IKAnalyzer 扩展词典(强制分词)【solr里添加扩展词典,扩展词典的格式必须是 utf-8 的无BOM格式编码。jav开发中 IKAnalyzer.cfg.xml必须在类路径根下】
文章来源:http://blog.csdn.net/longxia1987/article/details/8179665
前面说到solr+IKAnalyzer来配置中文分词;在实际中我们有些需求是需要将特定的词作为一个分词来处理,那么我们就需要设置自己的词典
例子:连帽上衣
希望将 “连帽” 作为一个词来处理,并不希望作为 连,帽 来处理
默认分词:

做法:
IKAnalyzer.cfg.xml放到solr的tomcat中:..../webapp/WEB-INF/classes/IKAnalyzer.cfg.xml,并配置 IKAnalyzer.cfg.xml文件
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
- <properties>
- <comment>IK Analyzer 扩展配置</comment>
- <!--用户可以在这里配置自己的扩展字典-->
- <entry key="ext_dict">/mydict.dic;</entry>
- <!--用户可以在这里配置自己的扩展停止词字典-->
- <entry key="ext_stopwords">/ext_stopword.dic</entry>
- </properties>
我是将 mydict.dic 文件和 IKAnalyzer.cfg.xml 放在同一个目录,也可以放在别的地方,配置好路径就可以了
mydict.dic 文件中就只有“连帽” 这个词;
经典问题来了:mydict.dic 必须是 utf-8 的无BOM格式编码。
配置好之后重启solr,再次查看分词:
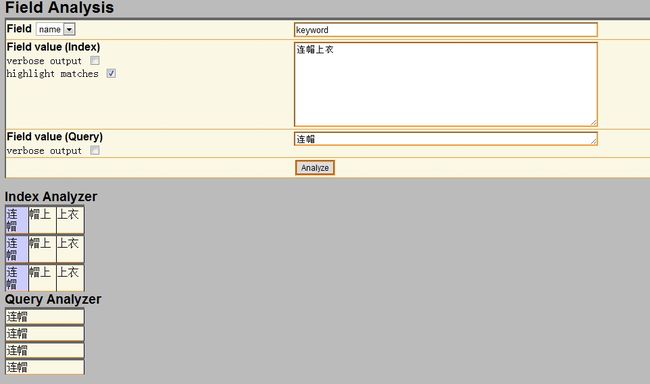
这样连帽就能匹配的到了。
搞了好久,才知道是文件的编码格式不对。我日的,还必须是无BOM格式。
=====================================java代码中==============================================
代码结构:
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!-- 用户可以在这里配置自己的扩展停用词字典【中文停用词或者英文停用词】 -->
<entry key="ext_stopwords">chinese_stopword.dic;english_stopword.dic</entry>
</properties>
扩展词典ext.dic内容:
传智播客 本拉登 击毙 欧洲杯四强赛 连帽上衣java测试代码:
<span style="white-space:pre"> </span>String content =new String("我穿着连帽上衣去看2012年欧洲杯四强赛;传智播客的本拉登被击毙了".trim().getBytes(),"utf8");
StringReader sr =new StringReader(content);
IKSegmenter ikSegmenter =new IKSegmenter(sr, true);
Lexeme word=null;
while( (word=ikSegmenter.next()) !=null ){
String w= word.getLexemeText();
System.out.println(w);
}
输出结果:
<span style="color:#333333;">加载扩展词典:ext.dic 加载扩展停止词典:chinese_stopword.dic 加载扩展停止词典:english_stopword.dic 我 穿着 </span><span style="color:#cc0000;">连帽上衣</span>【<span style="font-family: Arial; color: rgb(51, 51, 51);">没有添加扩展词的时候,结果是“连帽”,“上衣”</span><span style="font-family: Arial;">】</span> <span style="color:#333333;">去看 2012年 </span><span style="color:#cc0000;">欧洲杯四强赛</span><span style="color: rgb(204, 0, 0); font-family: Arial;">【</span><span style="font-family: Arial; color: rgb(51, 51, 51);">没有添加扩展词的时候,结果是“欧洲杯”,“四强赛”</span><span style="color: rgb(204, 0, 0); font-family: Arial;">】</span><span style="color:#cc0000;"> </span><span style="color:#cc0000;">传智播客</span><span style="color:#333333;">【没有添加扩展词的时候,分开四个字"传""智""播""客"】 的 </span><span style="color:#cc0000;">本拉登</span><span style="color:#333333;"> 被 </span><span style="color:#cc0000;">击毙</span><span style="color:#333333;"> 了 </span>