使用WireShark抓包分析Android网络请求时间(二)
上一篇文章简单介绍了一下WireShark这个软件的用法,并分析了一下在网络条件好的情况下,使用宽带+浏览器请求一个数据接口并抓取相关报文,但是有一个重要的问题没有解决,就是在网络状态不好的时候,到底是哪一步让app获取数据的http请求过慢,今天就使用无线网络和安卓模拟器真实的模拟一下用户的情况。
对WireShark不了解的童鞋请看这里:使用WireShark抓包分析Android网络请求时间(一)
这一篇主要剖析在服务器和客户端程序运转良好的情况下,为什么还会出现一次http请求数十秒甚至超过1分钟的情况
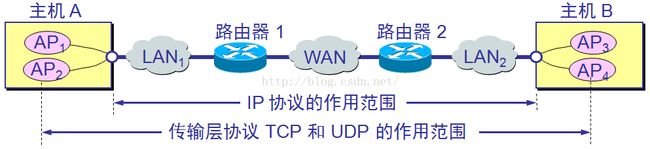
首先我们要了解一下TCP协议的特点:
面向连接的传输协议:数据传输之前必须先建立连接,数据传输完成之后,必须释放连接。
仅支持单播传输:每条传输链接只能有两个端点,只能进行点对点的连接,不支持多播和广播的传输方式,UDP是支持的
提供可靠的交付服务:传输的数据无差错,不丢失,不重复,且顺序与源数据一致
传输单位是数据段:每次发送的数据段不固定,受应用层传送报文大小和网络中的MTU(最大传输单元)值大小的影响,最小数据段可能仅有21个字节(其中20个字节属于TCP头部,数据部分仅1字节)。
支持全双工传输:通信双方可以同时发数据和接收数据
TCP连接是基于字节流的:UDP是基于报文流的。
单独说TCP可能记不深刻,对比一下UDP协议就很容易理解TCP的特性:
UDP协议的特点:
1、无连接型
2、不可靠性
3、以报文为便捷
4、无流量控制和拥塞控制方案
5、支持单播,组播,广播等多种通讯方式
TCP是如何保证数据可靠性的:
TCP是一个可以保证可靠数据传输的传输层协议,主要采用采用以下四个机制实现数据可靠性传输:
1、字节编号机制:TCP数据段以字节为单位对数据段的"数据"部分进行一一编号,确保每一个字节的数据都可以有序传送和接收.
2、数据段确认机制:每接收一个数据段都必须有接收端向发送端返回确认数据段,其中的确认号表示已经正确接收的数据段序号.
3、超时重传机制:TCP中有一个重传定时器(RTT),发送一个数据段的同时也开启这个定时器,如果定时器过期之时还没有返回确认,则定时器停止,重传该数据.
4、选择性确认机制:(Selective ACK,SACK)/只重传缺少部分的数据,不会重传那些已经正确接收的数据.

TCP的流量控制:
需要进行流量控制的原因就是,数据发送的太快,接收端来不及接收而出现的丢包状况.流量控制的目的也就是不要让发送端的发送的数据大于接收端的数据处理能力.
TCP的流量控制通过滑动窗口机制来进行,窗口的大小的单位是字节.
在TCP首部有一个窗口字段(见上图TCP首部),这个字段的数值就是给对方设置的发送窗口的上限,发送窗口在连接时由双方商定,但在通信过程中,接收端可以依据自己的资源状况,动态的调整对方发送窗口的值的大小,达到控制的目的.
假设每个字段大小为100字节,当前发送窗口大小是400字节,发送端已经发送了400字节的数据,但是仅收到前200个字节的确认信息,还有200个字节没有发来确认,那么发送窗口当前时刻还能发送300字节,于是发送窗口前移,整个过程如图所示.是一个简单的滑动窗口的情况.
下面来实地演示一下Http请求时间过长的情况
然后在模拟器里执行相应动作调用相应url获取数据,然后来看看WireShark抓到了什么
tips:一个app程序可能会一次调用多个url接口,多次http请求可能会让你的WireShark捕捉到很多没用的报文,处理方法是,先找到一条你确定是有用的报文,在这条报文里找到本机的请求端口,然后用筛选语句筛选一下就行了,比如我这里写的是
ip.addr == 54.254.105.138 and tcp.port == 63208
其中63208就是本次请求首页我模拟器使用的端口,因为访问不同的url使用的是不同的端口,所以这样筛选就可以把本次请求特定url的全部报文给筛选出来了,至于发现63208这个接口,我是通过寻找GET /app/home....这条报文的端口来确定的。
下面来简单的观察一下本次http请求的全部报文
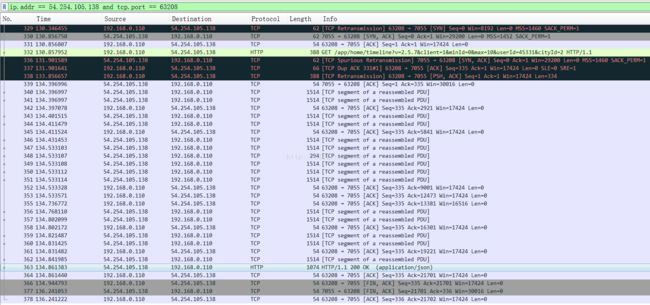
一个小技巧,如果WireShare经常出现如上图这种黑色的报文,往往说明了网络链路情况不好
从上图可以看出,本次HTTP请求主要分了一下几个步骤
三次握手-->发送GET请求-->服务器发送数据给客户端-->四次挥手
其中与电脑上浏览器不同的就是没有了KEEP ALIVE过程,整个过程耗时136.241222-130.346455=5.894767s 看起来比较长了,那么相对于网络优秀的时候,时间都花在哪了呢
其中,三次握手耗时:133.856657-130.346455 = 3.510202s
服务器发送给客户端耗时:134.861383-133.856657=1.004726s
服务器响应数据耗时:134.396996-133.856657 = 0.540339s
json数据传输耗时1.004726-0.540339 = 0.464387s
四次挥手耗时136.241222-134.861440=1.379782s
从这里可以看出,虽然数据量很大,但是服务器反应加上数据传输,一共才使用的一秒钟,但是仅三次握手就消耗了3.5s,而在上篇文章中,三次握手一共才使用了几百毫秒而已,下面来分析一下为什么三次握手时间这么长
第一条报文就是一条重传,说明WireShark漏抓了一条报文,而漏掉的这一条报文,就是客户端的第一次握手,由于第一次握手没有按时收到服务器的SYN+ACK报文,所以客户端又重新进行三次握手,于是就有了第一条黑色的报文
本来在第332号报文就结束了三次握手,为什么又会有底下三条黑色的重传报文呢?
首先336号报文,也就是三次握手完毕之后的第一条黑色报文是一条SYN+ACK报文,这不是三次握手中的第二次握手么,鉴于之前客户端第一次握手没有按时收到第二次握手,我们可以看出来:第一次握手的请求发送到了服务器,服务器也进行了响应,但是可能由于网络链路原因,服务器的第二次握手没有按时到达客户端,导致客户端又发起了一次握手。
于是,329号报文应该和336号是一对,客户端在收到336号报文之后又发送了338号ACK报文完成第二次三次握手.
根据这次抓包情况来看,三次握手进行了两次,而且第一次超时了,所以导致本次HTTP通信时间延长
如果是因为网络状态不好导致三次握手偶尔失败一下下也是可以理解的,毕竟这是无线网络,三次握手的失败是没法避免的,而且这次仅仅才重传了一遍,整个http过程耗时才不到6秒,也是可以接受的,但是客户说这次事态特别严重,有时候要好几分钟才打的开,于是我决定继续抓包。
这次抓到一个时间更变态的,40多秒的一个请求,贴出来给大家看看
同样还是分为那几个步骤
三次握手-->发送GET请求-->服务器发送数据给客户端-->四次挥手
但这次耗时:-17.448265-(-53.072654) = 35.624389s 比上次长得多,从图上一大堆的黑条可以看出来,出现了大量的丢包,重传,乱序的现象
这次三次握手:-46.712363-(-53.072654)= 6.360291s,其中,第一次和第二次握手间隔时间最长,第一次和第三次握手都重传了一遍,说明网络状况比上面那次测试还要糟糕的多,仅三次握手就用了6s
另外服务器的发回第一条数据的时间也明显延长,-43.052092-(-49.716953) = 6.664861s,换句话说就是在服务器确认了三次握手之后,又用了6秒多的时间才将数据准备好并且发送回来首条数据
根据以往了经验来看,服务器会先发送一条长度为54的报文,然后发送许多长度为1514的报文,然后客户端每收到两条长度1514报文后反馈一条报文,然后再这样来一遍直到发完为止
客户端也许不会在服务器3条报文发送过后立即反馈,但是也不会少反馈
根据上图来看,客户端先收到了1514的报文,没有收到的54的报文,而且又进行了许多retransmission 并且收到了很多重复报文,导致整个tcp数据传输的效率大为降低,丢包率也是极高
再科普一下:
“TCP Previous segment not captured] 说明乱序了,前一个包没有收到,收到后面的包了,这时会重传包
[TCP Retransmission] 超时重新发送,当发送方送出一个TCP片段后,将开始计时,等待该TCP片段的ACK回复。如果接收方正确接收到符合次序的片段,接收方会利用ACK片段回复发送方。发送方得到ACK回复后,继续移动窗口,发送接下来的TCP片段。如果直到计时完成,发送方还是没有收到ACK回复,那么发送方推断之前发送的TCP片段丢失,因此重新发送之前的TCP片段。这个计时等待的时间叫做重新发送超时时间——http://www.myexception.cn/h/545728.html
[TCP segment of a reassembled PDU] 如果发送的包比最大的报文段长度长的话就要分片了,被分片出来的包,就会被标记了成TCP segment of a reassembled PDU,被标记了的包的SEQ和ACK都和原来的包一致
[TCP Dup Ack],一般来说是网络拥塞导致丢包,比如发送方的报文到达不了接收方,接受方收不到预期序列号的报文就会发送dup ack给发送方,发送方收到3个dup ack就会快速重传而不必等超时定时器。——来自知乎
[TCP Fast Retransmission] 快速重新发送 ,由于IP包的传输是无序的,所以接收方有可能先收到后发出的片段,也就是乱序(out-of-order)片段。乱序片段的序号并不等于最近发出的ACK回复号。已接收的文本流和乱序片段之间将出现空洞(hole),也就是等待接收的空位。比如已经接收了正常片段5,6,7,此时又接收乱序片段9。这时片段8依然空缺,片段8的位置就是一个空洞。TCP协议规定,当接收方收到乱序片段的时候,需要重复发送ACK。比如接收到乱序片段9的时候,接收方需要回复ACK。回复号为8 (7+1)。此后接收方如果继续收到乱序片段(序号不是8的片段),将再次重复发送ACK=8。当发送方收到3个ACK=8的回复时,发送方推断片段8丢失。即使此时片段8的计时器还没有超时,发送方会打断计时,直接重新发送片段8,这就是快速重新发送机制(fast-retransmission)。——http://www.myexception.cn/h/545728.html
上面那个案例是网络连接非常不稳定的情况,尤其是3次握手和数据回传都会出现问题,太极端了,其实在不考虑握手失败的情况下,把5-6秒的请求优化到1秒之内,用户体验就已经极佳了,剩下的就是数据库优化和运维的问题了。下面给出一个网络不快不慢时候的情况,主要是丢包造成了时间的延时

其实这才是优化的重点,在三次握手成功之后减少丢包率以加快速度,而如何减少丢包率,比如增加服务器的节点,减少链路的距离和经过的节点数,并不明显,因为很多数据死在了"最后一公里",比如光纤进入小区后进入交换机和路由器进行分发,容易想象如果一个教室100个人共用一个路由器的话必然很卡。所以最重要的是,减少数据吞吐量,通过减少数据量来减少丢包重传造成的时间开销是最明显的。