Go语言学习笔记3
3.Go语言数据类型
其实前面已经涉及到了数据类型的一些知识点。本篇将仔细地讲讲Go语言的数据类型。
3.1 基本数据类型
| 名称 | 宽度(字节) | 零值 | 说明 |
|---|---|---|---|
| bool | 1 | false | 布尔类型,真用常量true表示,假用常量false表示 |
| byte | 1 | 0 | 字节类型,可看作uint8的别名类型 |
| rune | 4 | 0 | rune类型,专门存储Unicode编码,可看作uint32的别名类型 |
| int/uint | - | 0 | 有符号整数类型/无符号整数类型,宽度与平台相关 |
| int8/uint8 | 1 | 0 | 由8位二进制数表示的有符号整数类型/无符号整数类型 |
| int16/uint16 | 2 | 0 | 由16位二进制数表示的有符号整数类型/无符号整数类型 |
| int32/uint32 | 4 | 0 | 由32位二进制数表示的有符号整数类型/无符号整数类型 |
| int64/uint64 | 8 | 0 | 由64位二进制数表示的有符号整数类型/无符号整数类型 |
| float32 | 4 | 0.0 | 由32位二进制数表示的浮点数类型 |
| float64 | 8 | 0.0 | 由64位二进制数表示的浮点数类型 |
| complex64 | 8 | 0.0 | 由64位二进制数表示的复数类型,float32类型的实部和float32类型的虚部联合表示 |
| complex128 | 16 | 0.0 | 由128位二进制数表示的复数类型,float64类型的实部和float64类型的虚部联合表示 |
| string | - | “” | 字符串类型(实质是字节序列) |
数值类型
宽度的含义
| 字节(byte) | 比特(bit) | 数值范围 |
|---|---|---|
| 1 | 8 | 无符号 0~255,有符号 -128~127 |
| 2 | 16 | 无符号0~65535,有符号-32768~32767 |
| 4 | 32 | 无符号0~4294967295,有符号-2147483648~2147483647 |
| 8 | 64 | 无符号 ≈ 0~1844亿亿,有符号 ≈ -922亿亿~922亿亿 |
现在举出如下的例子:
12E+2 //浮点数字面量,代表浮点数 1200.0(12乘以10的2次方)
12e-3 //浮点数字面量,代表浮点数 0.012(12除以10的3次方)
1200.0 //浮点数字面量,可以被简写为 1200
0.012 //浮点数字面量,可以被简写为 .012
//浮点数字面量中的各个部分只能由十进制表示,而不能由八进制数和十六进制数表示
//浮点数字面量 056.78 和 56.78 都代表浮点数 56.78
12e+2 + 43.4e-3i //复数字面量,代表了复数 1200+0.0434i
0.1i //复数字面量,代表了复数 0+0.1i
1E3 //这里可以是复数字面量,代表了复数 1000+0iGo语言的一个特有的数值类型rune,专门用于存储经过Unicode编码的字符。
可以用如下的5种方式表示一个rune字面量:
- 该rune字面量所对应的字符,这个字符必须是Unicode编码规范所支持的。
- 使用“\x”为前导并后跟两位十六进制数。这种可以表示一个ASCII编码值(一个字节)。
- 使用“\”为前导并后跟三位八进制。这种也是可以表示一个ASCII编码值(一个字节)。
- 使用“\u”为前导并后跟四位十六进制。Unicode编码规范中的UCS-2表示法(将会废止),只能用于表示2个字节宽度的值。
- 使用“\U”为前导并后跟八位十六进制。Unicode编码规范中的UCS-4表示法。可用于表示4个字节的值。
rune字面量可以支持一类特殊的字符序列——转义符(除了最后一个特殊)如下所示:
| 转义符 | Unicode代码点 | 说明 |
|---|---|---|
| \a | U+0007 | 告警铃声或蜂鸣声 |
| \b | U+0008 | 退格符 |
| \f | U+000C | 换页符 |
| \n | U+000A | 换行符 |
| \r | U+000D | 回车符 |
| \t | U+0009 | 水平制表符 |
| \v | U+000B | 垂直制表符 |
| \\ | U+005C | 反斜杠 |
| \’ | U+0027 | 单引号。仅在rune字面量中有效。 |
| \” | U+0022 | 双引号。仅在string字面量中有效。 |
注意:在rune字面量中,除了在上面表格中出现的转义符之外的以 \ 为前导的字符序列都是不合法的。当然,上表中的转义符 \” 也不能在rune字面量中出现。
字符串类型
在Go语言中,字符串类型属于预定义类型,代表了一个字符串值的集合。在底层,一个字符串值即是一个字节的序列。字符串的长度即是底层字节序列中字节的个数。长度为0的序列与一个空字符串相对应。
字符串字面量(或者说是字符串常量)代表了一个连续的字符序列,它的长度在编译期间就能确定。它有两种表示格式:
- 1.原生字符串字面量
- 它是在两个反引号 ` 之间的字符序列。在两个反引号之间,除了反引号之外的其他字符都是合法的。在两个反引号之间的内容是由若干在编译期间就可以确定的字符组成。在原生字符串字面量中,不存在任何转义符,所见既所得。另外,其中的回车符会被编译器移除。
- 2.解释型字符串字面量
- 它是在两个双引号 “ 之间的字符序列。在解释型字符串中的转义字符都是会被成功转义。
在字符串字面量中,转义符 \’是不合法的,而转义符 \”却是合法的。这与rune字面量刚好相反,但在字符串字面量中可以包含rune字面量。例如。在解释型字符串字面量中,rune字面量‘\101’和‘\x41’都代表了单字节字符“A”(单字节字符就是经过UTF-8编码格式编码后的字节序列的大小为1的字符);而rune字面量‘\u4E00’和‘\U00004E00’都与Unicode字符“一”相对应。中文字符“一”的Unicode代码点为U+4E00,它会被UTF-8编码格式编码为3个字节,即“\xE4\xB8\x80”。
字符串字面量与rune字面量的本质区别是所代表的Unicode字符的数量。rune字面量仅用于代表一个Unicode字符,无论这个字符会被UTF-8编码格式编码为几个字节,而字符串字面量则用于代表一个由若干个Unicode字符组成的序列。
注意:字符串值是不可变的,对字符串的操作只会返回一个新字符串,而不是改变源字符串并返回。
3.2 数组
在Go语言中,数组被称为Array,就是一个由若干相同类型的元素组成的序列。
类型表示法
如下声明了一个长度为n,元素类型为T的数组类型:
[n]T注意:数组的长度是数组类型的一部分。只要类型声明中的数组长度不同,即使两个数组类型的的元素类型相同,它们也还是不同的类型。例如,数组类型[2]string和[3]string就是两个不同的类型,虽然它们的元素类型都是string。所有属于这个类型的数组的长度都是固定的。
在数组类型声明中所标识的长度可以由一个非负的整数字面量代表,也可以由一个表达式代表(这个表达式必须是一个int类型的非负值),例如:
[2*3+4]byte这个类型字面量表示了一个元素类型为byte的数组类型。
数组类型声明中的元素类型可以是任意一个有效的Go语言数据类型(预定义数据类型、复合数据类型,自定义数据类型或者类型字面量)。例如:
[5]struct{ name, address string} // ”struct {…}”是用于自定义匿名结构体类型的类型字面量以上提示我们,虽然数组的元素类型只能是单一数据类型,但是因为这个单一数据类型可以是一个复合数据类型,所以可以使用数组构造出更多样的数据结构,而不只是把它当做包含若干相同类型元素的有序列表。
值表示法
数组类型的值(简称数组值)可以由复合字面量来表示。例如:
[6]string{"Go", "Python", "Java", "C", "C++", "PHP"}该字面量表示了一个长度为6,元素类型为string的数组值,且已包含了6个元素值。
我们也可以编写上面的复合字面量的时候指定元素值的索引值。例如:
[6]string{0: "Go", 1: "Python", 2: "Java", 3: "C", 4: "C++", 5: "PHP"}这个字面量也体现了在默认情况下的各个元素值与索引值的对应关系。
这种添加索引值的字面量也可以打乱默认的对应关系,例如:
[6]string{2: "Go", 1: "Python", 5: "Java", 4: "C", 3: "C++", 0: "PHP"}或者,只显式地指定一部分元素值的索引值,例如:
[6]string{5: "Go", 0: "Python", "Java", "C", "C++", 4: "PHP"}如上“Java”, “C”,“C++” 的隐含索引值为1, 2, 3
索引值的指定方式很灵活,但还是需要满足下面两个条件:
- 指定的索引值必须在该数组的类型所体现的有效范围之内,即大于等于0并且小于数组类型中声明的长度。同样,我们指定的索引值也不能导致后续元素值的索引值超出范围。
- 指定的索引值不能与其他元素值的索引值重复,不论其他元素值的是隐含对应的还是显式对应的。
方括号之间的整数表示数组值的长度,它必须大于或等于花括号中元素值的实际数量。例如:
[8]string{"Go", "Python", "Java", "C", "C++", "PHP"}上面这个数组值等同于下面的复合字面量:
[8]string{0: "Go", 1: "Python", 2: "Java", 3: "C", 4: "C++", 5: "PHP", 6: "", 7: ""}我们也可以不指定数组值的长度,而是让其中元素值的实际数量决定,例如:
[...]string{"Go", "Python", "Java", "C", "C++", "PHP"}属性和基本操作
数组类型属于值类型。一个数组类型的变量在被声明之后就会拥有一个非空值。这个非空值包含的元素值的数量与其类型中所声明的长度一致,并且其中的每个元素值都是其类型的元素类型的零值。
在Go语言中,一个数组即是一个值。数组类型的变量即代表了整个数组,不像C语言中的数组代表一个指向数组的第一个元素值的指针。因此,当我们将一个数组值赋给一个变量或者传递给一个函数的时候,会隐含地创建出此数组值的一个备份。为避免这种隐含的备份,我们可以通过取址操作符获取到这个数组值的指针,并把这个指针用在变量赋值操作和函数参数传递的操作中。
使用Go语言的内建函数len来获取数组值的长度,例如:
len([...]string{"Go", "Python", "Java", "C", "C++", "PHP"})通过索引值访问数组中的每一个元素,例如:
[...]string{"Go", "Python", "Java", "C", "C++", "PHP"}[0]//值是"Go"
[...]string{"Go", "Python", "Java", "C", "C++", "PHP"}[5]//值是"PHP"通过索引值改变对应的元素,例如:
// := 表示声明一个变量的同时对这个变量进行赋值。
array1 := [6]string{"Go", "Python", "Java", "C", "C++", "PHP"}//数组值赋给变量array1
array1[1] = "Swift" //与索引值1对应的元素修改为字符串类型值Swift执行上面的语句后,array1的值:
[6]string{"Go", "Python", "Java", "C", "C++", "PHP"}注意:如果上面的array1的值为nil,那么索引值在被求值时就会引发一个运行时恐慌。同样索引值不在有效范围内的时候也一样。
3.3 切片
切片可以看作是对数组的一种包装形式。切片包装的数组称为该切片的底层数组。切片是针对其底层数组中某个连续片段的描述符。
类型表示法
对于一个元素类型为T的切片类型来说,它的类型字面量就是:
[]T可以看出,长度并不是切片类型的一部分(即它不会出现在表示切片类型的类型字面量中)。另外,切片的长度是可变的。相同类型的切片值可能会有不同的长度。
切片类型声明中的元素类型也可以是任意一个有效的Go语言数据类型。例如:
[]rune如上用于表示元素类型为rune的切片类型。
同样可以把一个匿名结构体类型作为切片类型的元素类型。例如:
[] struct {name, department string}值表示法
和数组类似,也是复合字面量中的一种,例如:
[]string{"Go", "Python", "Java", "C", "C++", "PHP"}在切片值所属的类型中根本就没有关于长度的规定。以下切片是合法的:
[]string{8: "Go", 2: "Swift", "Java", "C", "C++", "PHP"}上面的等同于下面的复合字面量:
[]string{0: "", 1: "", 2: "Swift", 3: "Java", 4: "C", 5: "C++", 6: "PHP", 7: "", 8: "Go"}属性和基本操作
切片类型的零值为nil。在初始化之前,一个切片类型的变量值为nil。
切片类型中虽然没有关于长度的声明,但是值是有长度的,体现在它们所包含的元素值的实际数量。可以使用内建函数len来获取切片值的长度。例如:
len([]string{8: "Go", 2: "Swift", "Java", "C", "C++", "PHP"})上面计算的结果值为9,这个切片值实际包含了6个被明确指定的string类型值和3个被填充的string类型的零值“”。
注意:在切片类型的零值(即nil)上应用内建函数len会得到0。
- 切片值的底层实现方式:
- 一个切片值总会持有一个对某个数组值的引用。一个切片值一旦被初始化,就会与一个包含了其中元素值的数组值相关联。这个数组值被称为引用他的切片值的底层数组。
多个切片值可能会共用一个底层数组。例如,如果把一个切片值复制成多个,或者针对其中的某个连续片段在切片成新的切片值,那么这些切片值所引用的都会是同一个底层数组。对切片值中的元素值的修改,实质上就是对其底层数组上的对应元素的修改。反过来讲,对作为底层元素的数组值中的元素值的改变,也会体现到引用该底层数组其包含该元素值的所有切片值上。
除了长度之外,切片值还有一个很重要的属性—–容量。切片值的容量与它所持有的底层数组的长度有关。可以通过内建函数cap来获取它。例如:
cap([]string{8: "Go", 2: "Swift", "Java", "C", "C++", "PHP"})该切片值的容量是9,就等于它的长度。这是个特例,但很多情况下不是这样,且听慢慢道来。
- 切片值的底层数据结构:
- 一个切片值的底层数据结构包含了一个指向底层数组的指针类型值,一个代表了切片长度的int类型值和一个代表了切片容量的int类型值。
可以使用切片表达式从一个数组值或者切片值上”切”出一个连续片段,并生成一个新的切片值。例如:
array1 := [...]string{8: "Go", 2: "Swift", "Java", "C", "C++", "PHP"}
slice1 := array1[:4]变量slice1的值的底层数组实际上就是变量array1的值,如下图:
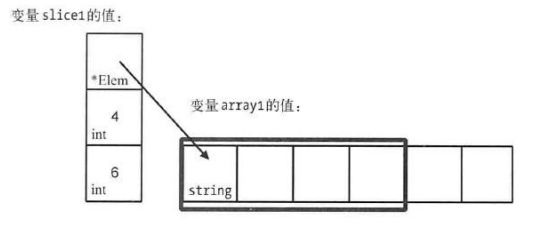
经过上面的描述,大家可能认为一个切片的容量可能就是其底层数组的长度。但事实并非如此,这里再创建一个切片值。例如:
slice2 := array1[3:]变量slice2的值的底层数组也是变量array1的值,如下图:
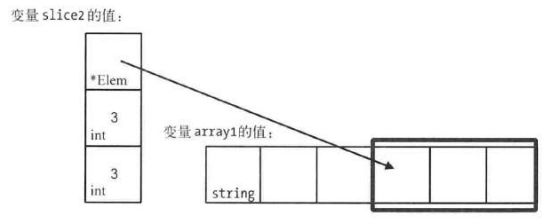
如上所示slice2的值的容量与array1的值的长度并不相等。实际上,一个切片值的容量是从其中的指针指向的那个元素值到底层数组的最后一个元素值的计数值。切片值的容量的含义是其能够访问到的当前底层数组中的元素值的最大数量。
可以对切片值进行扩展,以查看更多底层数组元素。但是,并不能直接通过再切片的方式来扩展窗口。例如对于上面原始的slice1的值进行如下操作:
slice1[4]这会引起一个运行时恐慌,因为其中的索引值超出了这个切片值当前的长度,这是不允许的。正确拓展的方式如下:
slice1 = slice1[:cap(slice1)]通过再切片的方式把slice1扩展到了最大,可以看到最多的底层数组元素值了。这时slice1的值的长度等于其容量。
注意:一个切片值的容量是固定的。也就是说,能够看到的底层数组元素的最大数量是固定的。
不能把切片值扩展到其容量之外,例如:
slice1 = slice1[:cap(slice1)+1]//超出slice1容量的范围,这样会引起一个运行时恐慌一个切片值只能向索引递增的方向扩展。例如:
slice2 = slice2[-2:] //这会引起一个运行时恐慌。另外,切片值不允许由负整数字面量代表。使用append函数来扩展一开始的slice1的值:
slice1 = append(slice1, "Ruby", "Erlang")执行该语句后,切片类型变量slice1的值及其底层数组(数组变量array1的值)的状态,如下图:
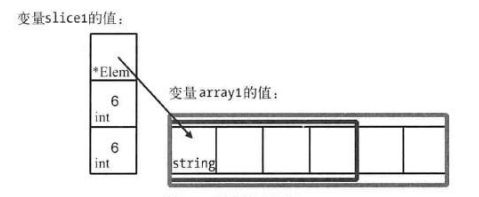
可以看出,slice1的值的长度已经由原来的4增长到了6,与它的容量是相同的。但是由于这个值的长度还没有超出它的容量,所以没必要再创建出一个新的底层数组出来。
原来的slice1的值为:
[]string{"Go", "Python", "Java", "C"}现在的slice1的值为:
[]string{"Go", "Python", "Java", "C", "Ruby", "Erlang"}原来的array1的值为:
[6]string{"Go", "Python", "Java", "C", "C++", "PHP"}现在的array1的值为:
[6]string{"Go", "Python", "Java", "C", "Ruby", "Erlang"}对现在的slice1再进行扩展,如下:
slice1 = append(slice1, "Lisp")执行这条语句后,变量slice1的值的长度就超出了它的容量。这时将会有一个新的数组值被创建并初始化。这个新的数组值将作为在append函数新创建的切片值的底层数组,并包含原切片值中的全部元素值以及作为扩展内容的所有元素值。新切片值中的指针将指向其底层数组的第一个元素值,且它长度和容量都与其底层数组的长度相同。最后,这个新的切片值会被赋给变量slice1。
可以使用append函数把两个元素类型相同的切片值连接起来。例如:
slice1 = append(slice1, slice...)当然也可以把数组值作为第二个参数传递给append函数。
即使切片类型的变量的值为零值nil,也会被看作是长度为0的切片值。例如:
slice2 = nil
slice2 = append(slice2, slice1...)或者如下:
var slice4 []string
slice4 = append(slice4, slice...)上面第一条语句用于声明(不包含初始化)一个变量。以关键字var作为开始,并后跟变量的名称和类型。未被初始化的切片变量的值为nil。
切片使用的复杂用法
切片表达式中添加第三个索引—–容量上界索引。如果被指定,那么切片表达式的求值结果的那个切片值的容量就不再是该切片表达式的操作对象的容量与该表达式中的元素下界索引之间的差值,而是容量上界索引与元素下界索引之间的差值。
指定容量上界索引的目的就是为了减小新切片值的容量,可以允许更加灵活的数据隔离策略。
var array2 [10]int = [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice5 := array2[2:6]如上我们可以直接访问和修改array2中对应索引值在[2,6)范围之内的元素值。
slice5 = slice5[:cap(slice5)]如上再切片后,可以访问和修改array2的值中对应索引值在[2,10)范围之内的元素值。
如果slice5的值作为数据载体传递给了另一个程序,那么这个程序可以随意地更改array2的值中的某些元素值。这就等于暴露了程序中的部分实现细节,并公开了一个可以间接修改程序内部状态的方法,而往往这并不是我们想要的。
如果这样声明slice5:
slice5 := array2[2:6:8]这样slice5的持有者只能访问和修改array2的值中对应索引值在[2,8)范围之内的元素值。
slice5 = slice5[:cap(slice5)]即使将slice5扩展到最大,也不能通过它访问到array2的值中对应索引值大于等于8的那些元素。此时,slice5的值的容量为6(容量上界索引与元素下界索引的差值)。对于切片操作来说,被操作对象的容量是一个不可逾越的限制。slice5的值对其底层数组(array2的值)的“访问权限”得到了限制。
如果在slice5的值之上的扩展超出了它的容量:
slice5 = append(slice5, []int{10, 11, 12, 13, 14, 15}…)那么它原有的底层数组就会被替换。也就彻底切断了通过slice5访问和修改其原有底层数组中的元素值的途径。
切片表达式中的3个索引的限制:当在切片表达式中指定容量上界索引的时候,元素上界索引是不能够省略。但是,在这种情况下元素下界索引却是可以省略的。例如:
slice5[:3:5]//合法的切片表达式
slice5[0::5]//非法的切片表达式,会造成一个编译错误批量复制切片值中的元素
sliceA := []string{"Notepad", "UltraEdit", "Eclipse"}
sliceB := []string{"Vim", "Emacs", "LiteIDE", "IDEA"}使用Go语言的内建函数copy,将变量sliceB的值中的元素复制到sliceA的值中。例如:
n1 := copy(sliceA,sliceB)内建函数copy的作用是把源切片值(第二个参数值)中的元素值复制到目标切片值(第一个参数值)中,并且返回被复制的元素值的数量。copy函数的两个参数的元素类型必须一致,且它实际复制的元素值的数量将等于长度较短的那个切片值的长度。
变量n1的值为3, 变量sliceA的值被修改为:
[]string{"Vim", "Emacs", "LiteIDE"}3.4 字典
在Go语言中,字典类型的官方称谓是Map, 它是哈希表(Hash Table)的一个实现。
类型表示法
如果一个字典类型的键的类型为K,且元素的类型为T,那么用于表示这个字典类型的类型字面量:
map[K]T字典类型声明中的元素类型可以是任意一个有效的Go语言数据类型(除了函数类型、字典类型或切片类型)。键的类型必须是可比较的。如果字典类型的键类型是接口类型,那么就要求在程序运行期间,该类型的字典值中的每一个键值的动态类型都必须是可比较的。否则在进行相应操作的时候会引发运行时异常。如下:
map[int]string//合法
map[string]struct{name, department string}//合法
map[string]interface{}//合法
map[[]int]string//不合法
map[map[int]string]string//不合法值表示法
字典值可以由复合字面量来表示。
一个类型为map[string]bool的字典值:
map[string]bool{"Vim": true, "Emacs": true, "LiteIDE": true, "Notepad": false}一个不包含任何键值对的空字典值:
map[string]bool{}属性和基本操作
与指针类型和切片类型一样,字典类型是一个引用类型。与切片值相同,一个字典值总是会持有一个针对某个底层数据结构值的引用。
知识点:在Go语言中,只有“传值”而没有“传引用”。函数内部对参数值的改变是否会在该函数之外体现出来(或者说是否反映在该参数值的原值上),只取决于这个被改变的值的类型是值类型还是引用类型。
因为字典类型是引用类型,所以它的零值是nil。一个值为nil的字典类型的变量类似于一个长度为0的空字典。对它的读操作不会引起任何错误,但是对它的写操作(添加或删除键值对)将会引起一个运行时恐慌。一个未初始化的字典类型的变量的值就是nil。
这里声明并初始化一个字典类型的变量,如下:
editorSign := map[string]bool{"LiteIDE": true, "Notepad": false}添加键值对,如下:
editorSign["Vim"] = true通过索引表达式在一个字典中查找并获取与指定键值对应的那个元素值,如下:
sign1 := editorSign["Vim"]当editorSign的值中没有键为“Vim”的键值对时,变量sign1将会被赋予editorSign的元素类型的零值,即false。
sign1, ok := editorSign["Vim"]变量ok将会是布尔类型,它的值表明了在editorSign的值中是否存在键为“Vim”的键值对。
删除键值对,如下:
delete(editorSign, "Vim")注意: 字典值并不是并发安全的!Go语言官方认为,在大多数使用字典值的地方并不需要多线程场景下的安全访问控制。保证并发安全性,需要使用标准库代码包sync中的结构体类型RWMutex(一个读写互斥量,常常用于多线程环境下的并发控制)。这个暂时放到后续博文讲解。
以上讲解了Go语言的基本数据类型,数组类型,切片类型,字典类型,由于篇幅过多,其他类型放到下篇博文中讲解。
最后附上知名的Go语言开源框架(每篇更新一个):
Gogs: 一个国产的自助Git托管服务程序。我们可以用它来搭建自己的Git服务器。官网:https://gogs.io。