Oracle 高水位(HWM: High Water Mark) 说明
一. 准备知识:ORACLE的逻辑存储管理.
ORACLE在逻辑存储上分4个粒度: 表空间, 段, 区 和 块.
1.1 块: 是粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操作也是按块来操作的,也就是说当ORACLE从数据文件读数据时,是读取多少个块,而不是多少行. 每一个Block里可以包含多个row.
1.2 区: 由一系列相邻的块而组成,这也是ORACLE空间分配的基本单位,举个例子来说,当我们创建一个表Dave时,首先ORACLE会分配一区的空间给这个表,随着不断的INSERT数据到Dave,原来的这个区容不下插入的数据时,ORACLE是以区为单位进行扩展的,也就是说再分配多少个区给Dave,而不是多少个块.
1.3 段: 是由一系列的区所组成, 一般来说, 当创建一个对象时(表,索引),就会分配一个段给这个对象. 所以从某种意义上来说,段就是某种特定的数据.如CREATE TABLE Dave,这个段就是数据段,而CREATE INDEX ON Dave(NAME), ORACLE同样会分配一个段给这个索引,但这是一个索引段了.查询段的信息可以通过数据字典: SELECT * FROM USER_SEGMENTS来获得.
1.4 表空间: 包含段,区及块.表空间的数据物理上储存在其所在的数据文件中.一个数据库至少要有一个表空间.
表空间(tableSpace) 段(segment) 盘区(extent) 块(block) 关系
http://blog.csdn.net/tianlesoftware/archive/2009/12/08/4962476.aspx
当我们创建了一个表,即使我没有插入任何一行记录, ORACLE还是给它分配了8个块. 当然这个跟建表语句的INITIAL 参数及MINEXTENTS参数有关. 如:
STORAGE
(
INITIAL 64K
MINEXTENTS 1
MAXEXTENTS UNLIMITED
);
也就是说,在这个对象创建以后,ORACLE至少给它分配一个区,初始大小是64K,一个标准块的大小是8K,刚好是8个BLOCK.
Oracle Table 创建参数说明
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4954417.aspx
二. 高水线(High Water Mark)
2.1 官网说明如下
http://download.oracle.com/docs/cd/E11882_01/server.112/e16508/logical.htm#CNCPT89022
To manage space, Oracle Database tracks the state of blocks in the segment. The high water mark (HWM) is the point in a segment beyond which data blocks are unformatted and have never been used.
MSSM uses free lists to manage segment space. At table creation, no blocks in the segment are formatted. When a session first inserts rows into the table, the database searches the free list for usable blocks. If the database finds no usable blocks, then it preformats a group of blocks, places them on the free list, and begins inserting data into the blocks. In MSSM, a full table scan reads all blocks below the HWM.
ASSM does not use free lists and so must manage space differently. When a session first inserts data into a table, the database formats a single bitmap block instead of preformatting a group of blocks as in MSSM. The bitmap tracks the state of blocks in the segment, taking the place of the free list. The database uses the bitmap to find free blocks and then formats each block before filling it with data. ASSM spread out inserts among blocks to avoid concurrency issues.
Oracle 自动段空间管理(ASSM:auto segment space management)
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4958989.aspx
Every data block in an ASSM segment is in one of the following states:
(1)Above the HWM
These blocks are unformatted and have never been used.
(2)Below the HWM
These blocks are in one of the following states:
(1)Allocated, but currently unformatted and unused
(2)Formatted and contain data
(3)Formatted and empty because the data was deleted
Figure 12-23 depicts an ASSM segment as a horizontal series of blocks. At table creation, the HWM is at the beginning of the segment on the left. Because no data has been inserted yet, all blocks in the segment are unformatted and never used.
Figure 12-23 HWM at Table Creation

Suppose that a transaction inserts rows into the segment. The database must allocate a group of blocks to hold the rows. The allocated blocks fall below the HWM. The database formats a bitmap block in this group to hold the metadata, but does not preformat the remaining blocks in the group.
In Figure 12-24, the blocks below the HWM are allocated, whereas blocks above the HWM are neither allocated or formatted. As inserts occur, the database can write to any block with available space. The low high water mark (low HWM) marks the point below which all blocks are known to be formatted because they either contain data or formerly contained data.
Figure 12-24 HWM and Low HWM
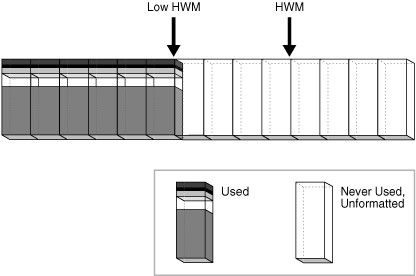
In Figure 12-25, the database chooses a block between the HWM and low HWM and writes to it. The database could have just as easily chosen any other block between the HWM and low HWM, or any block below the low HWM that had available space. In Figure 12-25, the blocks to either side of the newly filled block are unformatted.
Figure 12-25 HWM and Low HWM

The low HWM is important in a full table scan. Because blocks below the HWM are formatted only when used, some blocks could be unformatted, as in Figure 12-25. For this reason, the database reads the bitmap block to obtain the location of the low HWM. The database reads all blocks up to the low HWM because they are known to be formatted, and then carefully reads only the formatted blocks between the low HWM and the HWM.
Assume that a new transaction inserts rows into the table, but the bitmap indicates that insufficient free space exists under the HWM. In Figure 12-26, the database advances the HWM to the right, allocating a new group of unformatted blocks.
Figure 12-26 Advancing HWM and Low HWM
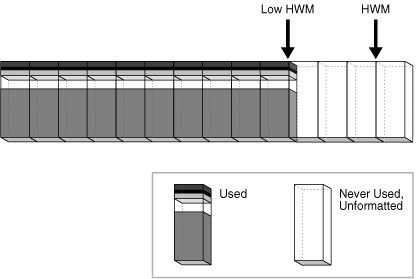
When the blocks between the HWM and low HWM are full, the HWM advances to the right and the low HWM advances to the location of the old HWM. As the database inserts data over time, the HWM continues to advance to the right, with the low HWM always trailing behind it. Unless you manually rebuild, truncate, or shrink the object, the HWM never retreats.
Oracle 数据块 Block 说明
http://blog.csdn.net/tianlesoftware/archive/2011/05/12/6414765.aspx
2. 2 Oracle表段中的高水位线HWM
在Oracle数据的存储中,可以把存储空间想象为一个水库,数据想象为水库中的水。水库中的水的位置有一条线叫做水位线,在Oracle中,这条线被称为高水位线(High-warter mark, HWM)。在数据库表刚建立的时候,由于没有任何数据,所以这个时候水位线是空的,也就是说HWM为最低值。当插入了数据以后,高水位线就会上涨,但是这里也有一个特性,就是如果你采用delete语句删除数据的话,数据虽然被删除了,但是高水位线却没有降低,还是你刚才删除数据以前那么高的水位。也就是说,这条高水位线在日常的增删操作中只会上涨,不会下跌。HWM通常增长的幅度为一次5个数据块.
Select语句会对表中的数据进行一次扫描,但是究竟扫描多少数据存储块呢,这个并不是说数据库中有多少数据,Oracle就扫描这么大的数据块,而是Oracle会扫描高水位线以下的数据块。现在来想象一下,如果刚才是一张刚刚建立的空表,你进行了一次Select操作,那么由于高水位线HWM在最低的0位置上,所以没有数据块需要被扫描,扫描时间会极短。而如果这个时候你首先插入了一千万条数据,然后再用delete语句删除这一千万条数据。由于插入了一千万条数据,所以这个时候的高水位线就在一千万条数据这里。后来删除这一千万条数据的时候,由于delete语句不影响高水位线,所以高水位线依然在一千万条数据这里。这个时候再一次用select语句进行扫描,虽然这个时候表中没有数据,但是由于扫描是按照高水位线来的,所以需要把一千万条数据的存储空间都要扫描一次,也就是说这次扫描所需要的时间和扫描一千万条数据所需要的时间是一样多的。所以有时候有人总是经常说,怎么我的表中没有几条数据,但是还是这么慢呢,这个时候其实奥秘就是这里的高水位线了。
那有没有办法让高水位线下降呢,其实有一种比较简单的方法,那就是采用TRUNCATE语句进行删除数据。采用TRUNCATE语句删除一个表的数据的时候,类似于重新建立了表,不仅把数据都删除了,还把HWM给清空恢复为0。所以如果需要把表清空,在有可能利用TRUNCATE语句来删除数据的时候就利用TRUNCATE语句来删除表,特别是那种数据量有可能很大的临时存储表。
在手动段空间管理(Manual Segment Space Management)中,段中只有一个HWM,但是在Oracle 9i Release1才添加的自动段空间管理(Automatic Segment Space Management)中,又有了一个低HWM的概念出来。为什么有了HWM还又有一个低HWM呢,这个是因为自动段空间管理的特性造成的。在手段段空间管理中,当数据插入以后,如果是插入到新的数据块中,数据块就会被自动格式化等待数据访问。而在自动段空间管理中,数据插入到新的数据块以后,数据块并没有被格式化,而是在第一次访问这个数据块的时候才格式化这个块。所以我们又需要一条水位线,用来标示已经被格式化的块。这条水位线就叫做低HWM。一般来说,低HWM肯定是低于等于HWM的。
2.3. 修正ORACLE表的高水位线
在ORACLE中,执行对表的删除操作不会降低该表的高水位线。而全表扫描将始终读取一个段(extent)中所有低于高水位线标记的块。如果在执行删除操作后不降低高水位线标记,则将导致查询语句的性能低下。rebuild, truncate, shrink,move 等操作会降低高水位。
2.3.1 执行表重建指令 alter table table_name move;
在线转移表空间ALTER TABLE ... MOVE TABLESPACE ..
当你创建了一个对象如表以后,不管你有没有插入数据,它都会占用一些块,ORACLE也会给它分配必要的空间.同样,用ALTER TABLE MOVE释放自由空间后,还是保留了一些空间给这个表.
ALTER TABLE ... MOVE 后面不跟参数也行,不跟参数表还是在原来的表空间,Move后记住重建索引. 如果以后还要继续向这个表增加数据,没有必要move, 只是释放出来的空间,只能这个表用,其他的表或者segment无法使用该空间。
2.3.2 执行alter table table_name shrink space;
此命令为Oracle 10g新增功能,再执行该指令之前必须允许行移动 alter table table_name enable row movement;
2.3.3 重建表
复制要保留的数据到临时表t,drop原表,然后rename临时表t为原表
2.3.4 用逻辑导入导出: Emp/Imp
2.3.5. Alter table table_name deallocate unused
DEALLOCATE UNUSED为释放HWM上面的未使用空间,但是并不会释放HWM下面的自由空间,也不会移动HWM的位置.
2.3.6 推荐使用truncate.
2.3.7 一些注意事项
Oracle 9i:
(1)如果是INEXTENT, 可以使alter table tablename deallocate unused将HWM以上所有没使用的空间释放
(2) 如果MINEXTENT >HWM 则释放MINEXTENTS 以上的空间。如果要释放HWM以上的空间则使用KEEP 0。
SQL>alter table tablesname deallocate unused keep 0;
(3)truncate table drop storage(缺省值)命令可以将MINEXTENT 之上的空间完全释放(交还给操作系统),并且重置HWM。
(4)如果仅是要移动HWM,而不想让表长时间锁住,可以用truncate table reuse storage,仅将HWM重置。
(5)ALTER TABLE MOVE会将HWM移动,但在MOVE时需要双倍的表空间,而且如果表上有索引的话,需要重构索引
(6)DELETE表不会重置HWM,也不会释放自由的空间(也就是说DELETE空出来的空间只能给对象本身将来的INSERT/UPDATE使用,不能给其它的对象使用)
Oracle 10g:
(1)可以使用alter table test_tab shrink space命令来联机移动hwm,
(2)如果要同时压缩表的索引,可以发布:alter table test_tab shrink space cascade
2.4 HWM 特点
2.4.1 ORACLE用HWM来界定一个段中使用的块和未使用的块.
举个例子来说,当我们创建一个表时,ORACLE就会为这个对象分配一个段.在这个段中,即使我们未插入任何记录,也至少有一个区被分配,第一个区的第一个块就称为段头(SEGMENT HEADE),段头中就储存了一些信息,基中HWM的信息就存储在此.
此时,因为第一个区的第一块用于存储段头的一些信息,虽然没有存储任何实际的记录,但也算是被使用,此时HWM是位于第2个块.当我们不断插入数据到表后,第1个块已经放不下后面新插入的数据,此时,ORACLE将高水位之上的块用于存储新增数据,同时,HWM本身也向上移.也就是说,当我们不断插入数据时,HWM会往不断上移,这样,在HWM之下的,就表示使用过的块,HWM之上的就表示已分配但从未使用过的块.
2.4.2. HWM在插入数据时,当现有空间不足而进行空间的扩展时会向上移,但删除数据时不会往下移.
ORACLE 不会释放空间以供其他对象使用,有一条简单的理由:由于空间是为新插入的行保留的,并且要适应现有行的增长。被占用的最高空间称为最高使用标记 (HWM),
2.4.3. HWM的信息存储在段头当中.
HWM本身的信息是储存在段头.在段空间是手工管理方式时,ORACLE是通过FREELIST(一个单向链表)来管理段内的空间分配.在段空间是自动管理方式时(ASSM),ORACLE是通过BITMAP来管理段内的空间分配.
2.4.4. ORACLE的全表扫描是读取高水位标记(HWM)以下的所有块.
所以问题就产生了.当用户发出一个全表扫描时,ORACLE 始终必须从段一直扫描到 HWM,即使它什么也没有发现。该任务延长了全表扫描的时间。
2.4.5. 当用直接路径插入行时,即使HWM以下有空闲的数据库块,键入在插入数据时使用了append关键字,则在插入时使用HWM以上的数据块,此时HWM会自动增大。
例如,通过直接加载插入(用 APPEND 提示插入)或通过 SQL*LOADER 直接路径 数据块直接置于 HWM 之上。它下面的空间就浪费掉了。
三. 相关测试
1)创建测试表
SQL> create table tt (id number);
Table created.
此时表没有分析,是原始的数据,即8个数据块。
SQL>SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 8
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT
2)向表中插入一些测试数据
SQL> declare
2 i number;
3 begin
4 for i in 1..10000 loop
5 insert into tt values(i);
6 end loop;
7 commit;
8 end;
9 /
PL/SQL procedure successfully completed.
3)在次查看表的信息
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 24
此时表TT 占用的数据库已经是24个了。 但是user_tables 显示的信息还是为空。 因为没有做统计分析。
4)收集统计信息
SQL> exec DBMS_STATS.GATHER_TABLE_STATS('SYS','TT');
PL/SQL procedure successfully completed.
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 24
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 10000 20 0
此时user_tables 已经有了数据,显示的使用了20个数据块。 但是empty_blocks 还是为空。 这里要注意的地方。 这个字段只有使用analyze 收集统计信息之后才会有数据。
5)使用analyze 收集统计信息
SQL> ANALYZE TABLE TT COMPUTE STATISTICS;
Table analyzed.
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 10000 20 3
-- 这里有显示空的数据库有3个。注意:20+3=23. 比占用的24个数据块少一个。因为有一个数据库块被保留用作segment header。
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 24
6) delete 数据,不会降低高水位
SQL> delete from tt;
10000 rows deleted.
SQL> commit;
Commit complete.
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 24
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 10000 20 3
SQL> analyze table tt compute statistics;
Table analyzed.
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 0 20 3
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 24
SQL>
7) truncate 表,可以降低高水位
SQL> truncate table tt;
Table truncated.
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 8
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 0 20 3
-- 段的信息没有改变,收集一下统计信息看看
SQL> exec dbms_stats.gather_table_stats('SYS','TT');
PL/SQL procedure successfully completed.
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 0 0 3
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 8
--段的信息已经改变,但是empty_blocks 段没有改变,该段只有使用analyze 才能改变。
SQL> analyze table tt compute statistics;
Table analyzed.
SQL> SELECT table_name,num_rows,blocks,empty_blocks FROM user_tables WHERE table_name='TT';
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS
--------------- ---------- ---------- ------------
TT 0 0 7
SQL> SELECT segment_name,segment_type,blocks FROM dba_segments WHERE segment_name='TT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS
--------------- --------------- ----------
TT TABLE 8
SQL>
-- 总共8个数据块,7个为空,还有一个是segment header。
四. Alter table move 和Shrink 区别
在下面2篇blog 有说明:
http://blog.csdn.net/robinson1988/archive/2010/09/07/5868742.aspx
alter table move跟shrink space的区别
http://blog.csdn.net/wyzxg/archive/2010/05/28/5631721.aspx
MOS 上的说明,ID:577375.1:
The shrink algorithm starts from the bottom of the segment and starts moving those rows to the beginning of the segment. Shrink is a combination of delete/insert pair for every row movement and this generates many UNDO and REDO blocks .
Move从segment的底部开始,move这些rows到segment的头部。Shrink则是delete/insert相结合,这样会产生非常多的UNDO和REDO。
4.1 Shrink
在10g之后,整理碎片消除行迁移的新增功能shrink space
SQL>alter table <table_name> shrink space [ <null> | compact | cascade ];
compact: 这个参数当系统的负载比较大时可以用,不降低HWM。如果系统负载较低时,直接用alter table table_name shrink space就一步到位了
cascade:这个参数是在shrink table的时候自动级联索引,相当于rebulid index。
以下SQL 基于普通表
shrink必须开启行迁移功能。
alter table table_name enable row movement ;
保持HWM,相当于把块中数据打结实了
alter table table_name shrink space compact;
回缩表与降低HWM
alter table table_name shrink space;
回缩表与相关索引,降低HWM
alter table table_name shrink space cascade;
回缩索引与降低HWM
alter index index_name shrink space
虽然在10g中可以用shrink ,但也有些限制:
1). 对cluster,cluster table,或具有Long,lob类型列的对象 不起作用。
2). 不支持具有function-based indexes 或 bitmap join indexes的表
3). 不支持mapping 表或index-organized表。
4). 不支持compressed 表
4.2 Move
通过desc table_name 来检查表中是否有LOB 字段, 如果表没有LOB字段, 直接 alter table move; 然后 rebuild index
如果表中包含了LOB字段,如用如下SQL:
SQL>alter table owner.table_name move tablespace tablespace_name lob (lob_column) store as lobsegment tablespace tablespace_name;
也可以单独move lob,但是表上的index 同样会失效. 所以在操作结束,需要对索引进行rebuild。
SQL>alter table owner.table_name move lob(lob_column) store as lobsegment tablespace tablespace_name ;
索引的rebuild:
首先用下面的SQL查看表上面有哪类索引:
SELECTa.owner,
a.index_name,
a.index_type,
a.partitioned,
a.status,
b.status p_status,
b.composite
FROMdba_indexes a
LEFTJOIN
dba_ind_partitions b
ONa.owner = b.index_owner ANDa.index_name = b.index_name
WHEREa.owner ='&owner'ANDa.table_name ='&table_name';
对于普通索引直接rebuild online nologging parallel,
对于分区索引,必须单独rebuild 每个分区,
对于组合分区索引,必须单独rebuild 每个子分区。
Move 通过移动数据来来降低HWM,因此需要更多的磁盘空间。 Shrink 通过delete 和 insert, 会产生较多的undo 和redo。
shrink space收缩到数据存储的最小值,alter table move(不带参数)收缩到initial指定值,也可以用alter table test move storage(initial 500k)指定收缩的大小,这样可以达到shrink space效果。
总之,使用Move 效率会高点,但是会导致索引失效。Shrink 会产生undo 和redo,速度相对也慢一点。