Spark内存管理
概述
spark从1.6.0开始内存管理发生了变化,原来的内存管理由StaticMemoryManager实现,现在被称为Legacy,在1.5.x和1.6.0中运行相同代码的行为是不同的,为了兼容Legacy,可以通过spark.memory.useLegacyMode来设置,默认该参数是关闭的。
spark.memory.useLegacyMode=false如果采用1.6之前的模型,这会使用StaticMemoryManager来管理,否则使用新的UnifiedMemoryManager。
1.6.0之前的内存组成
我们先看看1.6之前,对于一个Executor,内存都有哪些部分构成:
ExecutionMemory。这片内存区域是为了解决 shuffles,joins, sorts and aggregations 过程中为了避免频繁IO需要的buffer。 通过spark.shuffle.memoryFraction(默认 0.2) 配置。
StorageMemory。这片内存区域是为了解决 block cache(就是你显示调用dd.cache, rdd.persist等方法), 还有就是broadcasts,以及task results的存储。可以通过参数 spark.storage.memoryFraction(默认0.6)。设置
OtherMemory。给系统预留的,因为程序本身运行也是需要内存的。 (默认为0.2).
另外,为了防止OOM,一般而言都会有个safetyFraction,比如ExecutionMemory 真正的可用内存是 spark.shuffle.memoryFraction * spark.shuffle.safetyFraction 也就是0.8 * 0.2 ,只有16%的内存可用。
这种内存分配机制,最大的问题是,谁都不能超过自己的上限,规定了是多少就是多少,虽然另外一片内存闲着呢。这在是StorageMemory 和 ExecutionMemory比较严重,他们都是消耗内存的大户。
这个问题引出了Unified Memory Management模型,重点是打破ExecutionMemory 和 StorageMemory 这种分明的界限。
1.6.0的统一内存管理如下:
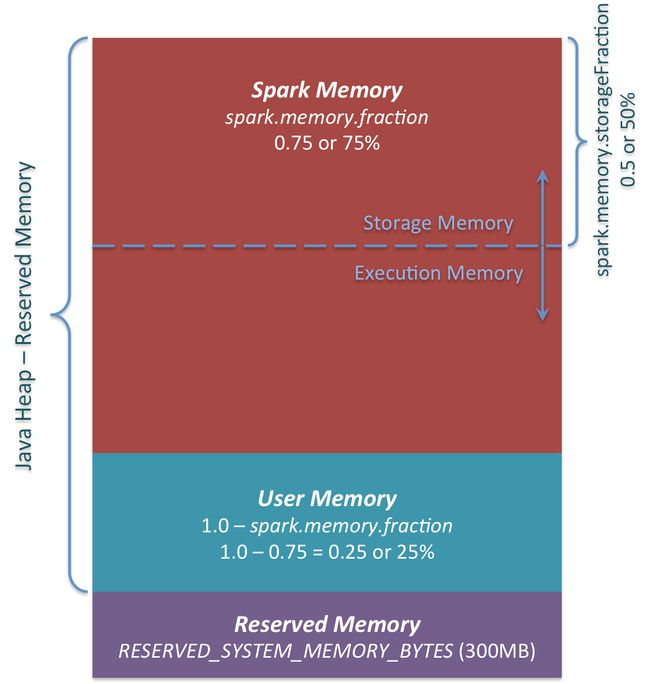
主要有三部分组成:
1 Reserved Memory
这部分内存是预留给系统使用,是固定不变的。在1.6.0默认为300MB(RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024),这一部分内存不计算在spark execution和storage中,除了重新编译spark和spark.testing.reservedMemory,Reserved Memory是不可以改变的,spark.testing.reservedMemory不推荐使用在实际运行环境中。是用来存储Spark internal objects,并且限制JVM的大小,如果executor的大小小于1.5 * Reserved Memory = 450MB ,那么就会报 “please use larger heap size”的错误,源码如下。
val minSystemMemory = reservedMemory * 1.5
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please use a larger heap size.")
}2 User Memory
分配Spark Memory剩余的内存,用户可以根据需要使用。可以存储RDD transformations需要的数据结构,例如, 重写spark aggregation,使用mapPartition transformation,通过hash table来实现aggregation,这样使用的就是User Memory。在1.6.0中,计算方法为(Java Heap - Reserved Memory) * (1.0 - spark.memory.fraction),默认为(Java Heap - 300M) * 0.25,比如4GB的heap大小,那么User Memory的大小为949MB。由用户来决定存储的数据量,因此要遵守这个边界,不然会导致OOM。再次说明一下,这一块内存是User Memory,存什么和怎么存都取决于你,Spark不会管你在这里干什么和是否忽略分界。代码中忽略分界可能会导致OOM(out of memory)错误。
3 Spark Memory
计算方式为:(Java Heap – Reserved Memory) * spark.memory.fraction,在1.6.0中,默认为(Java Heap - 300M) * 0.75。例如堆的大小为4GB,那么Spark Memory为2847MB。Spark Memory又分为Storage Memory和Execution Memory两部分。两个边界由spark.memory.storageFraction设定,默认为0.5。但是两部分可以动态变化,相互之间可以借用,如果一方使用完,可以向另一方借用。先看看两部分是如何使用的。
Storage Memory 用来存储spark cached data也可作为临时空间存储序列化unroll,broadcast variables作为cached block存储,但是需要注意,这是unroll源码,unrolled block如果内存不够,会存储在driver端。broadcast variables大部分存储级别为MEMORY_AND_DISK。
Execution Memory 存储Spark task执行过程中需要的对象,例如,Shuffle中map端中间数据的存储,以及hash aggregation中的hash table。如果内存不足,该空间也容许spill到磁盘。
我们可以从Storage Memory中清除出内存块,但Execution Memory则不行。那么Execution Memory内存池何时可以从Storage Memory中借取内存?有以下两种情况:
Storage Memory还有free空间
- Storage Memory中有空闲的空间,比如说缓存块没有将所有空间用尽。然后就会减少Storage Memory,增加Execution Memory。
- 当Storage Memory超出了初始的分区大小并用完了所有空间,这种情况会导致从Storage Memory中借取空间,除非它达到了初始大小。
反过来,只有在Execution Memory有空闲空间时Storage Memory才可以从Execution Memory借取一些空间。
初始的Storage Memory分区大小是通过Spark Memory * spark.memory.storageFraction = (Java Heap - Reserved Memory)* spark.memory.fraction * spark.memory.storageFraction,默认大小是(Java Heap - 300M) * 0.75 * 0.5 = (Java Heap - 300M) * 0.375。比如Heap有4G,那初始Storage Memory分区就有1423.5M。
这意味着如果我们用Spark cache并且executor上缓存的数据量至少达到初始的Storage Memory大小,那么storage分区大小就会保持至少初始大小,因为我们无法从Storage Memory中清除内存块并使之变小。然而如果填满了Storage Memory分区之前Execution Memory分区就增长超过了其初始大小,你不能强行从Execution Memory中清除内存,那么最后执行Memory占用Storgae Memory内存,Storage Memory就会比初始大小要小。
参考:
spark架构:
https://0x0fff.com/spark-architecture/
spark内存管理原文档
http://0x0fff.com/spark-memory-management/
spark内存管理代码分析
http://www.jianshu.com/p/b250797b452a