如何获取(GET)一杯咖啡——星巴克REST案例分析
英文原文:How to GET a Cup of Coffee
我们已习惯于在大型中间件平台(比如那些实现CORBA、Web服务协议栈和J2EE的平台)之上构建分布式系统了。在这篇文章里,我们将采取另一种做法:我们把支撑Web运行的协议和文档格式视为一种应用平台,一种可通过轻量级中间件访问的平台。我们通过一个简单的客户-服务交互的例子,展示了Web在应用集成中的作用。在这篇文章里,我们以Web为主要设计理念,提炼并分享了我们下本书《GET /connected - Web-based integration》(暂定名称)里的一些想法。
引言
我们知道,集成领域是不断变化的。Web的影响以及敏捷实践的潮流正在挑战我们的关于“良好的集成由什么构成”的观念。集成(integration)并不是一种夹在系统之间的专业活动;与此相反,现在,集成是成功方案里的不可缺少的一部分。
然而,仍有许多人误解并低估Web在企业计算中的作用。即便是那些精通Web的人士,也常常要花费很大力气才能懂得,Web不是关于支持XML over HTTP的中间件方案,也不是一种简易的RPC机制。这是相当遗憾的,因为Web不是仅能提供简单的点对点连接,它还有更大的用处;它实际上是一个健壮的集成平台。
在这篇文章里,我们将展示Web的一些值得关注的用途,我们将视之为一种可塑的、健壮的平台,它能够对企业系统做很“酷”的事。另外,工作流是企业软件最具代表性的特征。
为什么要工作流?
工作流(workflows)是企业计算的主要特征,它们基本上都是用中间件实现的(至少在计算方面)。工作流把一项工作(work)划分为多个离散的步骤(steps)以及触发步骤转移的事件(events)。工作流所实现的整个业务流程常常跨越若干企业信息系统,这给工作流带来很多集成问题。
星巴克:统一标准的咖啡需要统一标准的集成
Web若要成为可用于企业集成的技术,它就必须支持工作流——从而可靠地协调不同系统间的交互,以实现更大的业务能力。
要恰如其份地介绍工作流,就免不了讲述一大堆跟领域相关的技术细节,而这不是本文的主旨,因此,我们选择了Gregor Hohpe的星巴克工作流这个比较好理解的例子来举例说明基于Web的集成的工作原理。在这篇受到大家欢迎的博客文章里,Gregor讲述了星巴克是如何形成一个解耦合的(decoupled)盈利生产线的:
“跟大部分餐饮企业一样,星巴克也主要致力于将订单处理的吞吐量最大化。顾客订单越多,收入就越多。为此,他们采取了异步处理的办法。你在点单时,收银员取出一只咖啡杯,在上面作上记号表明你点的是什么,然后把这个杯子放到队列里去。这里的队列指的是在咖啡机前排成一列的咖啡杯。正是这个队列将收银员与咖啡师解耦开,从而,即便在咖啡师一时忙不过来的时候,收银员仍然可以为顾客点单。他们可以在繁忙时段安排多个咖啡师,就像竞争消费者模式(Competing Consumer)里那样。”
Gregor是采用EAI技术(如面向消息的中间件)来讲解星巴克案例的,而我们将采用Web资源(支持统一接口的可寻址实体)来讲解同一案例。实际上,我们将展示Web技术何以能够具有跟传统EAI工具一样的可靠性,以及何以不仅仅是请求/响应协议之上的XML消息传递!
首先,我们很抱歉擅自设想了星巴克的工作流程,因为我们的目的并不是精确无误地描述星巴克,而是用基于Web的服务来讲解工作流。好的,既然讲清楚了这一点,那么我们现在开始吧。
简明陈述
因为我们在讲工作流,所以我们有必要理解构成工作流的状态(states)以及将工作流从一个状态转移到另一个状态的事件(events)。我们的例子里有两个工作流,我们把它们用状态机(state machines)表达出来了。这两个工作流是并行执行的。一个反映了顾客与星巴克服务之间的交互(如图1),另一个刻画了由咖啡师执行的一系列动作(如图2)。
在顾客工作流里,顾客为了得到某种口味的咖啡而与星巴克服务进行交互。我们假定该工作流里包含以下动作:顾客点单,付款,然后等待饮品。在点单与付款之间,顾客通常可以修改菜单,比方说请求改用半脱脂牛奶。
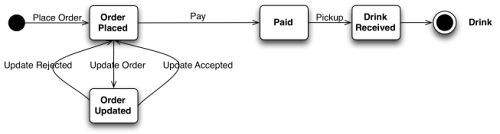
图1 顾客状态机
尽管顾客看不见咖啡师,但咖啡师也有自己的状态机;这个状态机是服务实现私有的。如图2所示,咖啡师在周而复始地等待下一个订单,制作饮品,然后收取费用。当一个订单被加入到咖啡师的队列中时,一次循环实例就开始了。当咖啡师完成订单并把饮品交付给顾客时,工作流就结束了。
图2 咖啡师的状态机
尽管这些看似跟基于Web的集成毫不相干,但这两个状态机里的每一个状态迁移,都代表着与Web资源的一次交互。每一次迁移,就是通过URI对资源实施HTTP操作,从而导致状态的改变。
GET和HEAD属于特例,因为它们不引起状态迁移。它们的作用是用于查看资源的当前状态。
我们节奏稍快了点。理解状态机和Web,不是那么容易一口吃个胖子的。所以,让我们在Web的背景下,来从头回顾一下整个场景,逐步慢慢深入。
顾客视角
我们将从一张简单的故事卡片开始,它启动整个流程:

这个故事里涉及一些有用的角色与实体。首先,里面有“顾客(Customer)”角色。显然,它是(隐含的)星巴克服务(Starbucks Service)的消费者。其次,里面有两个重要的实体(“咖啡”和“订单”),以及一个重要的交互(“点单”)——我们的工作流正是由它启动的。
要把订单提交给星巴克,我们只要把订单的表示(representation)POST给下面这个众所周知的星巴克点单URI即可: http://starbucks.example.org/order。
图3 点一杯咖啡
图3显示了向星巴克点单的交互过程。星巴克采用自己的XML格式来表达有关实体;需要关注的是,这个格式允许客户往里嵌入信息,以便进行点单——稍后我们会看到。实际提交的数据如图4所示。
在面向人类的Web(human Web)上,消费者和服务使用HTML作为表示格式(representation format)。HTML有自己特定的语义,所有浏览器都理解并接受这些语义,比如: 代表“一个链接到其他文档或本文档内部某个书签的锚(anchor)”。消费者应用——浏览器——只是呈现HTML,状态机(也就是你!)用GET和POST跟随链接。对于基于Web的集成也一样,只不过服务和消费者不仅要就交互协议达成一致,还要就表示的格式与语义统一意见。
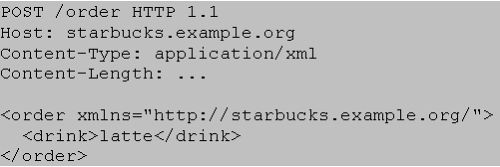
图4 POST饮品订单
星巴克服务创建一个订单资源,然后把这个新资源的位置放在HTTP报头Location里返回给消费者。为方便起见,服务还要把这个新创建的订单资源的表示(representation)也放在响应里。发给消费者的响应如下所示。
图5 创建好了订单,等待付款
201 Created状态表明星巴克已经成功接受了订单。Location报头给出了新创建订单的URI。响应主体里的表示(representation)包含了所点饮品及其价格。另外,这个表示里还包含另一个资源的URI——星巴克希望我们与这个URI交互,以完成顾客工作流;我们稍后将用到它。
注意,该URI是放在标签<next/>中、而不是标签<a/>中。这里的在顾客工作流里是具有特定含义的,其语义是事先定义好的。
我们已经知道201 Created状态代码表示“成功创建资源”的意思。对于这个例子以及一般的基于Web的集成,我们还需要其他一些有用的代码:
200 OK—— 它的意思是:一切正常,继续执行。
201 Created—— 我们刚刚创建了一个资源,一切正常。
202 Accepted—— 服务已经接受了我们的请求,并请我们对Location响应报头里的URI进行轮询(poll)。这在异步处理中相当有用。
303 See Other—— 我们需要跟另一个资源交互,应该不会出错。
400 Bad Request—— 我们的请求格式有问题,应重新格式化后再提交。
404 Not Found—— 服务因为偷懒(或者保密)没有告知请求失败的真实原因,但不管什么原因,我们都得应付它。
409 Conflict—— 服务器拒绝了我们更新资源状态的请求。我们需要获取资源的当前状态(要么检查响应实体主体,要么做一次GET操作),然后再作打算。
412 Precondition Failed—— 请求未被处理,因为Etag、If-Match或类似的“哨兵(guard)”报头的值不满足条件。我们需要考虑下一步怎么走。
417 Expectation Failed—— You did the right thing by checking, but please don't try to send that request for real.
500 Internal Server Error—— 最偷懒的响应。服务器出错了,而且什么原因都没说。祝你不要碰见它。
更新订单
星巴克很不错的一点就是,你可以按无数种不同的方式来定制自己的饮品。其实,考虑到某些高端客户极高的要求,也许让他们按化学公式来点单更好。但我们别那么贪心——至少开始的时候。我们来看另一张故事卡片:

回顾图4,显然我们在那里犯了一个错误:真正爱喝咖啡的人是不喜欢往浓咖啡里放太多热牛奶的。我们要改正那个问题。幸运地是,Web(或更确切地说,HTTP)以及我们的服务均为这样的改变提供了支持。
首先,我们要确认我们仍然可以修改订单。有时咖啡师动作很快,在我们想修改订单之前,他们就已经把咖啡做好了——于是,我们只有慢慢享用这杯热咖啡风味的牛奶了。不过,有时咖啡师会比较慢,这样我们就可以在订单得到咖啡师处理之前修改它了。为了知道我们是否还能修改订单,我们通过HTTP动词OPTIONS来向订单资源查询它接受哪些操作(如图6)。
| 请求 | 响应 |
OPTIONS /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK Allow: GET, PUT |
图6 看看有哪些选择(OPTIONS)
从图6我们可以知道,订单资源既是可读的(支持GET)、也是可更新的(支持PUT)。作为好网民,我们可以拿我们的新表示来做一次试验性的PUT操作,在真正PUT之前先用Expect报头来试一试(如图7)。
| 请求 | 响应 |
PUT /order/1234 HTTP 1.1 Host: starbucks.example.com Expect: 100-Continue |
100 Continue |
图7 看好再做(Look before you leap)
若我们不能修改订单了,那么对图7所示请求的响应将是417 Expectation Failed。不过,假定我们现在得到的响应是100 Continue,也就是说,我们可以用PUT来更新订单资源(如图8)。用PUT方法来提交更新后的资源表示(representation),实际上就相当于修改现有资源。在这个例子中,PUT请求里的新描述包含一个元素,其中包含我们的更新,即外加一杯浓咖啡。
尽管部分更新(partial updates)属于REST社区里比较难懂的理念争论之一,但这里我们采取一种实用的做法,我们假定:增加一杯浓咖啡的请求,是在现有资源状态的上下文中被处理的。因此,我们没必要在网络上传送整个资源表示,我们只要传送变化的部分即可。
图8 更新资源状态
如果我们能够成功提交(PUT)更新,那么我们会从服务器得到响应代码200,如图9所示。

图9 成功更新资源状态
检查OPTIONS和采用Expect报头并不能令我们避免碰到“后续的修改请求失败”的情况。因此,我们并不强制使用它。作为好网民,我们会以某种方式来应付405和409响应。
OPTIONS和Expect报头的使用应当被视为可选步骤。
尽管我们明智地使用Expect和OPTIONS,但有时PUT仍将失败;毕竟咖啡师也在一刻不停地工作——有时他们动作很敏捷!
若我们落后于咖啡师,我们在试图用PUT操作把更新提交给资源时会被告知。图10显示的就是一个常见的更新失败的响应。409 Conflict状态代码表明,若接受更新,将导致资源处于不一致的状态,所以没有进行更新。响应主体里显示出了我们试图PUT的表示(representation)与服务端资源状态之间的差异。按咖啡制作的话说,加得太晚了——咖啡师已经把热牛奶倒进去了。

图10 慢了一步
我们已经讲述了使用Expect和OPTIONS来尽量防止竞争条件。除此以外,我们还可以给我们的PUT请求加上If-Unmodified-Since或If-Match报头,以表达我们对服务的期望条件。If-Unmodified-Since采用时间戳,而If-Match采用原始订单的ETag1 。若订单状态自从被我们创建以来还没有改变过——也就是说,咖啡师还没有开始制作我们的咖啡——那么更新可以处理。若订单状态已经发生改变,那么我们会得到412 Precondition Failed响应。虽然我们因为慢了咖啡师一步而只能享用牛奶咖啡,但至少我们没有把资源转移到不一致的状态。
用Web进行一致的状态更新可以采取很多种模式。HTTP PUT是幂等的(idempotent),这样我们在进行状态更新时就用不着处理一些复杂事务了,不过仍有一些选择需要我们决定。下面是正确进行状态更新的一些方法:1. 通过发送
OPTIONS请求,查询服务是否接受PUT操作。这一步是可选的。它可以告知客户端,此刻服务器允许对该资源做哪些操作,不过这无法保证服务器将永远支持那些操作。2. 使用
If-Unmodified-Since或If-Match报头,以避免服务器执行不必要的PUT操作。假如PUT后来失败了,那么你会得到412 Precondition Failed。此方法要求:要么资源是缓慢更新的,要么支持ETag;对于前者就用If-Unmodified-Since,对于后者就用If-Match。3. 立即用
PUT操作提交更新,并应付可能出现的409 Conflict响应。就算我们使用了(1)和(2),我们可能仍得应付这些响应,因为我们的“哨兵”和检查本质上都是乐观的。关于检测和处理不一致的更新,W3C有一个非规范性文档,该文档推荐采用ETag。ETags也是我们推荐采用的方法。
在完成那些更新咖啡订单的艰苦工作之后,按理说我们应当得到额外那杯浓咖啡了。所以我们现在假定已设法得到了额外那杯浓咖啡。当然,我们要付过款后星巴克才会把咖啡递给我们(其实他们也已经暗示过了!),所以我们还需要一张故事卡片:

还记得最初那个针对原始订单的响应吗?其中有个元素。星巴克在订单资源的表示里面嵌入了有关另一个资源的信息。我们前面看过那个标签,但当时因为顾于修改订单就没有具体讲。现在我们应该进一步探讨它了:

关于next元素,有几点是值得指出的。首先,它处于一个不同的名称空间之下,因为状态迁移并不是只有星巴克需要。在这里,我们决定把这种用于状态迁移的URI放在一个公共的名称空间里,以便于重用(或甚至最终的标准化)。
其次,rel属性里嵌入了一则语义信息(你乐意的话,也可以称之为一种私有的微格式)。能够理解http://starbucks.example.org/payment这串文字的消费者,可以使用由uri属性标识的资源转移到工作流里的下一状态(付款)。
元素里的uri指向的是一个付款资源。根据type属性,我们已经知道预期的资源表示(representation)是XML格式的。我们可以向这个付款资源发送OPTIONS请求,看看它支持哪些HTTP操作。
微格式(microformat)是一种在现有文档里嵌入结构化、语义丰富的数据的方式。微格式在人类可读的Web上相当常见,它们用于往网页里增加结构化信息(如日程表)的表示(representations)。不过,它们同样也可以方便地被用于集成。微格式术语是在微格式社区里达成一致的,不过我们也可以自由创建自己的私有微格式,用于特定领域的语义标记。
尽管它们看上去没多大用,但如图10里那样的简单链接正是REST社区所呼吁的“将超媒体作为应用状态的引擎(hypermedia as the engine of application state)”的关键。更简单地说,URI代表了状态机里的状态迁移。正如我们在文章开始时所看到的,客户端是通过跟随链接的方式来操作应用程序的状态机的。
如果你一时不能理解,不要感到奇怪。这一模型的最不可思议之处在于:状态机和工作流不是像WS-BPEL或WS-CDL那样事先描述好的,而是在你经历各个状态的过程中逐步得到描述的。不过,一旦你想明白了,你就会发现,跟随链接(following links)这种方式使得我们可以在应用的各种状态下向前推进。每次状态迁移时,当前资源的表示里都包含了指向可能的下一状态的链接以及它们所代表的状态。另外,由于这些代表下一状态的资源是Web资源,所以我们知道如何使用它们。
在顾客工作流里,我们下一步要做的是为咖啡付款。我们可以由订单里的元素得知总金额,但在我们向星巴克付款之前,我们想向付款资源查询一下我们应当如何与之交互(如图11)。
消费者需要事先掌握多少关于一个服务的知识呢?我们已经说过了,服务和消费者在交互之前需要就它们将会交换的表示(representations)的语义达成一致。可以将这些表示格式(representation formats)看成一组可能的状态和迁移。在消费者与服务交互时,服务选择可用的状态和迁移,并构造下一个表示。步向目标的过程是动态发现的,而把这一过程中的各个部分串起来的方式是事先达成一致的。在设计与开发过程中,消费者会就表示和迁移的语义与服务器达成一致。但谁也不能保证服务在其演化过程中会不会采用一种客户端预期之外的表示和迁移 (不过客户端还是知道如何处理它的)——那是Web松耦合的本质特性。尽管如此,在这些情况下就资源格式和表示达成一致超出了本文的范围。
我们下一步要做的是为咖啡付款。我们可以由订单表示的元素得知总金额,所以我们要做的就是付款给星巴克,然后咖啡师把饮品交给我们。首先,我们向付款资源查询我们应当如何与之交互(如图11)。
| 请求 | 响应 |
OPTIONS/payment/order/1234 HTTP 1.1 Host: starbucks.example.com |
Allow: GET, PUT |
图11 获知如何付款
服务器返回的响应告诉我们,我们既可以读取付款(通过GET)、也可以更新它(通过PUT)。既然知道了金额,那么接下来,我们就把款项PUT给那个由付款链接标识的资源。当然,付款金额属于秘密信息,所以我们将通过认证2来保护该资源。
| 请求 |
PUT /payment/order/1234 HTTP 1.1 |
| 响应 |
201 Created |
图12 付款
为成功完成付款,我们只需按图12进行交互即可。一旦经认证的PUT返回一个201 Created响应,我们就可以庆祝付款成功、并拿到我们的饮品了。
不过事情也有出错的时候。当资金处于危险状态时,我们希望要么没出错、要么可以挽救错误3。付款时可能出现很多种容易想象的出错情况:
- 由于服务器宕机或其他原因,我们无法连接上服务器了;
- 在交互过程中,与服务器的连接被切断了;
- 服务器返回一个
4xx或5xx范围的错误状态。
幸运地是,Web可以帮助我们应付以上这些情况。对于前两种情况(假定连接问题是瞬间的),我们可以反复做PUT请求,直至我们收到成功响应为止。如果前次PUT操作已经得到了成功处理,那么我们将收到一个200响应(本质上是一个来自服务器的空操作确认);如果本次PUT操作成功完成了付款,那么我们将收到一个201响应。在第三种情况中,如果服务器返回的响应代码是500、503或504,那么也可以做同样处理。
4xx范围的状态代码比较难处理,不过它们仍然指出了下一步怎么办。例如,400响应表明我们通过PUT请求提交的内容无法被服务器所理解,我们需要纠正后重新发送PUT请求。403响应则相反,它表明服务器能够理解我们的请求,但不知道如何履行(fulfil)它,而且服务器希望我们不要重试。对于这些情况,我们得在响应的有效负载(payload)里寻找其他的状态迁移(链接),换其他推进状态的路线。
在这个例子中,我们已经多次使用状态代码来指引客户端步向下一个交互了。状态代码是具有丰富语义的确认信息。让服务返回有意义状态代码,并且令客户 端懂得如何处理状态代码,这样一来,我们便给HTTP简单的请求响应机制增加了一层协调协议,从而提高了分布式系统的健壮性和可靠性。
一旦我们为自己的饮品买了单,我们这个工作流就算完成了,有关顾客的故事也就到此结束了。不过整个故事还没有完。现在我们进入到服务里面,看看星巴克的内部实现。
咖啡师视角
作为顾客,我们乐于把自己放在咖啡世界的中央,不过我们并不是咖啡服务的唯一消费者。从与咖啡师的“时间竞赛”中我们已经得知,咖啡服务还为包括咖啡师在内的其他一些相关方面提供服务。按照我们循序渐进的介绍方式,现在该推出另一张故事卡片了。
用Web的格式与协议来描述饮品列表是件很容易的事。用Atom feed来表达列表之类的东西是相当不错的选择,它几乎可描述任何列表(比如未完成的咖啡订单),所以这里我们可以也采用它。咖啡师可以通过向该Atom提要的URI发送GET请求来访问它,对于未完成的订单,URI是http://starbucks.example.org/orders(如图13)。

图13 待制作饮品的Atom提要
星巴克是家相当繁忙的店,位于/orders的Atom feed更新相当频繁,所以咖啡师要不断轮询这个feed才能保证掌握最新信息。轮询通常被认为可伸缩性很差;但是,Web支持可伸缩性极强的轮询机制——我们稍后会看到。另外,由于星巴克每分钟要制作很多咖啡,所以承受住负荷是个重要问题。
这里我们有两个相抵触的需求。一方面,我们希望咖啡师通过经常轮询订单提要,以不断掌握最新信息;另一方面,我们又不希望给服务增添负担、或者徒然增加网络流量。为防止我们的服务因过载而崩溃,我们将在我们服务之外,用一个反向代理(reverse proxy)来缓存并提供被频繁访问的资源表示(如图14所示)。
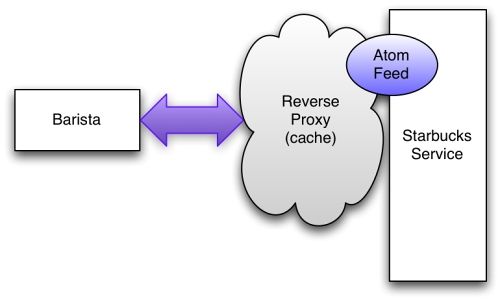
图14 通过缓存提升可伸缩性
对于大多数资源(尤其是那些会被很多人访问的资源,如返回饮品列表的Atom feed),在宿主服务之外缓存它们是合理的。这样可以降低服务器负载,提升可伸缩性。我们在架构里增设了Web缓存(反向代理),再加上有缓存元数据,这样客户端获取资源时就不会给原服务器增添很大负担了。
缓存的有利一面是,它屏蔽掉了服务器的间隙性故障,并通过提高资源可用率来帮助灾难恢复。也就是说,即便星巴克服务出现了故障,咖啡师仍然可以继续工 作,因为订单信息是被代理缓存起来的。而且,假如咖啡师漏了某个订单的话(错误),恢复也很容易进行,因为订单具有很高的可用率。
是的,缓存可以把旧订单多保留一段时间,但对于像星巴克这样吞吐量很高的商户而言,这是不太理想的。为了把太旧的订单从缓存中清除,星巴克服务用Expires报头来声明一个响应可以被缓存多久。任何介于消费者与服务之间的缓存都应当服从这一指示,拒绝提供过期订单4,而是把请求转发到星巴克服务上,以获取最新的订单信息。
图13所示的响应对Atom feed的Expires报头进行了相应的设置,令饮品列表在10秒钟后过期。由于这种缓存行为,服务器每分钟最多只要响应6次请求,其余请求将由缓存机制代劳。即便对于性能比较糟糕的服务,每分钟6个请求也属于容易处理的工作量了。在最愉快的情况下(对星巴克服务来说),咖啡师的轮询请求是由本地缓存响应的,这样就不会给增加网络活动或服务器负荷了。
在我们的例子中,我们只设置了一个缓存来帮助提升主咖啡列表的可伸缩性。然而,在真实的基于Web的场景中,我们可以从多层缓存中受益。要在大规模环境中提升可伸缩性,利用现有Web缓存的优点是至关重要的。
Web以延迟换取了高度的可伸缩性。假如你的问题对延迟很敏感的话(比如外汇交易),那么就不太适合采用基于Web的方案了。但是,假如你可以接受“秒”数量级上的延迟,那么Web也许是个不错的平台。
既然我们已经成功解决了可伸缩性问题,那么我们继续来实现更多的功能。当咖啡师开始为你制作咖啡时,应当修改订单状态,以达到禁止更新的目的。从顾客的角度来看,这相当于我们无法再对我们的订单执行PUT操作了(如图6、7、8、9、10所示)。
幸运地是,我们可以利用一个已经定义好的协议——Atom发布协议(Atom Publishing Protocol,简称APP或AtomPub)—— 来实现这一目标。AtomPub是一个以Web中心(基于URI)的协议,用于管理Atom feed里的条目(entries)。我们来仔细看看Atom提要(/orders)里代表咖啡的条目。

图15 咖啡订单对应的Atom条目
在图15所示的XML里,有几点值得注意。首先,它将我们的订单与Atom feed里的其他订单区分开了。其次,其中包含订单本身,即咖啡师制作咖啡所需的全部信息——包括我们要求增加一杯浓咖啡的重要信息。该订单对应的entry元素里有个link元素,它声明了本条目(entry)的编辑URI(edit)。这个编辑URI指向的是一个可以通过HTTP编辑的订单资源。(这里,可编辑资源的地址刚好跟订单资源本身的地址一样,不过这不是必须的。)
如果咖啡师要锁定订单资源、禁止它被修改,就可以通过该编辑URI来改变订单资源的状态。具体地讲,咖啡师可以用PUT请求把经修改的资源状态提交给这个编辑URI(如图16所示)。
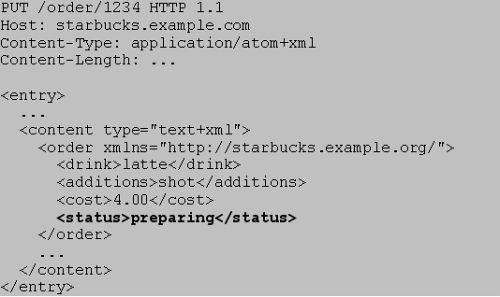
图16 通过AtomPub设置订单状态
服务器一旦处理了如图16所示的PUT请求,它就会拒绝对位于/orders/1234的订单资源做除GET以外的操作。
现在订单处于稳定状态了,咖啡师可以毫无顾虑地继续制作咖啡了。当然,咖啡师只有知道我们已经付过款才会把咖啡给我们,所以咖啡师还要查询我们是否已经完成付款。在真实的星巴克里,情况会略有不同:一般来说,我们是点单后立即付款的;然后,其他顾客站在周围,以免你拿走别人点的饮品。但在我们计算机化的版本里,增加这一检查并不麻烦,所以我们来看倒数第二张故事卡片:

咖啡师只要向付款资源(该资源的URI在订单表示里给出了)发送GET请求,即可查询付款状态。
这里,顾客和咖啡师是通过订单表示里给出的链接得知付款资源的URI的。但有时,通过URI模版来访问资源也很方便。
URI模版(URI template)是一种描述URI的格式。它允许消费者通过修改URI里的部分字符来访问不同的资源。
Amazon的S3存储服务就是基于URI模版的。用户可以对由模版生成的URIs进行HTTP操作,从而对已保存的制品进行操作:
http://s3.amazonaws.com/{bucket_name}/{key_name}。为方便咖啡师(或其他经授权的星巴克系统)不用遍历所有订单即可访问各个付款资源,我们可以在我们的模型里设计一个类似的URL模版方案:
http://starbucks.example.org/payment/order/{order_id}。URI模版就像与消费者订立的契约,服务提供者须在服务演化过程中注意维持它们的稳定。由于这一潜在的耦合,有些Web集成工作者会有意避免采用URI模版。我们的建议是,仅当可推断的URIs(inferable URIs)很有帮助而且不会改变时才使用。
对于我们的例子,另一种办法是在
/payments处暴露一个feed,用它提供包含指向各个付款资源的(不可推断的)链接。该提要只有经授权的系统才能读取。最终,URI模版是不是一个相对超媒体来说安全而有效的捷径,要由服务设计者来决定。我们的建议是:要保守地使用URI模版。
当然,不是人人都可以查看付款信息的。我们不想让咖啡社区里会动歪脑筋的人查看他人的信用卡详细信息,因此,跟其他敏感的Web系统一样,我们利用请求认证来保护敏感资源。
如有未认证的用户或系统试图获取一个具体的付款信息,那么服务器会质询(challenge)它、要求它提供证书。(如图17)
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org |
401 Unauthorized WWW-Authenticate: Digest realm="starbucks.example.org", qop="auth", nonce="ab656...", opaque="b6a9..." |
图17 对付款资源的非授权访问受到质询
401状态(及其认证元数据)告诉我们,我们应当在请求里附上正确的证书、然后重新发送请求。重新用正确的证书发送请求(图18)后,我们得到了付款信息,并将之与代表订单总金额的资源http://starbucks.example.org/total/order/1234进行比较。
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org Authorization: Digest username="barista joe" realm="starbucks.example.org“ nonce="..." uri="payment/order/1234" qop=auth nc=00000001 cnonce="..." reponse="..." opaque="..." |
200 OK |
图18 授权访问付款资源
一旦咖啡师制作好、交出咖啡并完成收款,他们就要在待处理饮品列表中删除相应的订单。如同前面一样,我们采用一个故事来讲解这个回合:

因为订单feed里的各个条目(entry)都标识着一个可编辑资源,而且有自己的URI,所以我们可以对各个订单资源做HTTP操作。如图19所示,咖啡师只要对相关条目(entry)所引用的资源做DELETE操作即可将它从列表中删除。
| 请求 | 响应 |
DELETE /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK |
图19 删除已完成的订单
在条目被删除(DELETE)之后,再对订单提要做GET操作的话,返回的表示里将不再包含已删除(DELETE)的资源。假定我们的缓存工作正常、且我们已经设置了合理的缓存过期元数据的话,那么当你试图获取(GET)那个订单条目时将直接得到404 Not Found响应。
也许你已经注意到了,Atom发布协议可以满足我们对星巴克这个问题的大部分需求。如果我们想直接把位于/orders的Atom提要暴露给顾客的话,顾客就可以用Atom发布协议来向该提要发布饮品订单、甚至修改订单了。
演化:Web上的现实情况
因为我们的咖啡店是基于自描述的状态机(state machines)构建起来的,所以我们可以方便地根据业务需要改造我们的工作流。例如,星巴克也许会提供一种免费的网上促销活动:
- 7月——我们的星巴克店开业,提供标准的工作流以及我们前面提到的状态迁移和表示(representation)。消费者知道用这些格式与表示跟我们的服务进行交互。
- 8月——星巴克新推出了一种免费网上促销的表示(representation)。我们的咖啡工作流将进行更新,以包含指向该网上促销资源的链接。由于URI的特性,链接可以是指向第三方的——这跟指向星巴克内部的资源一样简单。

-
因为表示里仍然包含原来的迁移点,所以现有消费者仍然可以实现它们的目标,只不过它们可能无法享受促销而已,因为这部分还没有写进它们的代码里去。
- 9月——消费者应用和服务都进行了有关升级,以便能够理解并使用免费的网上促销。
成功进行演化的关键在于,服务的消费者们要能够预料到改变。在每一步,服务不是直接跟资源绑定(例如通过URI模版),而是提供指向具名资源(named resources)的URIs,以便消费者与之交互。这些具名资源,有些是消费者不认识的、将被忽略的,有些是消费者已知的、想采用的状态迁移点。不管采用哪种方式,这种方案使得服务可以优雅地演化,同时还能维持与消费者兼容。
你将使用的是一个相当热门的技术
交付咖啡是我们工作流的最后一步。我们已经点了单、修改了订单(也可能无法修改)、付过款并最终拿到了我们的咖啡。在柜台另一侧,星巴克也已经同样完成了收款和订单处理。
我们可以用Web来描述所有必需的交互。我们可以利用现有的Web模型处理一些简单的不愉快的事(例如无法修改处理中或已处理完毕的订单),而不必自己发明新的异常或错误处理机制——我们所需的一切都是HTTP现成提供的。而且,即便发生了那些不愉快的事,客户端仍然可以向它们的目标迈进。
HTTP提供的特性起初看来是无关紧要的。但这个协议现在已经取得广泛的一致、并得到广泛的部署了,而且所有的软件与硬件都能一定程度上理解它。当我们看到其他分布式计算技术(如WS-*)处于割据状态的格局时,我们意识到了HTTP享有的巨大成功,以及它在系统间集成方面的潜力。
甚至在非功能性方面,Web也是有益的。在我们碰到临时故障时,HTTP操作(GET、PUT和DELETE)的幂等性质令我们可以进行安全的重试;内在的缓存机制既屏蔽了故障,又有助于灾难恢复(通过增强的可用率);HTTPS和HTTP认证有助于基本的安全需求。
尽管我们的问题域是人为制造的,但我们所强调的技术同样可以应用于分布式计算环境。我们不会伪称Web很简单(除非你是天才),Web可以解决一切问题 (除非你是超级乐观的人,或受到REST信仰的感染),但事实上,在局部、企业级和Internet级进行系统集成,Web是个健壮的框架。
致谢
本文作者要向英国卡迪夫大学(Cardiff University)的Andrew Harrison表示感谢,是他启发了我们就Web上的“对话描述”进行讨论。
About the Authors
Jim Webber博士是ThoughtWorks公司的专业服务主管,他的工作是为全球客户进行可靠的分布式系统架构设计。此前,Jim担任英国E-Science计划高级研究员,从事将Web服务实践及可靠面向服务计算的架构模式应用于网格计算的战略设计工作,他在Web及Web服务架构与 开发方面具有广泛的经验。Jim还担任过惠普公司和Arjuna公司的架构师,他是业界首个Web服务事务方案的首席开发者。Jim是一位活跃的演说家, 他经常受邀出席国际会议并发言。他还是一位活跃的作家,除了《Developing Enterprise Web Services - An Architect's Guide》这本书外,目前他正在撰写一本关于基于Web的集成的新书。Jim获得英国纽卡斯尔大学(University of Newcastle)的计算机科学学士学位和并行计算博士学位。他的博客地址是:http://jim.webber.name。
Savas Parastatidis是一位软件思想家,他的思考领域涉及系统和软件。他研究技术在eResearch里的运用,他尤其对云计算、知识表示与管理、社会网络感兴趣。他目前任职于微软研究院合作研究部。Savas喜欢在http://savas.parastatidis.name上写博客。
Ian Robinson帮助客户们创建可持续的面向服务的能力,令业务与IT从开始到实际运营始终保持齐合。他为微软公司写过关于采用微软技术实现面向服务系统的指南,还发表过文章讲述消费者驱动的服务契约及其在软件开发生命周期中的作用——该文章可以在《ThoughtWorks文集(The ThoughtWorks Anthology)》(Pragmatic Programmers,2008)及InfoQ中文站上找到。他经常在会议上做有关REST式企业开发及面向服务交付的测试驱动基础的讲演。
1. ETag(Entity Tag的简写)是资源状态的唯一标识符。一个资源的ETag通常是根据该资源的数据得到的MD5校验和或SHA1哈希值。
2. 我们将从稍后的星巴克例子中了解认证的工作原理。
3. 当然,如果安全性遭到威胁,我们只要防止事情不要错得更厉害就行了!但得到咖啡并不是一项攸关安全的任务,尽管每天早晨我的同事们可能会这么认为!
4. HTTP 1.1提供了一些有用的请求指令,比如max-age、max-stale和max-fresh,它们允许客户端指出愿意接受缓存里多旧的数据。