Windows下安装Hadoop
Windows10下安装Hadoop,Windows10下编译64位Hadoop2.x。详细记录了Windows10版本下对Hadoop的编译、安装步骤,以及相关包或者软件下载安装过程。
不需要在Cygwin下安装Hadoop,官方也不推荐使用Cygwin。
Hadoop版本支持情况:Hadoop 2.2版本起包括Windows的原生支持。截至2014年一月份,官方的Apache Hadoop的版本不包括Windows二进制文件。
Windows版本支持情况:Hadoop官方人员开发、测试环境分别是32的 Windows Server 2008 和32位的 Windows Server 2008 R2 。因为服务器型号win32位的API相似,所以官方推测Windows7或者Windows Vista应该也是支持的。Windows XP Hadoop官方不测试也不支持。
总之,Windows版本的Hadoop需要在2.2之后可自行编译,并且不支持Windows XP,在其他Windows平台下,官方不予严格的支持(仅仅提供二进制文件,部分组件需要自行编译)。
以下内容是具体实施,Hadoop集群在Windows环境下支持情况调研与测试部署,罗列了Windows实际部署情况,以及所遇到的问题和解决方案。
1. 自行编译Windows环境的二进制包
Requirements:
* Windows System
* JDK 1.6+
* Maven 3.0 or later
* Findbugs 1.3.9 (if running findbugs)
* ProtocolBuffer 2.5.0
* CMake 2.6 or newer
* Windows SDK or Visual Studio 2010 Professional
* Unix command-line tools from GnuWin32 or Cygwin: sh, mkdir, rm, cp, tar, gzip
* zlib headers (if building native code bindings for zlib)
* Internet connection for first build (to fetch all Maven and Hadoop dependencies)1. 配置编译环境
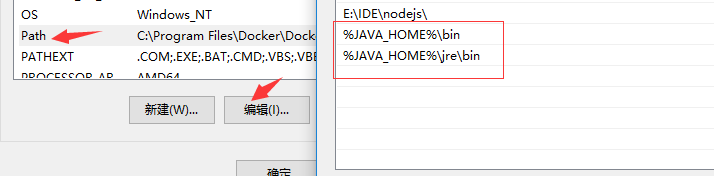
1.1. 设置JDK环境
JAVA_HOME设置
jdk设置path
 (http://img.blog.csdn.net/20160708162923904)
(http://img.blog.csdn.net/20160708162923904)
1.2. 安装编译工具maven
下载maven的zip包 将maven的根目录放置系统变量path中

测试mvn -v

1.3. 安装ProtocolBuffer
下载 先切换到带有pom文件路径中
cd E:\IDE\protobuf-3.0.0-beta-3\java通过mvn 安装 mvn test 测试 mvn install

1.4. 安装CMake
下载 安装即可。
1.5. 安装visual studio 2010之后(直接下载安装,不再赘述) 或者安装Windows SDK
2. 编译安装
设置环境编译环境位数 set Platform=x64 (when building on a 64-bit system) set Platform=Win32 (when building on a 32-bit system) 设置安装包环境 设置环境变量添加至将ZLIB_HOME至环境变量中 set ZLIB_HOME=C:\zlib-1.2.7 mvn编译命令
mvn package -Pdist,native-win -DskipTests -Dtar
3. 部署Hadoop on Windows
3.1 源码
core-site.xml 源码
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property>
</configuration>Hadoop-env.cmd 源码
set HADOOP_PREFIX=E:\bigdata\hadoop
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\binhdfs-site.xml 源码
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapre-site.xml 源码
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>wxl</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.apps.stagingDir</name>
<value>/user/wxl/staging</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>local</value>
</property>
</configuration>yarn-site.xml 源码
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.server.resourcemanager.address</name>
<value>0.0.0.0:8020</value>
</property>
<property>
<name>yarn.server.resourcemanager.application.expiry.interval</name>
<value>60000</value>
</property>
<property>
<name>yarn.server.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.server.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/dep/logs/userlogs</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.attempt-listener.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.client-service.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>%HADOOP_CONF_DIR%,%HADOOP_COMMON_HOME%/share/hadoop/common/*,%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*</value>
</property>
</configuration>slaves 源码
localhost3.2 初始化环境变量,运行hadoop-env.cmd文件(双击、或着回车执行)
E:\bigdata\hadoop\etc\hadoop\hadoop-env.cmd
3.3 格式化namenode
%HADOOP_PREFIX%\bin\hdfs namenode -format
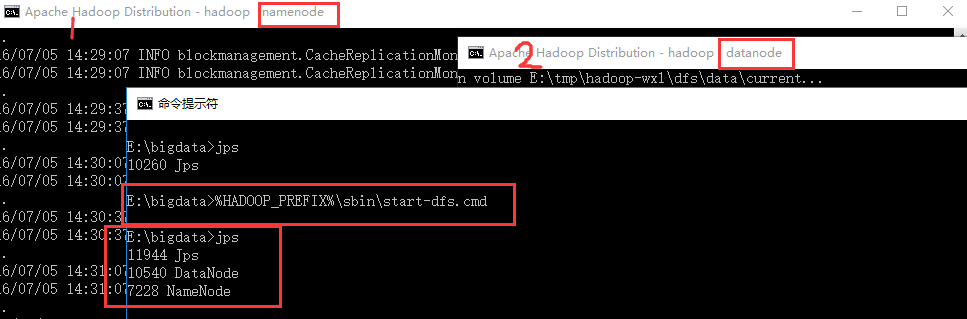
3.4 启动namenode和datanode
%HADOOP_PREFIX%\sbin\start-dfs.cmd会弹出两个cmd窗口,分别是datanode和namenode。 查看是否启动成功,在原先窗口输入jps查看,如图。
3.5 运行hdfs命令,上传一个文件 在当前cmd目录下,如bigdata下创建一个myfile.text文件 执行
%HADOOP_PREFIX%\bin\hdfs dfs -put myfile.txt /查看上传的文件信息执行
%HADOOP_PREFIX%\bin\hdfs dfs -ls /
4. Hadoop YARN
4.1 启动YARN
%HADOOP_PREFIX%\sbin\start-yarn.cmd输入jps命令可查看当前启动的节点,如图

4.2 运行一个小例子world count
%HADOOP_PREFIX%\bin\yarn jar %HADOOP_PREFIX%\share\hadoop\mapreduce\hadoop-mapreduce-examples-2.6.4.jar wordcount /myfile.txt /out4.3 web端查看Hadoop作业http://localhost:8088/cluster

5. 结束Hadoop
%HADOOP_PREFIX%\sbin\stop-yarn.cmd
%HADOOP_PREFIX%\sbin\stop-dfs.cmd6. 遇到问题请看下面解决方案,坑都在这里了:
6.1 . 运行以下命令出错
mvn package -Pdist,native-win -DskipTests -Dtar[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (pre-dist) on project hadoop-project-dist: An Ant BuildException has occured: Execute failed: java.io.IOException: Cannot run program “sh” (in directory “E:\bigdata\hadoop\hadoop-project-dist\target”): CreateProcess error=2, 系统找不到指定的文件。
6.2 ‘-Xmx512m’ is not recognized as an internal or external command
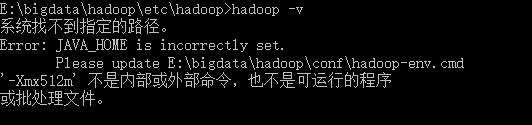
给出stackoverflow上大神的解决方法
6.3 . 节点启动失败
org.apache.hadoop.io.nativeio.NativeIO Windows.acce
解决: 下载Hadoop2.6.4 bin编译的包,并且复制到Hadoop目录的bin目录下。
 官方wiki解决方案
官方wiki解决方案
6.4 . 运行worldcount出错
Application application_1467703817455_0002 failed 2 times due to AM Container for appattempt_1467703817455_0002_000002 exited with exitCode: -1000 For more detailed output, check application tracking page:http://DESKTOP-KV0K24Q:8088/proxy/application_1467703817455_0002/Then, click on links to logs of each attempt. Diagnostics: Failed to setup local dir /tmp/hadoop-wxl/nm-local-dir, which was marked as good. Failing this attempt. Failing the application.
log_Failed while trying to construct the redirect url to the log server.png
解决方案:权限问题
Mapreduce error: Failed to setup local dir
解决:给出stackoverflow解决方案