网页去重(三)之特征值的提取
网页去重(三)特征值
一、 什么是特征值
下面收集来自百度百科的资料:
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF *IDF,TF词频(TermFrequency),IDF逆向文件频率(InverseDocument Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语来说,它的重要性可表示为:
· ![]()
以上式子中分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
·
其中
· |D|:语料库中的文件总数
· :包含词语的文件数目(即的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用![]()
作为分母。
idf公式分母
然后再计算TF与IDF的乘积。
·
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。[2]
---摘自百度百科
例1
有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率(IDF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03* 4=0.12。
二、 算法实现
2.1 获取TF算法并排序:
public static voidgetTF(String inputFile, String outputFile){
String result ="";
List<String> lists = StringUtil.getListContentFromPath(inputFile);
Double allNums = (double)lists.size();
for(String w: lists){
int num = StringUtil.getWordNum(w,lists);
Double TF = num/allNums;
result += w+""+TF+ConstantString.WIN_NextLine;
}
StringUtil.String2File(result,outputFile);
}
*/
public static voidsortWords(String inputFile, String outputFile){
Map<String ,Double> map = getMapFromFile(inputFile);
Map<String ,Double> resultmap = SortUtil.sortMapByValue(map,true);
String result ="";
for(Stringkey : resultmap.keySet()){
result += key+""+resultmap.get(key)+ConstantString.WIN_NextLine;
}
StringUtil.String2File(result,outputFile);
}
截图:
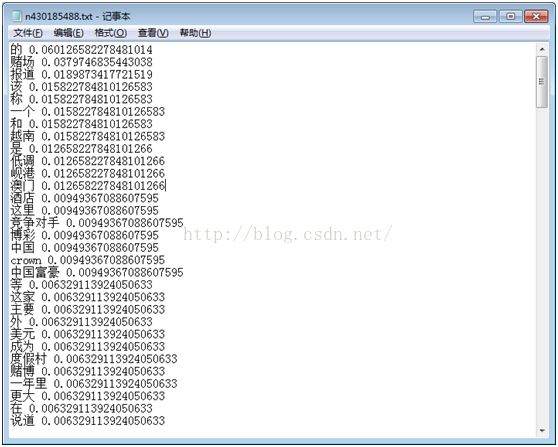
2.2获取DF算法:
/**
* 获取单个文件的DF
* @paraminputFileStr
* @paraminputPathAll
* @paramoutputDirStr
* @throwsException
*/
public static voidgetDF(String inputFileStr,String inputPathAll,String outputDirStr) throwsException{
File inputFile = newFile(inputFileStr);
File outputDir = newFile(outputDirStr);
if(!inputFile.exists()){
throw newException("can not read the inputDir");
}
if(!outputDir.exists()){
outputDir.mkdirs();
}
String result ="";
try {
ArrayList<String> paths = newStringUtil().getAllPath(inputPathAll);
Double df = 0.0;
FileInputStream fis = newFileInputStream(inputFile);
BufferedReader br = newBufferedReader(new InputStreamReader(fis));
String name = StringUtil.getNameFromPath(inputFileStr);
String outputFileStr =outputDirStr+ConstantString.slash+name+ConstantString.postText;
String temp ="";
while((temp =br.readLine()) != null){
String[] temps = temp.split("");
df = 0.0;
for(Stringpath : paths){
String content = StringUtil.getContent(path);
if(content.contains(temps[0])){
df++;
}
}//for
result += temp+""+df+ConstantString.WIN_NextLine;
}
StringUtil.String2File(result,outputFileStr);
} catch(Exception e) {
e.printStackTrace();
}
}
截图:
3.3 计算TF*IDF算法:
/**
* 获取TF*IDF
* @paraminputFileStr
* @paraminputPathAll
* @paramoutputDirStr
* @throwsException
*/
public static voidgetTFIDF(String inputFileStr,String outputDirStr,inttotalnum) throws Exception{
File inputFile = newFile(inputFileStr);
File outputDir = newFile(outputDirStr);
if(!inputFile.exists()){
throw newException("can not read the inputDir");
}
if(!outputDir.exists()){
outputDir.mkdirs();
}
String result ="";
try {
Double nums = (double)totalnum;
Double tfidf = 0.0;
FileInputStream fis = newFileInputStream(inputFile);
BufferedReader br = newBufferedReader(new InputStreamReader(fis));
String name = StringUtil.getNameFromPath(inputFileStr);
String outputFileStr =outputDirStr+ConstantString.slash+name+ConstantString.postText;
String temp ="";
while((temp =br.readLine()) != null){
String[] temps = temp.split("");
Double idf = Math.log(nums/Double.valueOf(temps[2]));
tfidf = Double.valueOf(temps[1])*idf;
result += temp+" 特征值:"+tfidf+ConstantString.WIN_NextLine;
}
StringUtil.String2File(result,outputFileStr);
} catch(Exception e) {
e.printStackTrace();
}
}
原文:
