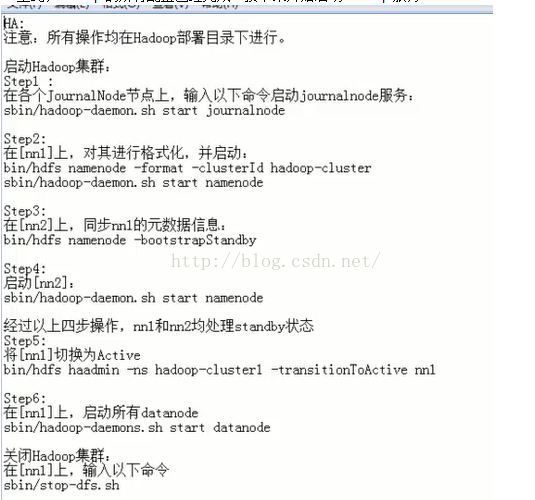
11.简单pi测试
[zq@master hadoop-2.7.1]bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jarpi 2 1000