Java性能优化指南系列(二):Java 性能分析工具
进行JAVA程序性能分析的时候,我们一般都会使用各种不同的工具。它们大部分都是可视化的,使得我们可以直观地看到应用程序的内部和运行环境到底执行了什么操作,所以性能分析(性能调优)是依赖于工具的。在第2章,我强调了基于数据驱动的性能测试是非常重要的,我们必须测试应用的性能并理解每个指标的含义。性能分析和数据驱动非常类似,为了提升应用程序的性能,我们必须获取应用运行的相关数据。如何获取这些数据并理解它们是本章的主题。【本章重点介绍JDK中提供的性能分析工具】
操作系统工具及其分析
- 程序分析的起点并不是和Java相关的,而是和操作系统相关。在基于Unix的操作系统上,和性能分析相关的工具都来自于sar(System Accounting Report),它包括:vmstat, iostat, prstat等等。
- 在进行性能测试的时候,操作系统的相关数据必须要收集起来。这些数据至少包括:CPU,内存以及硬盘使用率。如果程序使用了网络,网络使用率等相关信息也要收集起来。
CPU使用率
- CPU使用率可以分为两部分:用户时间和系统时间。这里要注意:系统时间也是和应用相关的,比如:应用使用网络传输数据,内核将会执行网络模块的代码来获取数据并将数据拷贝到内核缓冲区;如果应用启动了很多线程,线程调度也会占用系统时间。
- 性能测试的目标是在最短的时间内让CPU越高越好。这个听起来和直觉可能有点相反,为什么要让CPU达到100%啊。那就让我们理解下CPU使用率的含义是什么?
- 首先我们要记住:CPU使用率是一段时间内的平均值,这段时间可能是5秒,30秒,甚至是1秒(不可能小于1秒)。下面我就来解释为什么CPU使用率越高越好?假设一个程序在10分钟的运行过程中,CPU使用率(注意:一段时间的平均值)为50%。如果我们调优了代码,CPU使用率达到了100%,那么程序的性能就提升了1倍,因为它将会在5分钟左右完成所有工作。如果性能又提升了一倍,程序将会在100% CPU使用率的情况下,2.5分钟左右完成所有工作。CPU使用率表示的是程序使用CPU的效率,因此是越高越好(当然要排除异常情况)。
- 如果我们运行vmstat 1(每1秒运行1次),在Linux环境下将会产生类似下面的结果:
% vmstat 1
procs -----------memory---------- ---swap-------io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy idwa
2 0 0 1797836 1229068 1508276 0 0 0 9 2250 3634 41 355 0
2 0 0 1801772 1229076 1508284 0 0 0 8 2304 3683 43 354 0
1 0 0 1813552 1229084 1508284 0 0 3 22 2354 3896 423 55 0
1 0 0 1819628 1229092 1508292 0 0 0 84 2418 3998 432 55 0
上图说明,在1秒内,有450ms CPU是忙的(42%用于执行用户代码,3%用于执行系统代码);其它550ms CPU都是空闲的,CPU空闲可能有以下原因:
- 应用阻塞在同步器上,不能执行直到锁被释放
- 应用在等待一个事情,比如:数据库的响应
- 应用没什么事情可做
- 上面3种情况的前2个是我们要关注的,如果能减少锁竞争,或数据能够更快地发送响应,程序将会运行的更快,应用的CPU使用率就会上升(当然,这里假设没有其它方面会阻塞应用)
上面的第3点常常会带来疑惑,如果应用有事情可做,CPU会执行程序的代码。这个是基本的原则,不仅仅准对Java。比如:我们写了一个Windows下的脚本,就是简单的无限循环,如果执行它,CPU立马就100%了,

如果CPU没有达到100%呢,那么就意味着操作系统还有其它一些事情要做(比如:上例中的打印LOOPING),但是却选择了idle。CPU是idle状态对于应用是没有好处的,如果我们运行的是计算密集型的应用,CPU是idle的,意味着我们需要使用更长时间得到结果。
- 如果你在单核CPU上面运行这个命令,你应该很难看到CPU会空闲;但是如果你尝试启动一个新的程序或测试另外一个应用的性能,你就可以看到效果了。操作系统非常擅长时间片程序,它让这些程序来竞争CPU周期。不过对于刚刚创建的程序,得到CPU的可能性比较小,因此它会比正常运行的情况下稍慢些。这个经验会让大家认为空出一些CPU周期是一个好主意,以便让这些CPU用于处理其它事情上。但是操作系统不知道后续将会发生什么,所以它会执行任何它能做的事情,而不是让CPU idle。
限制一个程序的CPU:当在有CPU周期的时候运行程序会提升程序的性能。但是有时候我们不想要这样,比如:我们在运行SETI@home,它会消耗所有可获取的CPU,如果我们在工作还好,如果我们在上网,写文档或者打游戏,那影响就很明显。为了解决这个问题,一些操作系统的机制可以人为设定程序使用的CPU;程序的优先级也可以让一些后台程序不会在有更高优先级的程序正在运行的时候消耗更多的CPU。
Java和单个CPU使用率
- 上面所说的周期性空闲CPU的含义是什么呢?答案依赖于应用类型。
- 如果应用是计算密集型的,由于它有固定的工作需要完成,你应该看不到idle CPU,因为它一直忙于计算任务。使得CPU利用率变得更高是计算密集型应用的目标,因为这意味着工作完成的更快。如果CPU已经达到了100%,我们还可以采用其它优化方式来让工作完成的更快(也尽量使CPU使用率为100%)。
- 如果应用是web应用,存在idle time的可能性就很大,因为它很有可能无事可做。例如:当处理完了所有请求之后,它基本上就处于空闲状态,直到下一个请求到来。假设服务器上有一个web应用,它每秒处理一个请求,下面是vmstat命令的输出。它使用450ms来处理请求,也就是说CPU有450ms是100%的,其余550ms是0%,CPU的利用率就是45%。
% vmstat 1
procs -----------memory---------- ---swap-------io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy idwa
2 0 0 1797836 1229068 1508276 0 0 0 9 2250 3634 41 355 0
2 0 0 1801772 1229076 1508284 0 0 0 8 2304 3683 43 354 0
1 0 0 1813552 1229084 1508284 0 0 3 22 2354 3896 423 55 0
1 0 0 1819628 1229092 1508292 0 0 0 84 2418 3998 432 55 0
尽管时间粒度很小(只有几百毫秒),但是当负荷很高的时候,从宏观上看CPU的使用率(每0.5s接收一个请求,处理每个请求的平均时间为225ms)是45%(每半秒内,225ms是忙的,275ms是空闲的)。
- 假设我们对应用进行了优化,将每个请求的处理时间缩短到400ms,那么CPU的使用率也会降低到40%,因为请求量没有发生变化,CPU为100%的时间变短了。同时,这个优化也使得我们可以增加系统的负荷,从而提升CPU的利用率。
Java和多CPU使用率
- 上面的例子是假设一个线程运行在一个CPU上,对于多个线程运行在多个CPU上面的情况是一样的。多线程影响CPU使用率的方式很有趣,其中一个例子是在第5章,它显示了多个GC线程对CPU使用率的影响。运行在多核CPU上面的多线程的目标也是尽量使CPU使用率更高(让每个独立的线程不发生阻塞)。
- 在多核多线程CPU的情况下,当CPU是idle的时候,有一点是我们应该关注的:即使有很多请求等待处理,但是CPU也可能是idle的。发生这种情况的原因是应用中没有更多的空闲线程可以用来处理新的请求。典型的情况是,一个拥有固定数目的线程池应用,在上面运行着不同的任务。一个线程在一个时刻只能运行一个任务,如果线程运行的任务阻塞了,那么这个线程就没办法获取另外一个任务进行处理(必须处理完当前任务)。这样就会导致虽然CPU是空闲的,但是没有线程可以用来处理新的请求。
- 如果出现了上面的情况,我们应该要增加线程池的大小,但是不要看到CPU空闲了就增加线程池的大小,这里是为了完成更多的任务,才需要增加线程池的大小。程序不能获取CPU的原因可能有两个---锁或外部资源。在决定采取优化措施之前,弄清楚为什么程序不能获取CPU是很重要的。
- 查看CPU的利用率是对应用进行性能调优的第一步,但它也只是用来确定:应用消耗的CPU资源是否符合预期或代码是否存在锁/外部资源的问题。
CPU RunQueue
- 比如:vmstat输出中的procs部分,r指的就是RunQueue的大小。如果r的大小比CPU的数目还多,那么系统的性能将会开始下降。
[root@localhost ~]# vmstat
procs -----------memory---------- ---swap-------io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 1 5619980 811116 219740 19671656 0 0 164 194 0 0 2 294 1 0
磁盘使用率
- 监控磁盘I/O有两个目标。一是,如果应用磁盘I/O操作比较多,需要及时发现磁盘I/O是否成为性能瓶颈;二是,监控系统是否做了swap操作(此时即使应用的磁盘I/O不多,发生了swap的时候,磁盘I/O也会变得很高)。
- 要确定磁盘I/O是否为系统的瓶颈是比较棘手的,因为它依赖于应用的行为。如果应用对写入磁盘的数据没有进行很好的缓存,磁盘I/O的统计信息会很低;如果应用需要处理的I/O超过了磁盘的最大处理能力,磁盘I/O的统计信息就会很高。这两种情况的应用性能都可以进行提升。
- Linux下使用iostat命令来监控I/O。
[signal@keyuanfenxi02 log]$ iostat-xm 5
Linux2.6.32-431.el6.x86_64 (keyuanfenxi02) 2016年06月10日 _x86_64_ (64 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
23.45 0.00 37.89 0.10 0.00 38.56
Device: rrqm/s wrqm/s r/s w/s rMB/s
sda 0.00 11.60 0.60 24.20 0.02
wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
0.14 13.35 0.15 6.06 5.33 6.08 0.42 1.04
从上面的输出来看,使用率只有1.04%,w_await也只有6.08ms,似乎情况很好;但是系统使用了37.89%的CPU时间用在sys上面,而且每秒写入0.14MB的空间,需要写入24.2次,这个显然是不合理的(也就是上面说的数据没有得到很好缓存的情况)。
- 下面的输出,显然是磁盘的处理能力跟不上应用的I/O请求,I/O使用率为100%,在I/O上等待了47.89%。
iostat-xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
35.05 0.00 7.85 47.89 0.00 9.20
Device: rrqm/s wrqm/s r/s w/s rMB/s
sda 0.00 0.20 1.00 163.40 0.00
wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
81.09 1010.19 142.74 866.47 97.60 871.17 6.08 100.00
- 一般来说,操作系统的swap机制可以有效的利用内存,特别是对交互和GUI应用。但是对于web应用,这么做可能会降低性能,因为web应用使用的内存一般都比较大。更糟糕的是,因为Java Heap的机制,这个机制对于Java进程更加不利。我们将在第5章详细介绍。
- 除了iostat,vmstat也可以用来监控系统是否发生了s(si和so字段)。
网络使用率
- 网络使用率和磁盘使用率基本是一样的,它也依赖于应用的行为。如果应用对网络使用的效率不高,那么带宽使用率会比较低;如果应用发送的速率大于网卡处理的速率,那么网络的带宽使用率会非常高。
- 为了监控网络的速率,可以使用商用的工具,比如:nicstat,iftop等等
Java监控工具
- 为了获取JVM的本身信息,我们就需要Java的监控工具。JDK中提供了多个这样的工具:
- jcmd:用于打印Java进程的基本类、线程和VM信息。它非常适合用于命令行脚本中,可以下面这样进行执行:jcmd process_id command optional_arguments
- jconsole:提供JVM的图形视图,包括:线程、类以及GC
- jhat:读取并分析heap dump文件。这是一个后处理的工具。
- jmap:提供head dump和其它JVM的内存使用其它信息。非常适合在脚本中使用,尽管head dump必须使用后处理工具进行分析。
- jinfo:提供JVM的系统属性查看,并允许对一些属性进行动态设置。适合用户脚本当中。
- jstack:dump出Java进程的堆栈。适合用于脚本当中。
- jstat:提供关于GC和类加载动作的相关信息。适合用于脚本当中。
- jvisualvm:监控JVM的GUI工具,提供对运行应用的概要信息,并分析JVM的堆栈。
基本VM信息
- Uptime:运行的时长,使用命令:jcmd process_id VM.uptime
- System Properties:系统属性,使用命令:jcmd process_id Vm.system_properties 或 jinfo -sysprops process_id
这两个命令打印出的系统变量包括:-D选项变量、动态增加的属性、JVM的默认属性。
- JVM version:JVM的版本,使用命令:jcmd process_id VM.version
- JVM command line:JVM的命令行,jcmd process_id VM.command_line
- JVM tunning flags:JVM的调优参数,使用命令:jcmd process_id VM.flags [-all]
调优参数
- 对于JVM,一般都有几百个调优参数(比如:java 7就有600多个),它们中的绝大多数都是非常不知名的;我们建议这些调优参数中的绝大多数都不要进行修改。在诊断虚拟机性能的时候,搞清楚哪些参数是有效的是一个经常要做的工作。一般来说,我们首先要搞清楚对于特定JVM,在特定平台上的默认值是什么,这时使用在命令行中使用-XX:+PrintFlagsFinal选项就非常有用。
- 为了查看对于特定平台JVM设置了哪些默认值,可以使用下面的命令:
javaother_options -XX:+PrintFlagsFinal -version
...Hundreds of lines of output, including...
uintx InitialHeapSize := 4169431040 {product}
intx InlineSmallCode = 2000 {pd product}
对于其它参数,我们得在命令行给定,因为一些参数会影响其它的参数,特别是设置GC相关的参数。这个命令会打印出所有JVM参数及其值的所有列表。
- 如上面所示,如果是:=的形式,说明参数使用了非默认值。有3个原因会导致这种情况:1)在命令行中指定了这个参数的值 2)其它参数间接地改变了这个参数 3)JVM自己根据系统情况选择了一个非默认值
- 如果是=的形式,表示参数使用了默认值;参数在不同的平台上面的默认值也许是不一样的,这个在最后面一列给出。product表示默认值在所有平台都是一样的;pd product表示默认值是平台相关的。另外一种可能的值是:manageable表示参数值不能在运行时进行动态调整;C2 diagnostic表示参数是为编译器工程师提供诊断信息的,从而弄清楚编译器工作的如何)
- 另外一种查看调优参数的方式是使用jinfo命令。使用jinfo命令的好处是,可以打印出程序在执行过程中被修改了的参数。使用下面的命令:
% jinfo -flags process_id
- 尽管jinfo打印出的信息没有+PrintFlagsFinal的直观,但是jinfo还有其它功能:
- jinfo可以对manageable的参数进行动态关闭和打开,比如:
%jinfo -flag PrintGCDetails process_id
-XX:+PrintGCDetails
% jinfo -flag -PrintGCDetailsprocess_id # turns off PrintGCDetails
% jinfo -flag PrintGCDetails process_id
-XX:-PrintGCDetails
- 但是要记住的是,jinfo可以修改任何参数的值,但是这并不意味着,JVM会对这个修改做出响应。比如:绝大多数影响GC算法的参数都是在启动的时候使用的,使用jinfo来修改这些参数的值,并不会影响JVM的行为。因此,jinfo对参数的修改只适用于标志为manageable的参数。
线程信息
- 使用jstack:
% jstackprocess_id
- 使用jcmd process_id Thread.print
% jcmd process_id Thread.print
类信息
- 可以通过jstat和jconsole来获取类的信息,后续详细描述
GC分析
- 每个监控工具基本都提供了一些GC活动的报告。jconsole显示堆使用情况的图形界面;jcmd允许执行GC操作;jmap可以打印出heap使用的信息或永久带信息或创建heap dump;jstat可以产生很多关于垃圾器的不同视图。
Heap Dump后处理
- 一般我们都使用第三方工具来进行HeadDump的分析,本书将使用Eclipse Analyzer Tool来分析Head Dump。
分析工具
- 分析器是Java性能分析工具集中最重要的工具。这里有很多Java分析器,每个都有自己的优点和缺点,对于采样分析器更是如此。对于同一个应用,一个采样分析器发现的问题和另外一个采样分析器发现的问题很不一样。
- 几乎所有的Java分析器都是使用Java来开发的,在运行的时候,将它们"attaching"到被分析的应用上面,这就意味着,分析器打开了一个到目标应用的套接字。目标应用和分析器工具对目标应用的行为交换信息。
- 这就意味着我们也必须对分析器进行调优。特别是,当被分析的应用非常大,它将会传输大量的数据到分析器上,因此,分析器必须有足够大的heap来处理数据。在运行分析器的时候使用并发GC通常是一个比较好的选择;不恰当的full GC会暂停分析器,从而导致缓存非常多的数据而发生溢出。
采样分析器
- 分析有两种模式:采样模式和侵入模式。采样模式是分析的基础,使用很少的开销。这个很重要,因为分析的一个陷阱就是将分析本身的性能消耗引入到应用当中,从而改变了应用的性能特征。(即使如此,你还是要分析,否则怎么知道程序中的“猫”是否活着呢?)减少分析 的影响可以让分析结果更接近应用运行的真实情况。
- 不幸的是,采样分析会导致很多错误。采样分析的工作原理是:过段时间,定时器会触发一次采样;分析器会分析虚拟机中的每个线程,查看线程正在执行的方法。这个方法会和前一次定时器触发的时候一起进行分析。
- 最经常出现的采样错误是下图所示的错误。线程在执行methodA和methodB之间进行切换,如果采样只在methodB的时候进行触发,那么分析的结果,认为所有时间都是methodB执行,这个结果显然是不正确的。
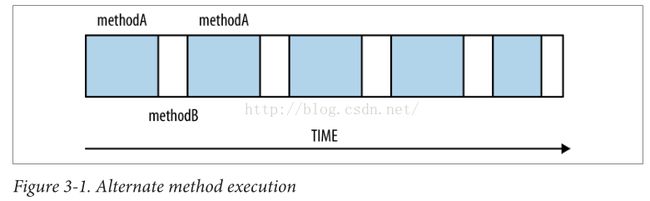
- 上面是采样分析经常出现的问题,但绝不是唯一一个。减小这个错误发生的方式就是分析更长的时间,同时减少采样的间隔时间。减少采样的间隔时间可能会对应用产生影响,从而减少了采样带来的好处,所以时间间隔必须做一个比较好的平衡。每个采样工具解决这个问题的方式是不一样的,所以每个采样工具分析的结果可能是不一样的。
- 下图显示了采样工具对一个GlassFish应用服务器的分析结果。结果显示,19%的时间花在了defineclass1方法上,然后是方法 getPackageSourcesInternal()。

- 需要注意的是:上面的分析结果意味着我们需要提高类加载的性能,而不是提升defineclass1方法的性能。通常我们都会假定需要提升分析结果中排在最前面的方法性能。但是,这么做常常会限制我们提升性能的方式。在上面的例子中,defineclass1方法是JDK的一部分,我们无法修改源码来提升它的性能。假设我们能够重写,并有60%的性能提升,那么整体性能会提升10%左右,那这个还是比较客观的。
- 不过,通过排在最前面的方法一般占用总时间的2%到3%左右,如果性能提升一倍,整体性能也只能提升1%左右。如果我们只关注排在最上面的方法性能,常常不能够得到性能的很大提升。
- 但是,排在最前面的方法常常可以给我们指向性能优化的方向。GlassFish性能工程师不会尝试提升类定义的性能,而是会给出如何加快类加载速度的方案,比如:定义更少的类,并行加载类等等。
侵入式分析器
- 侵入式分析器比采样分析器有很多的侵入性,但是它们能够给出一个程序内部发生的更多信息。下图是侵入式分析器对上面的GlassFish应用服务器的分析结果。
这个分析结果和采样分析器的结果,很显然有些不同了。首先,最耗时的方法变成了“getPackageSourcesInternal()”,它占用了13%的时间,而不是采样分析器重的4%;上面还列出了一些其它耗时的方法,可以看到,defineclass1方法根本没有出现。这个工具还可以显示方法调用的次数,和方法每次执行的平均时间。
- 上面的分析结果就比采样分析器的分析结果要好么?这个是不一定的,在一定情况下,没有方法可以知道那个分析结果是更准确的。侵入式分析器中的方法调用次数时准确的,这个信息对于确定那段代码消耗了更长的时间,哪里更值得优化,是非常有帮助的。比如,在上面的结果中immutableMap.get()方法消耗了12%的时间,但是它的调用次数是4700多万。因此,我们更需要想办法减少这个方法的调用次数,而不是提升这个方法的性能。
- 另外,侵入式分析器是通过在类加载的时候,修改类的字节码序列来工作的(比如:插入计算方法调用次数的代码,等等)。这种方式很有可能会影响原有代码的性能。比如:JVM会将很小的方法变成inline的,因此对于小的方法就没有方法调用发生,性能会得到提升。编译器是通过代码的大小来决定是否将方法转为inline的,如果修改后的方法的大小不符合编译器的要求,那么性能会下降很多。
- 另外一个很有趣的地方是 ImmutableMap.get()方法在侵入式分析器中有,而在采样分析器中没有,这个是因为采样分析器需要在线程的安全点的时候才能进行采样,一般是内存分配的时候。而 ImmutableMap.get方法从不会到达安全点,也就有可能永远没法采样。
原生分析器
- 原生分析器是用来分析JVM本身的。它可以可视化地看到JVM和应用自身native库正在做什么。任何原生分析器都可以用来分析JVM的C代码,但是有些基于native的工具,还可以用来分析Java代码。
- 下图显示了使用Oracle Solaris Studio工具对启动GlassFish时做的分析。Oracle Solaris Studio是一个原生分析工具,可以用来分析Java或C/C++的代码。虽然名字里面有Solaris,但是它可以运行在Linux下面。由于内核架构的原因,这个工具运行在Linux下面,可以得到更多的信息。

- 一个显著的区别就是,总运行时间是25.1s,但是有20s是花在JVM自身上面。我们可以推测,由于服务器刚启动,这里有很多代码需要编译,所以大部分时间都花在编译器线程上面,当然还有一部分是GC线程消耗的。
- 如果我们不是为了hack JVM本身,这里的视图是足够的,尽管我们可以看到JVM的函数,并优化它们。原生分析器一个很重要的作用是可以看到GC消耗的时间,这个是Java类分析器看不到的。在Java类分析器中,GC线程的影响是没法发现的。(除非测试时运行在CPU绑定的机器上,编译器线程消耗的CPU不会影响应用,因为它只会在绑定的CPU上运行;只要机器上有足够的CPU,应用就不会受影响)
- 一旦原生代码(Native Code)的影响测试好了,我们可以重点关注真正启动的部分:
原生分析器中的采样分析器再次把defineclass1作为热点方法,整个启动过程的总时间为5.041秒,它消耗了0.550秒,大概占了11%左右(明显少于前面采样分析器的报告)。上面的分析报告还有一些之前没有被发现的现象:对JAR文件的读取和解压。很显然,它们和类的加载相关(用其它工具也是同样的结论^_^),但是这里我们可以看到读取JAR文件(通过inflateBytes函数)的I/o操作占用了多少CPU。其它分析工具没有给出这个结果,也许是在Java ZIP库中的native code被这些分析工具当成了阻塞调用,然后被过滤了。
- 无论是用什么分析工具,了解它们的特点非常重要。分析器是发现性能瓶颈的最重要工具,我们需要通过它们来发现需要进行代码优化的模块,而不是仅仅关注热点方法。
Java Mission Control(远程授权控制)
- Java7(从7u40开始)和Java8的商业版本包括一项新的监控和控制特性:Java Mission Control。对于使用过Jrockit JVM的用户来说,这个特性非常熟悉。不过Java Mission Control不是Open JDK的一部分,它需要商业授权。
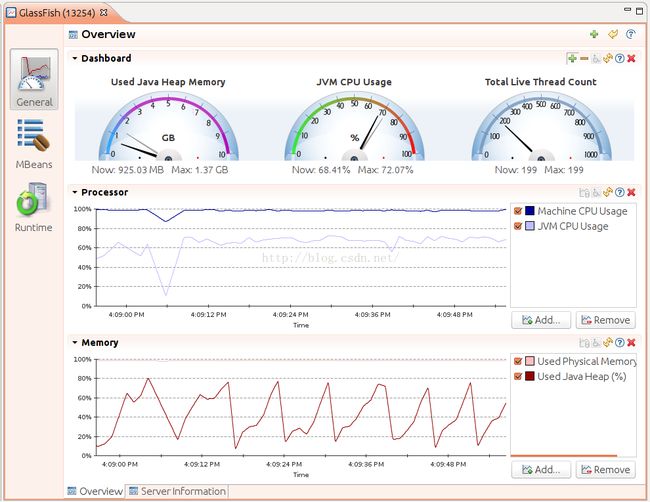
- Java Mission Control程序(jmc)会启动一个窗口程序,然后让我们选择对那进程进行监控,下图是对GlassFish应用服务器的监控界面。
Java Flight Recorder
- Java Mission Control的最主要的特征就是Java Flight Recorder。 正如它的名字所示,JFR的数据是一些列JVM事件的历史纪录,可以用来诊断JVM的性能和操作。
- JFR的基本操作就是开启哪些事件(比如:线程由于等待锁而阻塞的事件)。当开启的事件发生了,事件相关的数据会记录到内存或磁盘文件上。记录事件数据的缓存是循环使用的,只有最近发生的事件才能够从缓存中找到,之前的都因为缓存的限制被删除了。Java Mission Control能够对这些事件在界面上进行展示(从JVM的内存中读取或从事件数据文件中读取),我们可以通过这些事件来对JVM的性能进行诊断。
- 事件的类型、缓存的大小、事件数据的存储方式等等都是通过JVM参数、Java Mission Control的GUI界面、jcmd命令来控制的。JFR默认是编译进程序的,因为它的开销很小,一般来说对应用的影响小于1%。不过,如果我们增加了事件的数目、修改了记录事件的阈值,都有可能增加JFR的开销。下面我们来看看这些事件是什么样子的^_^
JFR概观
- 下面对GlassFish web服务器进行JFR记录的例子,在这个服务器上面运行着在第2章介绍的股票servlet。Java Mission Control加载完JFR获取的事件之后,大概是下面这个样子:

我们可以看到,通过上图可以看到:CPU使用率,Heap使用率,JVM信息,System Properties,JFR的记录情况等等。
JFR 内存视图
- Java Mission Control可以看到非常多的信息,下图只显示了一个标签的内容。下图显示了JVM的内存波动非常频繁,因为新生代经常被清除(有意思的是,head的大小并没有增长)。下面左边的面板显示了最近一段时间的垃圾回收情况,包括:GC的时长和垃圾回收的类型。如果我们点击一个事件,右边的面板会展示这个事件的具体情况,包括:垃圾垃圾回收的各个阶段及其统计信息。从面板的标签可以看到,还有很多其它信息,比如:有多少对象被清除了,花了多长时间;GC算法的配置;分配的对象信息等等。在第5章和第6章中,我们会详细介绍。
JFR 代码视图
- 这张图也有很多tab,可以看到各个包的使用频率和类的使用情况、异常、编译、代码缓存、类加载情况等等

JFR事件视图
- 下图显示了事件的概述视图
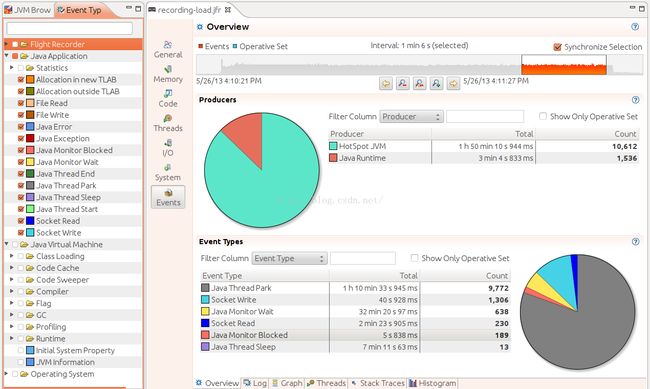
我们可以看到,有非常多的事件;总体上可以分为3类:Java应用事件、JVM事件以及操作系统事件。
由于事件很多,下面主要介绍几种常用的事件,这些事件的一些信息可以通过Jconsole,jcmd等工具获取,但是由于JFR的事件数据直接来自于JVM,它们的信息更详细;下面对事件的介绍分为两行,第一行是工具也可以获取的信息,第二行是JFR特有的信息。
- Classloading:
- 类加载和卸载的数目
- 哪些类被那个类加载器加载了;每个类加载花了多长时间
- Thread statistics:
- 线程创建和销毁的数目,线程的dump信息
- 哪些线程阻塞在哪个锁上面
- Throwables:
- 应用使用的Throwable类有哪些
- 应用抛出了多少异常和错误,以及创建它们的stack trace信息。
- TLAB allocation:
- 线程本地缓存分配(TLABs)的大小和数目
- 分配的是什么对象,分配时的tack trace信息。
- File and Socket I/O:
- 处理I/O的时间
- 每次read/write调用使用的时间,read或write使用时间最长的文件或socket是哪些
- Monitor Blocks:
- 对待Monior的线程
- 那个线程等待在那个Monior上以及等待的时长
- Code Cache:
- Code Cache的大小以及包含的内容
- 从Code Cache移除的方法以及Code Cache的配置
- Code compilation:
- 哪些方法是一般编译,哪些是OSR(on-stack-replacement)编译以及编译的时长
- JFR也没有提供额外的信息,但是从其它地方可以得到有用的信息
- Garbage Collection:
- GC的次数,包括:GC的各个阶段;各个年代的大小。
- JFR也没有提供额外的信息,但是从其它地方可以得到有用的信息
- Profiling:
- 侵入分析或采样分析
- JFR也没有提供更多的信息,但是JFR的数据直接来自于虚拟机的记录,所以数据更详细准确。
启动JFR
- 在商业版本上面,JFR默认是关闭的,可以通过在 启动时增加-XX:+UnlockCommercialFeatures -XX:+FlightRecorder参数来启动JVM。启动之后,也只是开启了JFR特性,但是还没有开始进行事件记录。这就要通过GUI和命令行了。
通过Java Mission Control启动JFR
- 打开Java Mission Control点击对应的JVM启动即可。事件记录有两种模式:1)记录固定一段时间的事件(比如:1分钟) 2)持续进行记录。如果选择第2种模式,那么JVM会使用一个循环使用的缓存来存放事件数据。
通过命令行启动JFR
- 通过在启动的时候,增加参数 -XX:+FlightRecorderOptions=string来启动真正地事件记录。这里的string可以是以下值:
- name = name:标识recording的名字(一个进程可以有多个recording存在,它们使用名字来进行区分)
- defaultrecording=<ture|false>:是否启动recording,默认是false,我们要分析,必须要设置为true。
- setting=paths:包含JFR配置的文件名字。
- delay=time:启动之后,经过多长时间(比如:30s,1h)开始进行recording
- duration=time:做多长时间的recording
- filename=path:recordding记录到那个文件里面
- compress=<ture|false>:是否对recording进行压缩(gzip),默认为false
- maxage=time:在循环使用的缓存中,事件数据保存的最大时长
- maxsize=size:事件数据缓存的最大大小(比如:1024k,1M)
- 上面这些参数都可以使用jcmd命令,在JVM运行的时候进行动态调整。
- 启动recording:% jcmd process_id JFR.start [options_list] options_list就是上面的那些值
- dump出循环缓存中的数据:% jcmd process_id JFR.dump [options_list] options_list可以是:
- name = name:recording的名字
- recording=n:JFR recording的数字(一个标识recording的随机数)
- filename=path:dump文件的保存路径
- 查看进程中所有recording:% jcmd process_id JFR.check [verbose] 不同recording使用名字进行区分,同时JVM还为它分配一个随机数。
- 停止recording:% jcmd process_id JFR.stop [options_list] options_list可以是:
- name = name:要停止的recording名字
- recording = n:要停止的recording的标识数字
- discard=boolean:如果为true,数据被丢弃,而不是写入下面指定的文件当中
- filename=path:写入数据的文件名称
预告:下一章将重点讨论Java虚拟机的核心模块:即时编译器(Just-In-Time complier JIT编译器)。