CEGUI文本渲染(二)
CEGUI中文显示
jiese1990
我的CEGUI是0.7.5支持中文显示,而且,很容易让其显示中文。只要两步就可以解决。
我们得有一个支持中文的字体
可以使用simhei.ttf字体,它支持中文,将该文件放到字体资源组的默认路径中,我的是D:\Projects\CEGUI\FirstCEGUI - 修改窗口皮肤\datafiles\fonts
1-1)加载字体有很多方法,可以通过.font脚本,也可以如下
加载字体CEGUI::Font &font = CEGUI::FontManager::getSingleton().createFreeTypeFont("DejaVuSans-10"/*字体名*/, 40/*字体大小*/, false, "simhei.ttf");
2) CEGUI采用的是UTF-8编码。要想显示中文,要先的文字所在的字符串里存储的字符码转换为UTF-8即可
//1)首先将GBK的数据转化为Unicode数据---
MultiByteToWideChar(CP_ACP, 0, text, -1, g_Unicode, 1024);
//2)然后将Unicode数据转化为utf8数据
WideCharToMultiByte(CP_UTF8, 0, g_Unicode, -1, (char*)g_buf, 1024, 0, 0);
一个GBK转UTF8的转换函数
可以参考下:
//将ANSI字符编码的字符 转换为 UTF8的字符串
/*返回值:
std::auto_ptr<char>,返回一个智能指针。该指针指向的数据块就是转换好的UTF8的数据。
可通过std::auto_ptr<char>.get()来获得指针。
*/
std::auto_ptr<char> AnsiToUTF8( const char* pMbcs )
{
int nSize = strlen(pMbcs); //要转的字符的长度
std::auto_ptr<char> strOfUTF8; //指向转好了的字符,的智能指针
int n = 0; //转换的字符数 或 字节数
WCHAR * pBuff; //存储Unicode的中转缓存
if (nSize > 0 )
{
//1-1)获得转换需要多少字符数来存储,即pBuff需要分配多少内存
n = MultiByteToWideChar(CP_ACP, 0, pMbcs, nSize+1, NULL, 0);
if (n>0)
{
pBuff = new WCHAR[n];
//1-2)首先将ANSI的数据转化为Unicode数据--
//--------这一步不能省,ANSI不能直接转UTF-8,ANSI编码跟Unicode是完全不同的字符编码; UTF-8属于Unicode编码的一种编码方式
n = MultiByteToWideChar(CP_ACP, 0, pMbcs, nSize+1, pBuff, n);
//2-1)获得转换需要多少字节数来存储,即strOfUTF8需要分配多少内存
n = WideCharToMultiByte(CP_UTF8, 0, (wchar_t *)pBuff, -1, NULL, 0, 0, 0);
strOfUTF8.reset(new char[n]);
//2-2)然后将Unicode数据转化为utf8数据
WideCharToMultiByte(CP_UTF8, 0, pBuff, -1, strOfUTF8.get(), n, 0, 0 );
delete[] pBuff;
}
}
//3)最后返回utf8数据的只能指针
return strOfUTF8;
}
然后将上篇“使用CEGUI::Font和GeometryBuffer渲染文本---不用控件”的第二步改为如下即可
//2)用CEGUI::Font来绘制文本
//通过ttf文件创建font
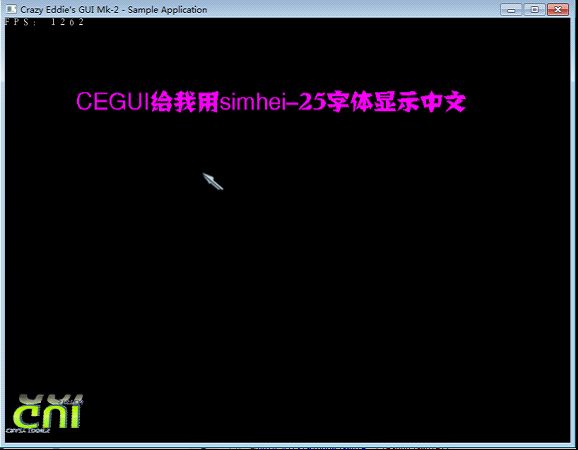
std::auto_ptr<char> ptr =AnsiToUTF8("CEGUI给我用simhei-25字体显示中文");
CEGUI::Font &font = CEGUI::FontManager::getSingleton().createFreeTypeFont("simhei-25", 25, false, "simhei.ttf");
font.drawText(*m_pTextGeometryBuffer, (CEGUI::utf8 *)ptr.get(), CEGUI::Vector2(100,100), &scrn, CEGUI::ColourRect(CEGUI::colour(1.0,0.0,1.0)) );
运行结果: