巧用变量减少查询
1:用变量排名
例: 以ecshop中的商品表为例,计算每个栏目下的商品数,并按商品数排名.
并按商品数计算这些栏目的名次
2:用变量计算真正影响的行数
当插入多条,当主键重复时,则自动更新,这种效果,可以用insert on duplication for update

例: 以ecshop中的商品表为例,计算每个栏目下的商品数,并按商品数排名.
<span style="font-size:18px;">select cat_id,count(*) as cnt from goods group by cat_id order by cnt desc;</span>
并按商品数计算这些栏目的名次
<span style="font-size:18px;">set @curr_cnt := 0,@prev_cnt := 0, @rank := 0; select cat_id, (@curr_cnt := cnt) as cnt, (@rank := if(@curr_cnt <> @prev_cnt,@rank+1,@rank)) as rank, @prev_cnt := @curr_cnt from ( select cat_id,count(*) as cnt from shop. goods group by shop. goods.cat_id order by cnt desc) as tmp;</span>
2:用变量计算真正影响的行数
当插入多条,当主键重复时,则自动更新,这种效果,可以用insert on duplication for update
要统计真正”新增”的条目, 如下图,我们想得到的值是”1”,即被更新的行数.
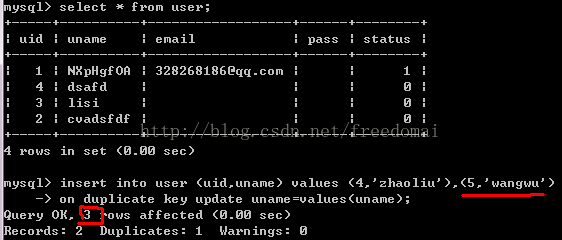
<span style="font-size:18px;"> insert into user (uid,uname) values (4,’ds’),(5,'wanu'),(6,’safdsaf’) on duplicate key update uid=values(uid)+(0*(@x:=@x+1)) , uname=values(uname);</span>
<span style="font-size:18px;">set @x:=0;</span>
总影响行数-2*实际update数, 即新增的行数.
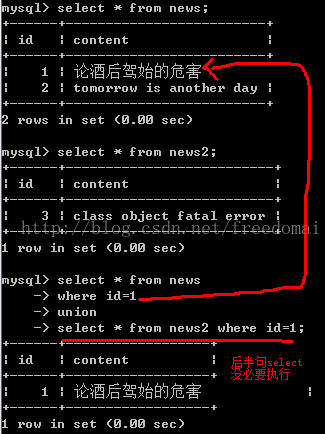
3: 简化union
比如有新闻表,news , news_hot,
new_hot是一张内存表,非常快,用来今天的热门新闻.
首页取新闻时,逻辑是这样的:
先取hot, 没有 再取news,为了省事,用一个union来完成.
<span style="font-size:18px;">select nid,title from news_hot where nid=xxx union select nid,title from news where nid=xxx;</span>
<span style="font-size:18px;">如何利用变量让后半句select不执行 , select id,content,(@find := 1) from news_hot where id=1 //第一个sql语句会先执行where后面的语句,如果在new_hot找到id=1的记录,就定义@find变量为1,那么</span>
<span style="font-size:18px;">//下面的union的子句where id=1 and (@find <= 0)不成立,就不会去查找news表的内容 union select id,content,(@find :=1) from news where id=1 and (@find <= 0) union 1,1,1 where (@find :=null) is not null;//这里是重新初始化@find变量</span>
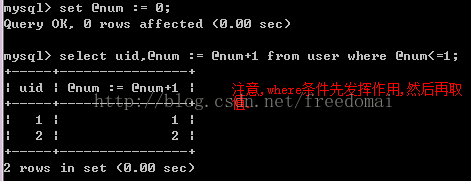
3:小心变量的顺序
如下图:变量先在where中发挥作用,然后再是select操作.
如果where不成立,select操作再不发生.
第2例:

在这个例子中, 1,2两行,先排好序, 在内存中,就是这样的顺序 [2] [1]
再逐行where条件判断,取值.


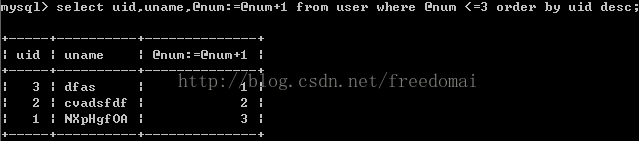
对比这2张图,分析:
1: where先发挥作用,把需要的行 都给找出
2: 然后再逐行 select
因此, 前者, 最终select时,select@num变量,都是一个值
后者,不断select,不断修改@num的值, 值不断变化.
同时: 使用变量,将会使sql语句的结果不缓存.