Oracle架构实现原理、含五大进程解析(图文详解)
目录
- 目录
- 前言
- Oracle RDBMS架构图
- 内存结构
- 系统全局区SGA
- 高速缓存缓冲区数据库缓冲区
- 日志缓冲区
- 共享池
- 其他结构
- 进程结构
- 用户连接进程
- 用户进程User Process
- Server Process服务进程
- 程序全局区PGA
- Oracle的connect连接和session会话与User Process紧密相关
- 后台进程
- 数据库写入进程DBWn
- 检查点CKPT
- 进程监视进程PMON
- 系统监视进程SMON
- 重做日志文件和日志写入进程
- 归档进程ARCn
- 用户连接进程
- 存储结构
- 物理结构
- Data Files
- Redo Log Files
- Control Files
- Parameter File
- Password File
- 逻辑结构
- 逻辑空间到物理空间的映射
- 物理结构
- 执行一条写入的SQL语句时在RDBMS中都发生了什么
- 最后
前言
Oracle架构,讲述了Oracle RDBMS的底层实现原理,是Oracle DBA**调优和排错的基础理论。深入理解Oracle架构,能够让我们在Oracle的路上走的更远。本文主要是在对RDBMS的底层组件功能和实现原理有一定的了解的情况下,结合自身的工作经验提出了对Oracle调优和排错的思路。**当然,对Oracle体系结构的理解是一个深远的过程,需要不断的更新修改,如有不对,还望指正。:)
Oracle RDBMS架构图
一般我们所说的Oracle指的是Oracle RDBMS(Relational databases Management system),一套Oracle数据库管理系统,也称之为Oracle Server。而Oracle Server主要有两大部分:
Oracle Server = 实例 + 数据库 (Instance和Database是相互独立的)
- 数据库 = 数据文件 + 控制文件 +日志文件
- 实例 = 内存池 + 后台进程
所以可以细分为: Oracle Server = 内存池 + 后台进程 + 数据文件 + 控制文件 + 日志文件
一台Oracle Server支持创建多个Database,而且每个Datacase是互相隔离而独立的。不同的Database拥有属于自己的全套相关文件,例如:有各自的密码文件,参数文件,数据文件,控制文件和日志文件。
Database由一些物理文件(如:存放在存储设备中的二维表文件)组成。二维表存储在Database中,但Database的内容不能被用户直接读取,用户必须通过Oracle instance才能够访问Database,一个Instance只能连接一个Database,但是一个Database可以被多个Instance连接。
将上面的Oracle RDBMS架构图进行抽象分类,可以将Oracle架构抽象为:Oracle体系 = 内存结构 + 进程结构 + 存储结构
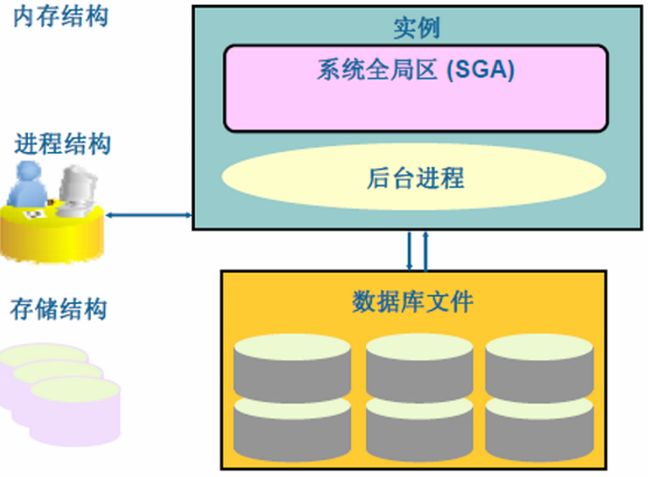
内存结构
Oracle Instance是Oracle RDBMS的核心之一,负责RDBMS的管理功能。Oracle Instance主要由内存池SGA和后台进程组成。
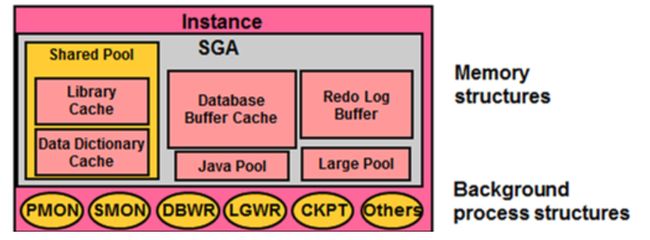
系统全局区SGA
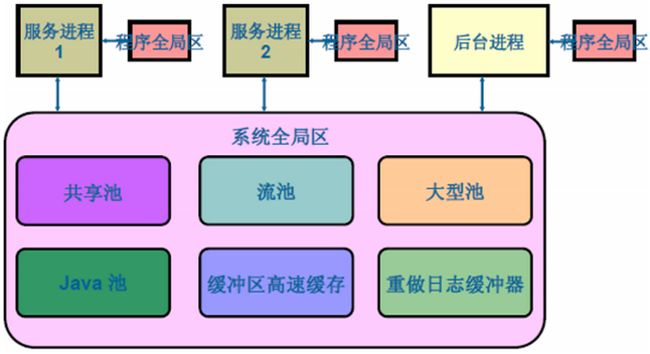
内存池SGA的默认Size,会在安装Oracle的时候会根据LinuxOS的sysctl.conf参数文件来决定:
kernel.shmall = 2097152
kernel.shmmax = 2147483648
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default = 1048576
net.core.rmem_max = 1048576
net.core.wmem_default = 262144
net.core.wmem_max = 262144查看SGA的Size:
SQL> conn /as sysdba
Connected.
SQL> show user;
USER is "SYS"
SQL> select * from v$sga;
NAME VALUE
-------------------- ----------
Fixed Size 2022144
Variable Size 503317760
Database Buffers 1627389952
Redo Buffers 14753792
SQL> show sga
Total System Global Area 2147483648 bytes #对应kernel.shmmax = 2147483648
Fixed Size 2022144 bytes
Variable Size 503317760 bytes
Database Buffers 1627389952 bytes
Redo Buffers 14753792 bytesSGA(System Global Area)是与Oracle性能关系最大的核心部分,也是对Oracle进行调优的主要考量。SGA内存池会在Instance启动时被分配,在Instance关闭时被释放。在一定范围内,SGA可以在Instance运行时通过自动方式响应DBA的指令。如果想对SGA进行调优还必须理解SGA所包含如下几种数据结构:
高速缓存缓冲区(数据库缓冲区)
数据库缓冲区是oracle执行SQL语句的区域。
例如在更新数据时,用户执行的SQL语句不会直接对磁盘上的数据文件进行更改操作,而是首先将数据文件复制到数据库缓冲区缓存(就是说数据库缓冲区里会存放着SQL相关数据文件副本),再更改应用于数据库缓冲区缓存中这些数据块的副本。而且数据块副本将在缓存中保留一段时间,直至其占用的缓冲区被另一个数据库覆盖为止(缓冲区Size有限)。
在查询数据时,为了提高执行效率,查询的数据也要经过缓存。建立的Session会计算出那些数据块包含关键的行,并将它们复制到数据库缓冲区中进行缓存。此后,相关关键行会传输到Session的PGA作进一步处理。这些数据块也会在数据库缓存区缓存中保留一段时间。
一般情况下,被频繁访问的数据块会存在于数据库缓冲区缓存中,从而最大程度地减少对磁盘I/O的需要。
那什么时候会将被更新的数据块副本写入到磁盘中的数据文件呢?
答案就是:如果在缓冲区缓存中存储的数据块与磁盘上的数据块不同时,那么这样的缓冲区常称为”脏缓冲区”,脏缓冲区中的数据块副本就必须写回到磁盘的数据文件中。
调优:数据库缓冲区缓存的大小会对性能产生至关重要的影响,具体需要多大的Size才能成为最佳配比还要结合实际的生产环境而言。总体而言可以依据以下两点基本要求来判断:
1. 缓存应足够大,以便能缓存所有被频繁访问的数据块。如果缓存过小,那么将导致磁盘I/0活动过多,因为频繁访问的数据块持续从磁盘读取,并由其他数据块使用和重写,然后再从磁盘读取。
2. 但也不能太大,以至于它会将极少被访问的块也一并加入到缓存中,这样会增长在缓存中搜索的时间。
数据库缓冲区缓存在Instance启动时被分配。从数据库9i开始,可以随时将其调大或调小。可以采用手动方式重调,也可以根据工作负荷自动重调大小(事务)。
修改缓冲区DB_CACHE_SIZE地方法:
#Step1. 查看SGA的大小:因为DB_CACHE_SIZE的size受SGA的影响
SQL> show parameter sga_max_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 2G
#Step2. 查看show parameter shared_pool_size的大小
SQL> show parameter shared_pool_size; NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 0
#Step3. 计算DB_CACHE_SIZE的大小:shared_pool_size + db_cache_size = SGA_MAX_SIZE * 70%
#Step4. 修改DB_CACHE_SIZE的大小
SQL> alter system set db_cache_size=1433M scope=spfile sid='demo';
System altered.
SQL> conn sys /as sysdba
Enter password: ********
Connected.
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 2147483648 bytes
Fixed Size 2022144 bytes
Variable Size 503317760 bytes
Database Buffers 1627389952 bytes
Redo Buffers 14753792 bytes
Database mounted.
Database opened.
SQL> show parameter db_cache_size日志缓冲区
日志缓冲区是小型的、用于短期存储将写入到磁盘上的重做日志的变更向量的临时区域。主要作用是提供更加快的日志处理效率。
共享池
共享池的大小也对性能产生重要影响
1. 它应该足够大,以便缓存所有频繁执行的代码和频繁访问的对象定义。如果共享池过小,则性能下降,因为服务器会话将反复抢夺其中的空间来分析语句,此后,这些语句会被其他语句重写,在重新执行时,将不得不再次分析。如果共享池小于最优容量,则性能将下降。但有一个最小容量,如果低于此限度,则语句将失败。
2. 但也不能过大,以至于连仅执行一次的语句也要缓存。过大的共享池也会对性能产生不良影响,因为搜索需要的时间过长。
确定最优容量是一个性能调整问题,大多数数据库都需要一个数百MB的共享池。有些应用程序需要1GB以上的共享池,但很少有应用程序能够在共享池小于100MB时充分运行。共享池内有下列三种数据结构:
- 库缓冲:存储最近执行的代码
- 数据字典缓存:存储最近使用的对象定义
- PL/SQL缓冲区:存储的PL/SQL对象是过程、函数、打包的过程、打包的函数、对象类型定义和触发器。
手动的调整共享池的大小:
select COMPONENT,CURRENT_SIZE,MIN_SIZE,MAX_SIZE from v$sga_dynamic_components; //显示可以动态重设大小的SGA组件的当前最大和最小容量
ALTER SYSTEM SET SHARED_POOL_SIZE = 110M;其他结构
这里暂时不做详细介绍。
大型池
主要用途是供共享的服务器进程使用。
JAVA池
只有当应用程序需要在数据库中运行java存储程序时,才需要java池。
进程结构
进程结构主要有后台进程和用户连接进程两大类。
用户连接进程
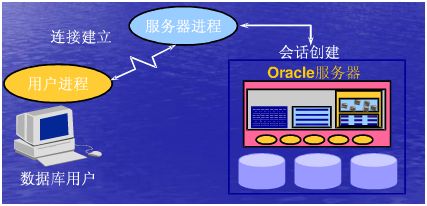
用户连接进程是连接用户和Oracle Instance的桥梁。只有在User与Instance建立了连接以后,User才能够对Oracle Server进行操作。
用户连接进程 = 用户进程 + 服务进程 + PGA
用户进程User Process
当一个Database User请求连接到Oracle Server时,Oracle Server会创建User Process。
User Process的作用:
- 为Database User与Server Process建立连接
- 并不会直接与Oracle Server交互
connect连接:是User和Server Process之间的通信通道。
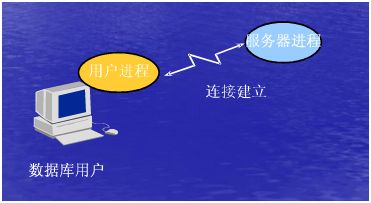
Server Process服务进程
用于处理Database User和Oracle Server之间的连接。
当一个User与User Process建立了一个connect后,Oracle Server会创建一个Server Process。然后再由User Process与Server Process建立了连接之后,Server Process会通过用户提交的请求信息来确定与oracle instance建立一个会话。
Server Process的作用:
- 与Oracle Server直接交互
- 复制执行和返回结果
Session会话:一个用户通过User Process(本质是通过Server Process)与Oracle Instance建立连接后称之为一个会话,一个用户可以建立多个会话,即同时使用同一个用户可以多次的连接到同一个实例,也就是说多个session可以使用同一个connect。
程序全局区PGA
PGA:Oracle Server Process分配来专门用于当前User Session的内存区。该区域是私有的,不同的用户拥有不同的PGA。
PGA包含了Server Process数据和控制信息的内存区域。,由下列3个部分组成:
1. 栈空间:存储Session的变量、数组等的内存空间。
2. Session Info:如果运行的不是多线程服务器,会话信息将保存在PGA中,如果是多线程服务器,则保存在SGA中。
3. 私有SQL区:用来保存绑定变量(binding variables)和运行时缓冲区(runtime buffers)等信息。
Oracle的connect连接和session会话与User Process紧密相关
注意:在RDBMS中由db\_name和instance\_name共同确定一个Database,所以Instance_name被用于Oracle与OS之间的联系同时也被用于Oracle Server与外部连接时使用。
所以在User提交连接请求的时候,User Process首先会与Server Process建立Connect,然后Server Process会通过请求中所包含的db\_name和Instance\_name来确定需要且可以被连接的数据库(RDBMS可以存在多个数据库),这样就确保了RDBMS在拥有多个数据库的情况下,还能够保证每一个Database的独立性。而且同一个Database可以被多个属于这个Databse的不同用户发起的Instance连接。这一个功能是非常有必要的,因为每一个不同的数据库中都包含有同名的sys、system等系统用户。
后台进程
后台进程主要是完成数据库管理任务 ,后台进程是Oracle Instance和Oracle Database的联系纽带,分为核心进程和非核心进程。
1. 核心进程:核心进程,必须存在,有一个终止,所有数据库进程全部终止,实例崩溃!其中五大进程全都是核心进程。
2. 非核心进程:完成数据库的额外功能,非核心进程死亡数据库不会崩溃!
常用的核心进程:
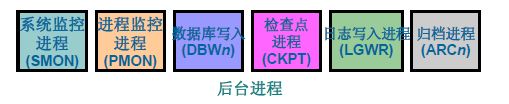
在用户访问数据库时,首先会提交请求,再分配SGA内存,创建并启动后台进程和实例,最后建立连接和会话。Oracle Server运行过程中必须启动上面的前五个进程。否则实例无法创建。
查看后台进程:
SQL> select name,description from v$bgprocess where paddr<>'00';
NAME DESCRIPTION
----- ----------------------------------------------------------------
PMON process cleanup
PSP0 process spawner 0
MMAN Memory Manager
DBW0 db writer process 0
LGWR Redo etc.
CKPT checkpoint
SMON System Monitor Process
RECO distributed recovery
CJQ0 Job Queue Coordinator
QMNC AQ Coordinator
MMON Manageability Monitor Process
NAME DESCRIPTION
----- ----------------------------------------------------------------
MMNL Manageability Monitor Process 2
数据库写入进程(DBWn)

Server process连接Oracle后,通过数据库写进程(DBWn)将数据缓冲区中的“脏缓冲区”的数据块写入到存储结构(数据文件、磁盘文件)
Database writer (DBWn)数据库写进程:
只做一件事,将数据写到磁盘。就是将数据库的变化写入到数据文件。
该进程最多20 个,即使你有36 个CPU 也只能最多有20 个数据库写进程。
进程名称DBW0-DBW9 DBWa-DBWj
注意:数据库写进程越多,写数据的效率越高。该进程的个数应该和cpu的个数对应,如果设置的数据库写进程数大于CPU 的个数也不会有太明显的效果,因为CPU 是分时的。
检查点(CKPT)
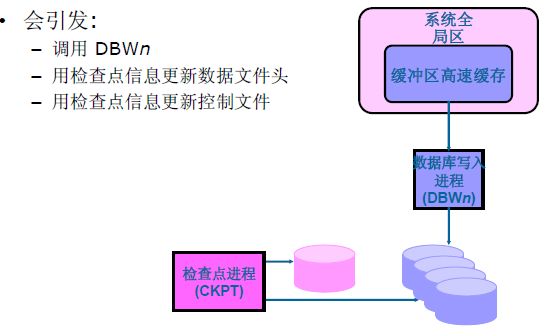
Checkpoint (CKPT)检查点进程:
主要用户更新数据文件头,更新控制文件和触发DBWn数据库写进程。
Ckpt 进程会降低数据库性能,但是提高数据库崩溃时,自我恢复的性能。我们可以理解为阶段性的保存数据,一定的条件满足就触发,执行DBWn存盘操作。
进程监视进程(PMON)

Process monitor (PMON)进程监测进程:
PMON在后台进程执行失败后负责清理数据库缓存和闲置资源,是Oracle的自动维护机制。
- 清除死进程
- 重新启动部分进程(如调度进程)
- 监听的自动注册
- 回滚事务
- 释放锁
- 释放其他资
系统监视进程(SMON)
System monitor (SMON)系统监测进程:
SMON启动后会自动的用于在实例崩溃时进行数据库实例自动恢复。
清除作废的排序临时段,回收整理碎片,合并空闲空间,释放临时段,维护闪回的时间点。
在老数据库版本中,当我们大量删除表的时候,会观测到SMON进程很忙,直到把所有的碎片空间都整理完毕。
重做日志文件和日志写入进程
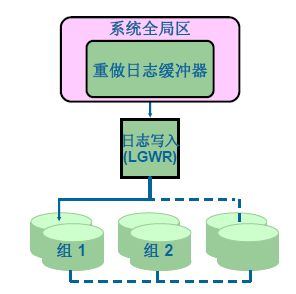
主要用于记录数据库的改变和记录数据库被改变之前的原始状态,所以应当对其作多重备份,用于恢复和排错。
激活LGWR的情况:
- 提交指令
- 日志缓冲区超过1/3
- 每三秒
- 每次DBWn执行之前
归档进程(ARCn)
归档进程(ARCn)是非核心进程。
存储结构
Oracle RDBMS存储结构主要由Database组成。
又能够将Database分为物理结构和逻辑结构来理解。
物理结构
Database物理结构:是Database在操作系统中的文件集合,即:磁盘上的物理文件,主要由数据文件、控制文件、重做日志文件、归档日志文件、参数文件、口令文件组成。
Data Files
数据文件是数据的存储仓库。
• 包括所有的数据库数据
• 只能属于一个数据库
• 来自于被称为”表空间”的数据库存储逻辑单元
• 可以直接被读进内存,在执行SQL语句的时候,会将相关的数据文件副本加载如数据缓冲区。
• 通过备份策略可以使数据文件得到保护
Redo Log Files
重做日志文件包含对数据库所做的更改操作记录,在Oracle发生故障时能够恢复数据。
能够恢复数据的原理:重做日志文件会按时间的顺序,将应用于数据库的一连串的变更向量(做了什么操作)存储起来(即将变更的地方标记起来)。其中包含了所有已经完成操作的信息和完成操作之前的数据库状态。如果数据文件受损,就可以将这些变更向量应用于数据文件备份来进行重做(重建)工作,将它恢复到发生故障的那一刻前的状态。重做日志文件又分为下面两种类型:
- 联机重做日志文件:记录连续的数据库操作
- 归档日志文件Archived Log Files:用于时间点恢复,当RedoLogFiles存满时,会对这些日志进行归档备份,以便以后还原数据时使用。
- 查看redo log info:
SQL> select member from v$logfile; # v$logfile数据字典,记录了redolog文件的列表
MEMBER --------------------------------------------------------------------------------
/u01/oradata/demo/redo03.log
/u01/oradata/demo/redo02.log
/u01/oradata/demo/redo01.logControl Files
控制文件包含维护和验证数据库完整性的必要的信息。
它记录了联机重做日志文件、数据文件的位置、更新的归档日志文件的位置。它还存储着维护数据库完整性所需的信息,如数据库名。控制文件是以二进制型式存储的,用户无法修改控制文件的内容。控制文件不过数MB,却起着至关重要的作用。
Parameter File
实例参数文件,当启动oracle实例时,SGA结构会根据此参数文件的设置内存,后台进程会据此启动。
Password File
用户通过提交username/password来建立会话,Oracle根据存储在数据字典的用户定义对用户名和口令进行验证。
逻辑结构
表空间就是典型的Oracle逻辑结构类型 —— 里面存放着若干的数据文件
表空间:用于存储数据库对象的逻辑空间,表空间是在数据库中开辟的一个空间,用于存放数据库的对象,它是信息存储的最大逻辑单位,是存放数据库文件的地方,其中数据又被存放在表空间中的数据文件中。一个数据库可以由多个表空间组成,Oracle的调优就是通过表空间来实现的。(Oracle数据库独特的高级应用)
表空间的作用:分类管理、批量处理; 将琐碎的磁盘文件整合、抽象处理成为逻辑结构。这样更加便于我们去管理数据库。
逻辑空间到物理空间的映射
段、区和块:
执行一条写入的SQL语句时在RDBMS中都发生了什么
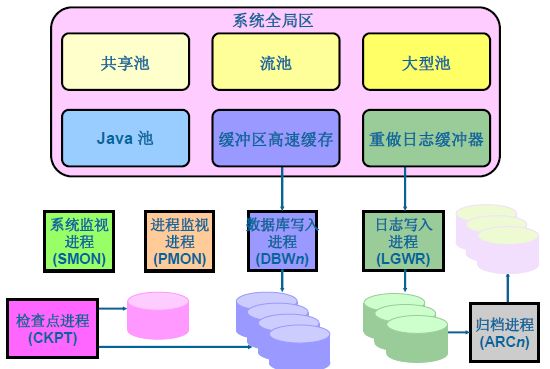
1. 将SQL语句加载入数据库缓冲区
2. 将SQL语句要操作的数据文件副本加载入数据库缓冲区
3. 执行SQL语句,修改数据文件副本,形成“脏缓冲区”
4. CKPT检测到“脏缓冲区”,调用DBWn
5. 在DBWn运行之前,先运行了LGWR,将数据文件的原始状态和数据库的改变记录到Redo Log Files
6. 运行DBWn,将“脏缓冲区的内容写入到数据文件”
7. 同时CKPT修改控制文件和数据文件头
8. SMON回收不必要的空闲资源
最后
最后我们举个例子来看看Oracle RDBMS是怎么运作的
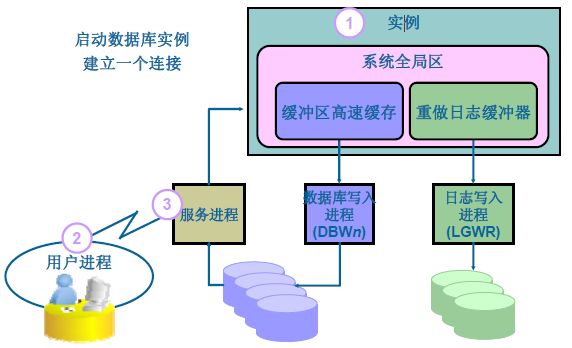
- User访问Oracle Server之前提交一个请求(包含了db_name、instance_name、username、password等信息),Oracle Server接收到请求并通过Password File的验证后,分配SGA内存池,启动后台进程同时创建并启动实例。
- 在启动实例之后User Process与Server Process建立Connect。
- 再通过Server process和Oracle Instance完成建立Sesscion。
- 用户执行SQL语句,由server process接收到并直接与Oracle交互。
- SQL语句通过Server Process到达Oracle Instance,再将SQL载入数据库缓冲区。
- Server Process通知Oracle Database将与SQL语句相关的数据块副本加载到缓冲区中。
- 在数据库缓存区执行SQL语句,并产生”脏缓冲区”。
- 由CKPT检查点进程检查到”脏缓冲区”,并调用DBWn数据库写进程,但在DBWn执行之前,应该由LGWR先将数据文件的原始状态、数据库的改变等信息记录到Redo Log Files。
- 将更新的内容写入到磁盘中的数据文件。
- 返回结果给用户