你不知道的全文检索---solr安装中文分词器及配置业务字段
你不知道的全文检索---solr安装中文分词器及配置业务字段
在solr中默认的使用的是英文分词,所以需要手工配置中文分词器,需要我们配置一个FieldType,在FieldType中指定中文分词器。
配置中文分词器
1、使用IK-Analyzer上传至服务器、解压
IKAnalyzer2012FF_u1.jar 分词器jar包
IKAnalyzer.cfg.xml 分词器配置文件
Ext_stopword.dic 分词器停词字典,可自定义添加内容
mydict.dic 自定义词典
2、将分词器jar包传至solr服务器中
[root@localhost IK Analyzer 2012FF_hf1]# cpIKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
3、需要把IKAnalyZer需要的扩展词典以及停用词典、配置文件放在solr服务器的WEB-INF文件夹的下的classes文件夹。
即将IKAnalyzer.cfg.xml、ext_stopword.dic、mydict.dic、复制到 Tomcat的webapps/solr/WEB-INF/classes
注意:ext_stopword.dic 和mydict.dic必须保存成无BOM的utf-8类型。
4、配置fieldType,需要在solrhome/collection1/conf/schema.xml中配置。在该文件的最后加上如下配置:
<fieldType name="text_ik"class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
经过上面的配置就将中文分词器配置好了,下面我们来配置业务字段
配置业务字段
业务需求
我们需要通过讲师的姓名、昵称,讲师的所在及,讲师的擅长领域、擅长行业,讲师所讲课程的名称等信息来查询讲师。
业务字段判断标准
1、 在搜索时是否需要在此字段上进行搜索。例如:讲师姓名、昵称
2、 后续的业务是否需要用到此字段。例如:讲师Id
需要用到的字段
讲师Id
昵称
公司
职务
身份
擅长领域
擅长行业
常驻地
简介
Solr中的业务字段
id—>讲师Id,其他配置如下:
<field name="nickName"type="string" indexed="true" stored="true"/> <fieldname="realName" type="string" indexed="true"stored="false"/> <fieldname="courseName" type="text_ik" indexed="true"stored="false" multiValued="true"/> <fieldname="fieldName" type="string" indexed="true"stored="true" multiValued="true"/> <fieldname="pointWord" type="string" indexed="true"stored="false" multiValued="true"/> <fieldname="industryName" type="string" indexed="true"stored="true" multiValued="true"/> <fieldname="companyAddress" type="text_ik"indexed="true" stored="true"/> <fieldname="companyName" type="text_ik" indexed="true"stored="true"/> <fieldname="companyJob" type="text_ik" indexed="true"stored="true"/> <fieldname="headPic" type="text_general" indexed="true"stored="true"/> <fieldname="item_keywords" type="text_ik" indexed="true"stored="false" multiValued="true"/> <copyFieldsource="nickName" dest="item_keywords"/> <copyFieldsource="realName" dest="item_keywords"/> <copyFieldsource="courseName" dest="item_keywords"/> <copyFieldsource="industryName" dest="item_keywords"/>
注意:stored表示是否需要存储,复制域,将其他域上的字段复制到复制域上,可以优化查询效率。
重启tomcat就可以看到我们设置的字段了如下图:
再看看分词器是否安装成功,如下图:
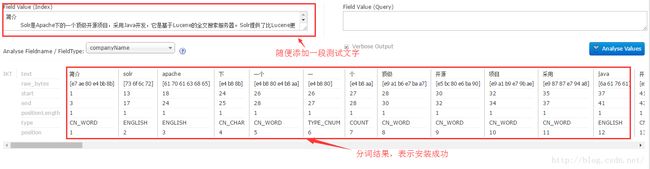
至此solr的中文分词器,以及业务字段配置的工作就完成了,当然在配置scheme.xml中还有需要注意事项会在之后的高级应用中一一说明,希望本文对正在接触全文检索的读者有所帮助。