基于HBASE的并行计算架构之rowkey设计篇
海量数据都是事务数据,事务数据都是在时间的基础上产生的。数据的业务时间可能会顺序产生,也可能不会顺序产生,比如某些事务发生在早上
10
点,但是在下午
5
点才结束闭并生成出来,这样的数据就会造成存储加载时的时间连续性。另外海量数据的挖掘后产生的是统计数据,统计数据也有时间属性,统计数据如果进行保存必须保证在统计计算之后数据尽量不再变化,如果统计发生后又有新的事务数据产生,那么将重新触发统计计算然后重新保存覆盖原有已经存储的数据。其它数据则主要是以配置数据为主的通用数据。
根据以上分析按照数据的特性,我们可以将数据分为事务数据、统计数据与通用数据。
针对数据的查询根据数据的分类会有不同的用户操作场景。对于事务数据,用户的查询一定会给出时间范围(即使用户不给这个条件系统也会缺省设置),因为事务数据是海量的,如果要在指定时间范围根据不同的条件进行过滤、筛选、分组、聚合、多表关联等操作,数据在文件持久化的方式以及索引的架构将决定查询的效率,如何聪明的设计应对以上问题是高效应用
HBASE
的一个最大的课题。统计数据相对事务数据有一定收敛,但是同样要解决相同的查询问题。通用数据不会涉及复杂的查询需求,但是从产品的深度规划来说,要考虑与其它表关联的问题。
以上是我们对大数据应用出现的
3
种数据形态的应用场景做的一个简单介绍,下面我简单分析一下
HBASE
的架构与功能特性,从而推导出如何实现以上应用场景中的存储、计算与查询的需求。
2.标准HBASE功能特性分析
HBase
是一个分布式的、面向列的开源数据库,是
Apache
的
Hadoop
项目的子项目。
HBase
不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是
HBase
基于列的而不是基于行的模式。如下图所示,
HBASE
是介于
hadoop
的
HDFS
与
MapReduce
之间的一个系统,基础性的介绍我这里不做多的描述,相关资料很多可参考。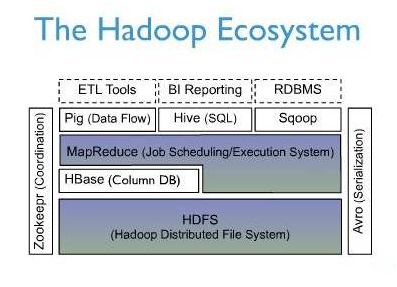
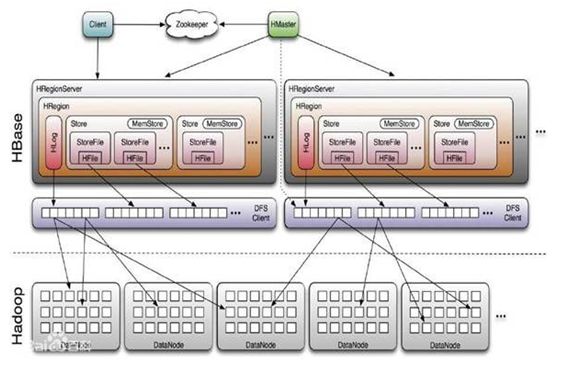
如下图所示,
HBASE
的层次结构是
RegionServer > Region > Store(MemStore) > StoreFile > HFile
。
HFile
是数据的持久化存储媒质,
MemStore
是数据的内存缓存。
HBASE
是采用
KeyValue
的列存储,
Rowkey
是
KeyValue
的
Key
,表示唯一一行。
Rowkey
是一段二进制码流,最大程度为
64KB
,内容用户自定义。数据的加载根据
Rowkey
的二进制序由小到大进行排序。
HBASE
根据数据的规模将数据自动分切到多个
Region
的多个
HFile
中。
HBASE
是根据
Rowkey
来进行检索的。支持
3
种方式。通过单个
Rowkey
访问,即按照某个
Rowkey
键值进行
get
操作;通过
Rowkey
的
range
进行
scan
,即通过设置
startRowKey
和
endRowKey
,在这个范围内进行扫描;全表扫描,即直接扫描整张表中所有行记录。
HBASE
按单个
Rowkey
检索的效率是很高的,耗时在
1
毫秒以下,每秒钟可获取
1000~2000
条记录。
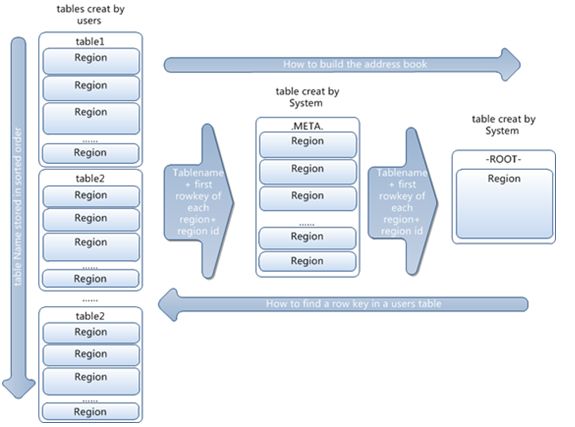
系统通过找到某个
Rowkey (
或者某个
Rowkey
范围
)
所在的
Region
,然后将查询数据的请求路由到该
Region
获取数据,如上图所示。因此数据的合理的分布是提高检索查询性能的设计方式。例如获取
100
万条记录,按每
Region
每秒
1000
条记录算,获取全部数据需要
1000
秒时间。如果数据均匀分布在集群每个
Region
上,那么在检索时就可以最大可能利用并行计算特性,让
Region
同时向客户端吐数据,如果数据均匀分布在
100
个
Region
上,那么只需要
10
秒就能将所有数据取下来。
HBASE
也支持预建
Region
,根据数据的特性让用户来控制数据分布。
因此对于
Rowkey
的设计将控制平台的并行计算效率。
3.根据HBASE功能特性设计rowkey实现并行计算
基于
HBASE
的特性,
Rowkey
的设计将决定并行计算架构。
3.1. 设计原则
首先是
Rowkey
长度原则,
Rowkey
是一个二进制码流,
Rowkey
的长度被很多开发者建议说设计在
10~100
个字节,我的建议是越短越好,不要超过
16
个字节。原因一数据的持久化文件
HFile
中是按照
KeyValue
存储的,如果
Rowkey
过长比如
100
个字节,
1000
万列数据光
Rowkey
就要占用
100*1000
万
=10
亿个字节,将近
1G
数据,这会极大影响
HFile
的存储效率;原因二
MemStore
将缓存部分数据到内存,如果
Rowkey
字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此
Rowkey
的字节长度越短越好。原因三目前操作系统是都是
64
位系统,内存
8
字节对齐。控制在
16
个字节,
8
字节的整数倍利用操作系统的最佳特性。
其次是
Rowkey
散列原则,如果
Rowkey
是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将
Rowkey
的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个
Regionserver
实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个
RegionServer
上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别
RegionServer
,降低查询效率。
最后是
Rowkey
唯一原则,必须在设计上保证其唯一性。
3.2. 架构模型
基于
Rowkey
的长度原则、散列原则以及唯一原则我将针对不同应用场景提出不同的
Rowkey
设计建议。
针对事务数据Rowkey设计:
事务数据是带时间属性的,我会将时间信息存入到
Rowkey
中,这有助于提示查询检索速度。对于事务数据我缺省就按天为数据建表,这样设计的好处是多方面的。按天分表后,我时间信息就可以去掉日期部分只保留小时分钟毫秒,这样
4
个字节即可搞定。加上散列字段
2
个字节一共
6
个字节即可组成唯一
Rowkey
。如下图所示:
|
事务数据Rowkey设计
|
||||||
|
第0字节
|
第1字节
|
第2字节
|
第3字节
|
第4字节
|
第5字节
|
…
|
|
散列字段
|
时间字段(毫秒)
|
扩展字段
|
||||
|
0~65535(0x0000~0xFFFF)
|
0~86399999(0x00000000~0x05265BFF)
|
|
||||
这样的设计从操作系统内存管理层面无法节省开销,因为
64
位操作系统是必须
8
字节对齐。但是对于持久化存储中
Rowkey
部分可以节省
25%
的开销。也许有人要问为什么不将时间字段以主机字节序保存,这样它也可以作为散列字段了。这是因为时间范围内的数据还是尽量保证连续,相同时间范围内的数据查找的概率很大,对查询检索有好的效果,因此使用独立的散列字段效果更好,对于某些应用,我们可以考虑利用散列字段全部或者部分来存储某些数据的字段信息,只要保证相同散列值在同一时间(毫秒)唯一。
针对统计数据的Rowkey设计:
统计数据也是带时间属性的,统计数据最小单位只会到分钟(到秒预统计就没意义了)。同时对于统计数据我们也缺省采用按天数据分表,这样设计的好处无需多说。按天分表后,时间信息只需要保留小时分钟,那么
0~1400
只需占用两个字节即可保存时间信息。由于统计数据某些维度数量非常庞大,因此需要
4
个字节作为序列字段,因此将散列字段同时作为序列字段使用也是
6
个字节组成唯一
Rowkey
。如下图所示:
|
统计数据Rowkey设计
|
||||||
|
第0字节
|
第1字节
|
第2字节
|
第3字节
|
第4字节
|
第5字节
|
…
|
|
散列字段(序列字段)
|
时间字段(分钟)
|
扩展字段
|
||||
|
0x00000000~0xFFFFFFFF)
|
0~1439(0x0000~0x059F)
|
|
||||
同样这样的设计从操作系统内存管理层面无法节省开销,因为
64
位操作系统是必须
8
字节对齐。但是对于持久化存储中
Rowkey
部分可以节省
25%
的开销。预统计数据可能涉及到多次反复的重计算要求,需确保作废的数据能有效删除,同时不能影响散列的均衡效果,因此要特殊处理。
针对通用数据的Rowkey设计:
通用数据采用自增序列作为唯一主键,用户可以选择按天建分表也可以选择单表模式。这种模式需要确保同时多个入库加载模块运行时散列字段(序列字段)的唯一性。可以考虑给不同的加载模块赋予唯一因子区别。设计结构如下图所示。
|
通用数据Rowkey设计
|
||||
|
第0字节
|
第1字节
|
第2字节
|
第3字节
|
…
|
|
散列字段(序列字段)
|
扩展字段(控制在12字节内)
|
|||
|
0x00000000~0xFFFFFFFF)
|
可由多个用户字段组成
|
|||
4.结论
以上总结了HBASE的并行计算架构中关于Rowkey设计的要点。并行计算除了Rowkey之外还有其它影响因素,将在其他篇章予以说明。
来源:http://xdataopen.blog.51cto.com/4219560/1117864/