Deep Dive1- Oracle DB

应一些极客朋友们要求,我们穿插一些更接地气技术文章,毕竟大多数传统非互联网公司还是使用目前较为传统的技术。暂且称这种为Deep Dive经典系列.
1. 饮水思源-创始人
曾几何时,Oracle可是我们这些老胳膊老腿的必备技能,没有啃过几本高级
Oracle开发指南,没读过官方指南,哪敢出门啊。不知在当今互联网+DT时代,廉颇老矣,尚能饭否?放心,我们最后上一个DT时代的Oracle.
既然定为经典回顾,我们先上Oracle的创始人。
从左到右依次为:Ed Oates, Bruce Scott, Bob Miner, Larry Ellison.最右边的Larry也就是我们熟知的拉里·埃里森。
来一张成名后的图:

Larry是霸气的商界奇才,其一生的目标是“财富榜超越Bill Gates”.
Larry算是大气晚成,在其32岁时依然一事无成,工作,生活皆不如意,甚至还未获得大学文聘,尽管读了3所大学。然而其后事业却如日中天,创立了Oracle,并传奇性的令其业绩连续12年每年翻一番,其商业才能令业界刮目,连当年Jobs重返Apple都邀请Larry加入董事会助力。想到当年的一个笑话,一家公司同时邀请Oracle与Sun开会,Oracle各个西装革履,Sun要么教授气息,要么工程师特点T-Shirt,呵呵,Oracle不赢都难。
2. 系统架构
2.1 关系数据库3范式
提及RDBMS怎能不提及数据库范式,多少90后的同学/互联网同学还知道啊?关系数据库有6种范式,普通只要满足3种范式即可。
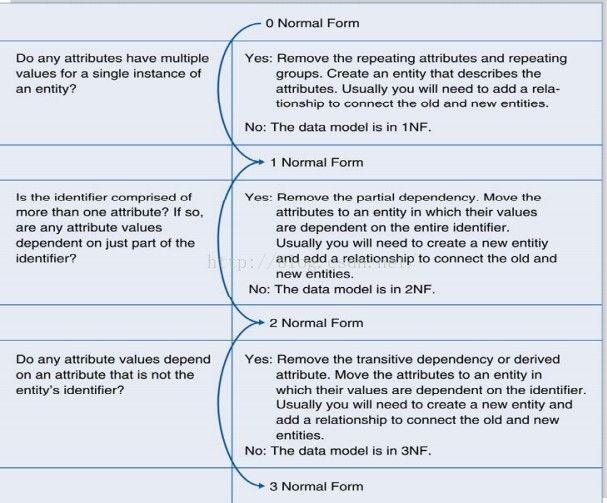
第一范式1NF:最基本范式,确保每列原子性,即每个字段都是不可分分解的原子值, 如列‘联系信息’,包含了电话号码,邮件地址。即违反了第一范式。
第二范式2NF:在第一范式基础上,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。 如表包含订单号,商品编号,商品名称,商品单价等,订单号+商品编号作为主键,而商品名称,单价仅仅依赖于主键的商品编号,则其违反了第二范式。
第三范式3NF:在第二范式基础上, 每一列必须直接依赖于主键而非间接相关。如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。
以上3个范式主要目的是消除数据冗余,保证数据完整性。2NF与3NF主要区别:2NF非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF非主键列是直接依赖于主键,还是直接依赖于非主键列。
值得注意的是,在关系数据库领域被奉为圣经的范式,在大数据时代,NOSQL数据库则大反其道而行,正所突破创新敢于颠覆固有思想。
2.2 Oracle系统架构
接下来我们进入系统架构:
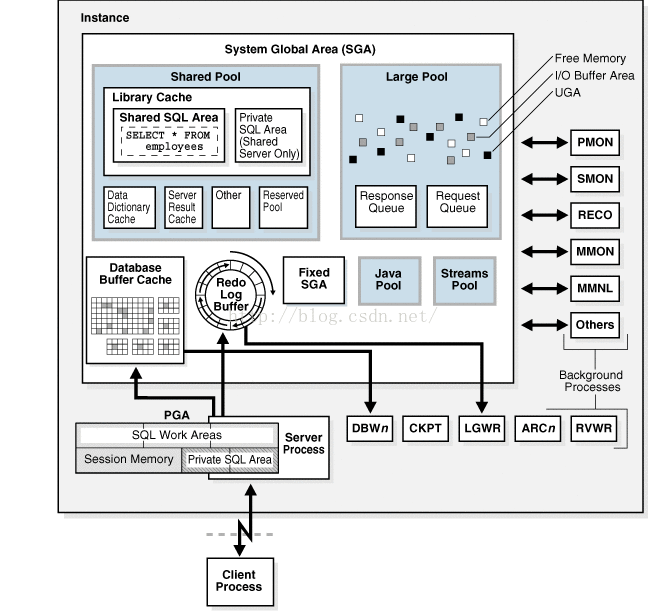
当我们提及Oracle时,通常包含了2个概念:
-
Database
数据库是指一系列的文件,通常保存在磁盘, 用来存储数据。 -
Database Instance
数据库实例则是指数据库运行时内存的结构。
如上图系统架构包含SGA(System Global Area), PGA(Program Global Area)以及后台运行process。
下面我们一一拆解:
SGA(System Global Area) : 系统全局区,官方定义为一片共享读写区,被
oracle所有进程,包括服务进程与后台进程共享。每一个数据库实例都有自己的SGA.
SGA包含了Shared Pool共享池, Buffer Cache缓冲区缓存, Large Pool大型池, Java
Pool, Stream Pool, PGA(Process Global Area)等.
-
Shared Pool: 共享池用来缓存最近被执行的sql,语句以及最近使用的数据定义;包括Library Cache(共享sql),用来存放sql命令;与Data Dictionary Cache(数据字典缓冲),用来存放数据库运行的动态信息。共享池会在所有会话session中共享可见。当执行一个sql时,oracle会首先检查共享池是否有此sql;Server Result Cache: 缓存了sql返还结果,以及pl/sql的函数返回结果。
-
Fixed SGA: 固定SGA, 官网称其为内部housekeeping ,包含了数据以及实例的状态,锁,以及其他SGA区地址索引区。
-
Redo Log Buffer: 一个循环的,用于缓冲写到在线重做日志的数据;Online Redo Log是为确保已经提交的事务不会丢失的机制,如当crash时,可以恢复数据。
-
Database Buffer Cache: 缓冲区缓存用于缓存从数据文件中检索出来的数据块,从而大大提高查询与更新数据的性能。
-
Large Pool: 名字叫“大池”?不知道怎么翻译,用于大块内存分配。v8.0中引入,主要针对大块内存分配,但与共享池缓存管理内存不同之处在于,大内存对象使用后立即释放。
-
Java Pool:在数据库运行java时使用。如编写java存储过程。
-
Stream Pool: 9i后增加的流技术,用来共享,复制数据工具。10g后加入流池。
-
PGA:Process Global Area 为每个连接session保留内存。
可以通过sql查看各个区间大小:
select pool ,sum(bytes) bytes from v$sgastat group by pool;
2.3 存储结构
Oracle的存储结构分为物理,逻辑存储结构(Table, View, Index),这样设计的原因是为了解耦,做到物理实际存储与逻辑存储不影响,如修改数据文件名字不影响table名字等。
2.3.1 物理存储结构
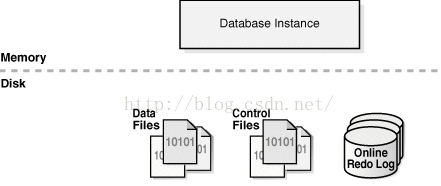
-
Data File:保存在磁盘的物理文件,包含了table,index等数据结构。后缀为.dbf, 一个表空间对应多个数据文件,一个数据文件对应一个表空间。
SQL> DESCDBA_DATA_FILES;
-
Control File: 存储实例,数据文件与日志文件等信息的二进制文件。用于记录整个数据库的状态以及物理结构。如,数据名,创建时间,数据文件名字与位置,redo log名字位置,checkpoint等。
SQL> DESCV$DATAFILE;
-
Online Redo Log: 在线重做日志,就是日志,记录用户对数据库的所有操作信息。用来保障数据库的安全,也可以实现数据备份与恢复。
SQL>SELECT GROUP#,MEMBERS,STATUS FROM V$LOG;
2.3.2 逻辑存储结构
逻辑存储包括表空间,段,区和数据段等组成,面向用户的。
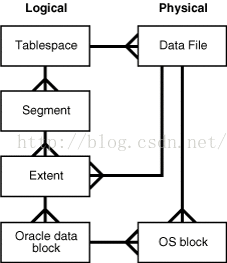
-
Tablespace: 表空间是最大逻辑存储结构,一个数据库对应多个表空间,一个表空间对应一个或多个数据文件;这样做可以提高数据访问性能,另外方便数据管理,备份,恢复等。表空间又划分为系统表空间与非系统表空间(撤销表空间,临时表空间,用户表空间)。
-
Segment: 一个段跨越多个数据文件,属于一个表空间。一个段由多个extent组成。
-
Extent:区由连续的数据块data block组成,多个区构成段。
-
Data Block: 数据块是数据存取的最小单位。
3. 数据库索引
Index是一种在表上可选的数据结构,在一定条件下可以加快查询速度,减少系统磁盘I/O. 针对于heap-organized表,如果没有index,数据库通常会执行全表扫描查询。Index在逻辑上,物理上都独立于数据。
索引类型:
-
B-Tree索引:B-树索引,Balanced Tree平衡树当年数据结构学过。最常用或者默认create index索引,又分为正常以及倒序索引。主要适用于主键或者highly-selective(该列又很多不同值)。当所选取数据小于10%,性能较佳。B-Tree基于二叉树,由分支块branch与叶块leaf组成。
Branch Blocks主要用来搜索,Leaf Blocks存储了数据。branch level为树的高度-1.
-
Bitmap Indexes: 位图索引, 位图索引适用于一些极其有限选择数据的列,如性别,月份等。通常只有对表中多个值相对较小的多个列都适用位图索引才有用,否则还是需要全表扫描。如,对于性别,每次搜索都会返回一半记录。这些索引更适合数据仓库,换言之更新不频繁,否则效率不高。
-
Bitmap Join Index:位图连接索引,这些索引将位图化的列从表数据中抽取出来,并将其存储在索引中。
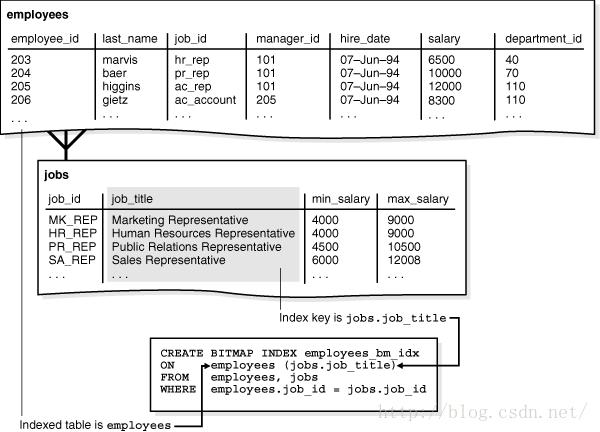
-
Function-Based Indexes: 基于函数的索引,指索引中的一列或者多列是一个函数或者表达式,索引根据函数或表达式计算索引列的值。
如基于下面表达式:
-
CREATE INDEX emp_total_sal_idx ON employees (12 * salary * commission_pct, salary, commission_pct);如基于函数:
-
CREATE INDEX emp_fname_uppercase_idx ON employees ( UPPER(first_name) ); -
Cluster Index: 簇索引,聚簇是根据码值找到数据的物理存储位置,从而达到快速检索数据的目的。聚簇索引的顺序就是数据的物理存储顺序,叶节点就是数据节点。非聚簇索引的顺序与数据物理排列顺序无关,叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。一个表最多只能有一个聚簇索引。 但是建立聚簇索引的空间耗费比较大 对以后的增加删除的影响比较大,所以要在有必要的情况下用. 也就是说聚族索引的组织顺序和数据本身的组织顺序是一致的
-
Application Domain Indexes:域索引,为用户自定义数据类型创建用户定义索引类型。
-
HASH索引:HASH索引必须建立HASH集群。
Oracle还提供其他一些索引,如二进制对象CLOB, 创建索引Oracle TEXT.
4. 数据并发控制
数据库的并发与事务是RDBMS的核心。
4.1 Transaction事务控制
数据库中的事务是工作的逻辑单元,一个事务由一个或者多组相关sql组成, 通过一定的事务机制来确保这一组DML(Insert/Update/Delete)的操作要么全部成功过执行,要么一点也不执行,目的是确保数据的完整性。
讲到事务不得不提著名的作为RDBMS理论基石的ACID,
4.2 ACID:
-
Atomicity原子性: 即上文提到的所有操作要么全做,要么不做,保证数据完整性。如两张银行转账,从a卡转出,从b卡转入。
-
Consistency一致性:指数据库在事务操作前和事务处理后, 数据必须满足业务规则约束。
-
Isolation隔离性:指数据库允许并发的事务同时对其中的数据进行读写,隔离性可以防止多个事务的并发执行冲突,以及命令交叉执行导致数据不一致。
-
Durability持久性:指事务处理之后,对数据的修改应该是永久的,包括系统遇到故障情况下,数据也不能丢失。
再提一下注明的CAP理论,作为NOSQL的基石,NOSQL主要重视性能与扩展,非事务。
4.3 CAP原则
任何分布式系统/数据库最多可以保证以下三个属性的两个,三者不可兼得:
-
Consistency 一致性:在分布式系统中所有数据备份,在同一时刻是否同样的值;即所有数据变动都是同步的。
-
Avaiability 可用性:系统始终保持可用状态,支持多点,集群。
-
Partition Tolerance: 分区容错:系统在出现网络Partition的时候仍然可以操作;即是否能够有效处理节点间的通信故障。
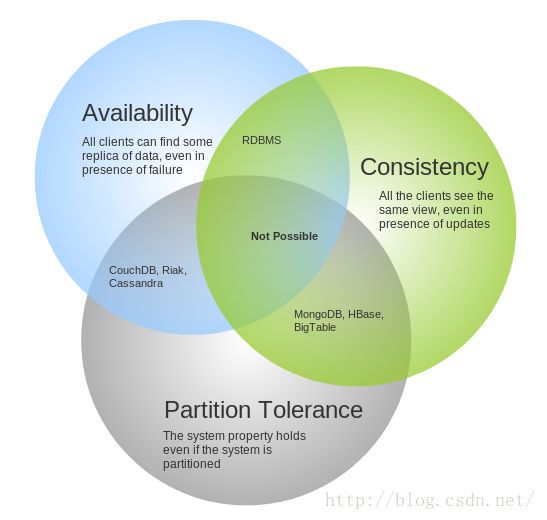
4.4 事务隔离级别
-
Read Uncomitted:脏读,事务读取了另外一个没有提交的事务数据,脏数据。
-
Read Committed: 提交读,允许其他事务修改当前事务所读取数据,当那个事务提交后,当前事务可以看到修改后的数据。
-
Repeatable Read:可重复读,一个事务所读取数据记录不允许被其他事务修改。
-
Serializable:序列化,最高隔离级别,所有事务都是一个接一个,事务以串行方式执行,不会发生失误冲突问题。
4.5 锁
当事务对某个数据操作前,先向系统发出请求,对其加锁;在该事务释放锁之前,其他事务不能对此数据进行更新操作。几本锁类型:排它锁(X)和共享锁(S)。当数据被加上排它锁时,其他事务对它不能读取和修改。加了共享锁的数据对象可以被其他事务读区,但不能修改。
oracle分为latch类型锁用来保护内存结构以及lock锁用来保护数据,索引等。
Oracle提供了如下几种lock锁:
-
DML Locks:主要用来保护数据, 如表锁锁住整个表,行锁锁住选择出来的行。
-
DDL Locks: 保护schema的结构等数据库结构完整,如数据字典中表,试图的定义。
-
System Locks:保护内部数据库结构,如data files, latches, mutexes etc.
DML锁包括TM表锁TX事务级锁或行锁。
-
Table Locks(TM)表锁: 确保在修改表内容时,表的结构不会改变;表锁又细分为如下几种模式:
-
Row Locks(TX) 行锁,当使用dml中的insert,update,delete, select ... for update等。
事务发起第一个修改时会得到事务锁/行锁,而且会一直持有这个锁,直至事务提交或回滚。TX锁使用排队机制。
当Oracle执行DML语句时,系统自动在所要操作的表上申请TM类型的锁。当TM锁获得后,系统再自动申请TX类型的锁,并将实际锁定的数据行的锁标志位进行置位,包含如上6种。
5. SQL
SQL不多讲了,上一个sql处理流程吧:
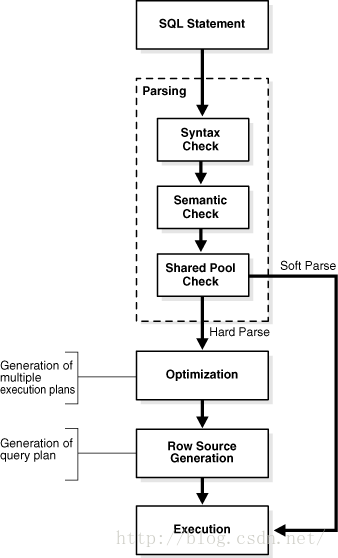
当访问表获取数据时可能会涉及如下path:
-
Full table scans: 全表扫描
-
Rowid scans:rowid扫描
-
Index scans:使用索引扫描数据
-
Cluster scans:使用cluster index扫描数据
-
Hash scans:使用hash cluster扫描
可以看出,这里与我们上面介绍的索引有密切关联。
好了,时间关系,我们的介绍先到这里,主要涉及一些oracle的基本原理性的概念,蜻蜓点水。
最后上一个Oracle 12c的一个roadmap作为结束。
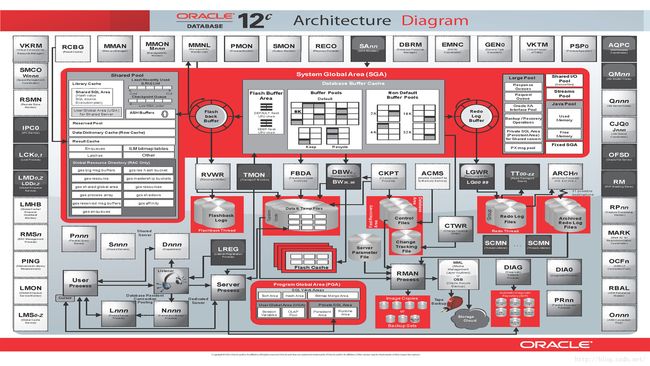
Oracle Database Administrator's Guid 11g Release 2.
Oracle Database SQL Language Reference.
Oracle Database Reference 11g Release.
http://docs.oracle.com/en/database/database.html
公众号:技术极客TechBooster