找找3
- 图像处理基础部分
- 叙述GABOR滤波器原理
- Graph-cut的基本原理和应用
- 常用的分类器有哪些并简述其原理
- 简述SVMGMM SIFTSURF和LDAPCA的基本原理
- 简述监督学习和非监督学习的区别并举例说明
- 常用的颜色空间有哪些各有什么特征
- Random Forest的随机性表现在哪里
- 常用的图像分割算法有哪些各有什么优缺点
- 数学形态中有哪些常用的算法各算法的功能
- 常用纹理特征有哪些
- 常用聚类方法有哪些并简述其原理
- 小波分析中常用的小波有哪些经过一层小波分解后相关特性
- 椒盐噪声用什么滤波处理比较有效
- 图像的像素数与分辨率有什么区别
- 简述你熟悉的聚类算法并说明其优缺点
- 请说出使用过的分类器和实现原理
- CC部分
- Windows中的消息是什么意思简述一下windows中的消息机制
- Windows中的进程与线程理解它们之间有什么关系
- 64位与32位操作系统有什么区别
- C中的this理解
- C中虚函数有什么作用
- Static理解
- 求一个正整数N的开方要求不能用库函数sqrt结果的精度在0001
- 逻辑和概率部分
- a和b两个人每天都会在7点-8点之间到同一个车站乘坐公交车a坐101路公交车每5分钟一班700705b坐102路公交车每10分钟一班703713问a和b碰面的概率是多少
- 假设某日是否有雨只和前一日是否有雨相关今日有雨则明日有雨的概率是07今日无雨则明日有雨的概率是05如果周一有雨求周三也有雨的概率
- 有 A 和 B 两路公交车平均发车间隔分别为 5 分钟和 10 分钟某乘客在站点 S 可以 任意选择两者之一乘坐假定 A 和 B 到达 S 的时刻无法确定那么该乘客的平均等待时间约为多少
图像处理基础部分
1. 叙述GABOR滤波器原理?
2. Graph-cut的基本原理和应用?
3. 常用的分类器有哪些,并简述其原理?
4. 简述SVM,GMM, SIFT/SURF和LDA/PCA的基本原理?
5. 简述监督学习和非监督学习的区别并举例说明?
6. 常用的颜色空间有哪些?各有什么特征?
7. Random Forest的随机性表现在哪里?
8. 常用的图像分割算法有哪些,各有什么优缺点?
9. 数学形态中有哪些常用的算法,各算法的功能?
10. 常用纹理特征有哪些?
11. 常用聚类方法有哪些,并简述其原理?
12. 小波分析中常用的小波有哪些?经过一层小波分解后相关特性?
13. 椒盐噪声用什么滤波处理比较有效?
14. 图像的像素数与分辨率有什么区别?
15.简述你熟悉的聚类算法并说明其优缺点。
16. 请说出使用过的分类器和实现原理。
C/C++部分
1. Windows中的消息是什么意思?简述一下windows中的消息机制?
解:消息就是在事件驱动模式下,事件发布函数和具体功能执行函数(或者代码段)之间的调用协议,调用协议的执行表现为窗口事件发布函数跟具体功能执行函数(或者代码段)之间的选择关系。在Windows系统下(下面所述均为Windows系统),对计算机外设的操作,例如当用户敲击键盘键、点击鼠标、热插拔USB盘等,系统都认为外设发生了事件,于是系统调用专职函数就把这些事件进行收集,形成现场信息,赋值给一个叫做“消息结构体”的对象,那么这个被赋予特定意义的消息结构体对象就可以称之为“消息”;然后,专职函数再把这个“消息”投递到(Post)到系统中一个专职消息管理的机构中去,这个过程就完成了消息形成和投递。可以这样想象这个所谓的“消息管理机构”的主要运作:
- 系统每时每刻都有可能发生事件,所发事件都是针对某个或者某些具体应用程序的,所以计算机需要先对这些由事件形成的消息进行集中收集,并完成存操作(即消息投递),一般来说新来的消息都存放在靠后位置,也就是严格按照先来后到的时间顺序进行存操作的;
- 再由系统专职函数对这些消息进行读取,完成取操作。取操作跟存操作刚好相反,是从头开始的,就是先取存放时间最早的那个消息。然后,这些专职函数根据所取的消息的参数的含义,把所取的消息再投递到指定的应用程序的“消息管理机构”中去。
2.Windows中的进程与线程理解,它们之间有什么关系?
解:Windows中的进程简单地说就是一个内存中的可执行程序, 提供程序运行的各种资源. 进程拥有虚拟的地址空间, 可执行代码, 数据, 对象句柄集, 环境变量, 基础优先级, 以及最大最小工作集. Windows中的线程是系统处理机调度的基本单位. 线程可以执行进程中的任意代码, 包括正在被其他线程执行的代码. 进程中的所有线程共享进程的虚拟地址空间和系统资源. 每个线程拥有自己的例外处理过程, 一个调度优先级以及线程上下文数据结构. 线程上下文数据结构包含寄存器值, 核心堆栈, 用户堆栈和线程环境块.
进程的虚拟地址空间,首先可以把"虚拟"这个词拿掉, 对于简化进程模型有很大帮助(当对进程/线程和虚拟内存部分都充分理解后, 那时结合起来再考量会有更深程度的掌握). 地址空间就是系统给予进程的, 进程内任何可执行代码都可以感知的内存区域.(注意, 这里用了"感知"一词而不是访问, 其中的原因可以在后面讲解中找到) 问题: 地址空间有多大? 基地址和最大地址是什么?系统寻址能力决定了地址空间的大小. 主流的Windows系统是32位系统, 寻址能力是32位(形象的说就是指针是32位的), 所以地址空间的大小是4GB. 地址空间的基地址为0x00000000, 最大地址是0xFFFFFFFF. 4GB的地址空间被划分为2个大的内存区域, 用户区和系统区.
进程和线程的关系 -- 进程是容器:每个windows进程开始于它的被默认创建的第一个线程, 通常称其为主线程. 这种机制暗示了一个事实: 进程含有至少一个线程. 主线程和其它的线程没有任何区别, 每个线程都可以创建新的线程. 进程中所有线程都结束时进程会自动被结束, 而主动结束进程时, 如果还有线程没完成, 则系统自动结束这些线程.在windows中, 进程不再是处理机资源分配的最小单位, 那么它还是一个动态的实体吗? 是的, 从多进程并发的角度来看, 进程仍然是一个动态的实体, 但它的动态是它的线程的动态特征的抽象. 举个例子, 一个进程含有3个线程, 那么当3个线程都阻塞时, 进程表现为阻塞. 但只要有一个线程是就绪态, 哪怕其它2个线程是阻塞态, 进程仍然表现为就绪. 从线程的角度看, 进程表现的更像一个容器, 它代表线程接受分配到的资源(除处理机资源), 为线程提供主体(执行代码+数据), 自己却没有运行的概念. 此时, 进程是静态的实体.
3. 64位与32位操作系统有什么区别?
解:术语“32 位”和“64 位”是指计算机的处理器(也称为“CPU”)处理信息的方式。64 位版本的Windows 可处理大量的随机存取内存 (RAM),其效率远远高于 32 位的系统。64bit计算主要有两大优点:可以进行更大范围的整数运算;可以支持更大的内存。不能因为数字上的变化,而简单的认为64bit处理器的性能是 32bit处理器性能的两倍。实际上在32bit应用下,32bit处理器的性能甚至会更强,即使是64bit处理器,目前情况下也是在32bit应用下性能更强。所以要认清64bit处理器的优势,但不可迷信64bit。
内存这是64位系统最显著的优点,它可以使用超过4GB的内存 。大多数新的台式机和笔记本电脑至少拥有4GB的内存。问题是,像Vista和Win 7的32位版本只能够用大约3GB的内存 。相比之下,64位的Windows 不仅可以利用高达192GB的内存,还能够使用的内存映射取代BIOS的功能,从而使操作系统真正使用完整的4GB的。因此,如果您安装Win7 x64,对于有的4GB内存的机器你不会浪费1GB内存。
4. C++中的this理解?
解: 我们 要理解class的意思。class应该理解为一种类型,象int,char一样,是用户自定义的类型。(虽然比int char这样build-in类型复杂的多,但首先要理解它们一样是类型)。用这个类型可以来声明一个变量,比如int x, myclass my等等。这样就像变量x具有int类型一样,变量my具有myclass类型。理解了这个,就好解释this了,my里的this 就是指向my的指针。如果还有一个变量myclass mz,mz的this就是指向mz的指针。 这样就很容易理解this 的类型应该是myclass *,而对其的解引用*this就应该是一个myclass类型的变量。通常在class定义时要用到类型变量自身时,因为这时候还不知道变量名(为了通用也不可能固定实际的变量名),就用this这样的指针来使用变量自身。- this指针的用处:一个对象的this指针并不是对象本身的一部分,不会影响sizeof(对象)的结果。this作用域是在类内部,当在类的非静态成员函数中访问类的非静态成员的时候,编译器会自动将对象本身的地址作为一个隐含参数传递给函数。也就是说,即使你没有写上this指针,编译器在编译的时候也是加上this的,它作为非静态成员函数的隐含形参,对各成员的访问均通过this进行。例如,调用date.SetMonth(9) <===> SetMonth(&date, 9),this帮助完成了这一转换 .
- this指针的使用一种情况就是,在类的非静态成员函数中返回类对象本身的时候,直接使用 return *this;另外一种情况是当参数与成员变量名相同时,如this->n = n (不能写成n = n)。
5. C++中虚函数有什么作用?
解:我们都知道,c++为了与c语言能够兼容,c++做出了很大的牺牲,包括保留了struct关键字,还有编译期间添加了好多隐藏的代码。但是虚函数却不能与c语言实现兼容。而且有了虚函数,类的数据对象布局都发生了巨大的变化。这些暂时不说,还是回到上面的问题吧!我们都知道函数可以分为三种,一种是类的成员函数(member function),又可分为非静态成员函数(non-static member function),以及静态成员函数(static member function),而还有一种非类的成员函数(non-member function)。在类的非静态成员函数中又可以分为普通的函数以及虚函数。根据这种函数的分类,就知道了函数绝对是不能同时为虚函数以及静态成员函数的。对虚函数还可以继续细分,一是纯虚函数,一种就是普通的虚函数。纯虚函数必须在普通的虚函数基础上加上“=0”,同时普通的虚函数必须要有函数的实现。而纯虚函数默认情况是只有定义,而无需实现的,即只是定义一个接口(当然也可以实现,这时实现认为是默认的一种状态显示),同时包含了纯虚函数的类表明该类时一个抽象类,不能定义该类的对象,也就是说该类被定义成基类,是要被继承的,通过继承类来完成基类对象的生成。最后,强调一下,虚函数必须有一个关键字来修饰:virtual ,同时不能有static修饰。
虚函数的作用?我们知道面向对象语言的意义是让程序用一种符合人的思维来运行,而虚函数在c++面向对象语言的实现中起着举足轻重的作用。简而言之,虚函数的作用就是实现“动态联编”,也就是在程序的运行阶段动态地选择合适的成员函数。具体的实现方式是:在定义了虚函数后,可以在基类的派生类中对虚函数重新定义,在派生类中重新定义的函数应与虚函数具有相同的形参个数和形参类型。以实现统一的接口,不同定义过程。如果在派生类中没有对虚函数重新定义,则它继承其基类的虚函数。编译器在编译过程中发现类的函数名前的关键字virtual后,会自动将其作为动态联编处理,即在程序运行时动态地选择合适的成员函数,具体的实现机制下篇再讲。
这里提前说一下,类的静态成员函数与非类的成员函数对于类对象来说,访问函数的效率相当,都是在编译器确定,而虚函数需要在运行期确定,所以效率较低(符合上帝是公平的规律吧)。虚函数的使用?正确的使用虚函数是一个比较简单的问题。要实现动态联编,即只能用一个基类的指针或者引用来指向派生类对象,为什么必须要这样,见后面的虚函数实现机制。而把派生类对象赋值或者拷贝给基类的对象,只能实现派生类隐式转换成基类,即在编译器完成了派生类的截断,不能达到动态联编得作用。
6.Static理解?
解:static关键字是C, C++中都存在的关键字。static从字面理解,是“静态的“的 意思,与此相对应的,应该是“动态的“。static的作用主要有以下3个:
1、扩展生存期
这一点主要是针对普通局部变量和static局部变量来说的。声明为static的局部变量的生存期不再是当前作用域,而是整个程序的生存期。在程序中,常用内存类型主要有堆、栈和静态存储区。要理解static局部变量就必须首先理解这三种内存类型。在C/C++中, 局部变量按照存储形式可分为三种auto, static, register
- 局部变量的默认类型都是auto,从栈中分配内存。auto的含义是由程序自动控制变量的生存周期,通常指的就是变量在进入其作用域的时候被分配,离开其作用域的时候被释放。而static变量,不管是局部还是全局,都存放在静态存储区。表面意思就是不auto,变量在程序初始化时被分配,直到程序退出前才被释放;也就是static是按照程序的生命周期来分配释放变量的,而不是变量自己的生命周期. 如果在main前设置断点,然后查看static变量,已经被初始化,也就是说static在执行main函数前已经被初始化。也就是在程序初始化时被分配。
- 堆:由程序员自己分配释放(用malloc和free,或new和delete) ,如果我们不手动释放,那就要到程序结束才释放。如果对分配的空间在不用的时候不释放而一味的分配,那么可能会引起内存泄漏,其容量取决于虚拟内存,较大。栈:由编译器自动分配释放,其中存放在主调函数中被调函数的下一句代码、函数参数和局部变量,容量有限,较小。静态存储区:由在编译时由编译器分配,由系统释放,其中存放的是全局变量、static变量和常量.区别:1) 堆是由低地址向高地址扩展,栈是由高地址向低地址扩展。2) 堆是不连续的空间,栈是连续的空间。3) 在申请空间后,栈的分配要比堆的快。对于堆,先遍历存放空闲存储地址的链表、修改链表、再进行分配;对于栈,只要剩下的可用空间足够,就可分配到,如果不够,那么就会报告栈溢出。4) 栈的生命期最短,到函数调用结束时;静态存储区的生命期最长,到程序结束时;堆中的生命期是到被我们手动释放时(如果整个过程中都不手动释放,那就到程序结束时)。
2、限制作用域
这一点相对于普通全局变量和static全局变量来说的。对于全局变量而言,不论是普通全局 变量还是static全局变量,其存储区都是静态存储区,因此在内存分配上没有什么区别。区别在于:
- 普通的全局变量和函数,其作用域为整个程序或项目,外部文件(其它cpp文件)可以通过extern关键字访问该变量和函数。一般不提倡这种用法,如果要在多个cpp文件间共享数据,应该将数据声明为extern类型。在头文件里声明为extern: extern int g_value; // 注意,不要初始化值!然后在其中任何一个包含该头文件的cpp中初始化(一次)就好:int g_value = 0; // 初始化一样不要extern修饰,因为extern也是声明性关键字;然后所有包含该头文件的cpp文件都可以用g_value这个名字访问相同的一个变量;
- static全局变量和函数,其作用域为当前cpp文件,其它的cpp文件不能访问该变量和函数。如果有两个cpp文件声明了同名的全局静态变量,那么他们实际上是独立的两个变量。static函数的好处是不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
- 头文件中的static变量如果在一个头文件中声明:static int g_vaule = 0; 那么会为每个包含该头文件的cpp都创建一个全局变量,但他们都是独立的;所以也不建议这样的写法,一样不明确需要怎样使用这个变量,因为只是创建了一组同名而不同作用域的变量。
3、数据唯一性
这是C++对static关键字的重用。主要指静态数据成员/成员函数。表示属于一个类而不是属于此类的任何特定对象的变量和函数. 这是与普通成员函数的最大区别, 也是其应用所在, 比如在对某一个类的对象进行计数时, 计数生成多少个类的实例, 就可以用到静态数据成员.在这里面, static既不是限定作用域的, 也不是扩展生存期的作用, 而是指示变量/函数在此类中的唯一性.这也是”属于一个类而不是属于此类的任何特定对象的变量和函数”的含义. 因为它是对整个类来说是唯一的, 因此不可能属于某一个实例对象的. (针对静态数据成员而言, 成员函数不管是否是static, 在内存中只有一个副本, 普通成员函数调用时, 需要传入this指针, static成员函数调用时, 没有this指针. )
static数据成员的初始化:1) 初始化在类体外进行,而前面不加static,以免与一般静态变量或对象相混淆。2) 初始化时不加该成员的访问权限控制符private,public等。3) 初始化时使用作用域运算符来标明它所属类,因此,静态数据成员是类的成员,而不是对象的成员。4) 静态数据成员是静态存储的,它是静态生存期,必须对它进行初始化。
Static成员函数:静态成员函数和静态数据成员一样,它们都属于类的静态成员,它们都不是对象成员。因此,对静态成员的引用不需要用对象名。静态成员函数仅能访问静态的数据成员,不能访问非静态的数据成员,也不能访问非静态的成员函数,这是由于静态的成员函数没有this指针。
7. 求一个正整数N的开方,要求不能用库函数sqrt(),结果的精度在0.001.
解:牛顿迭代
逻辑和概率部分
1. a和b两个人每天都会在7点-8点之间到同一个车站乘坐公交车,a坐101路公交车,每5分钟一班【7:00,7:05....】,b坐102路公交车,每10分钟一班【7:03,7:13...】,问a和b碰面的概率是多少?
解:
ab┗━━━━┳━━┻━━━━━━━┻━━━━┳━━┻━━━━━━━┻ ┅ ┅ ┅ ┻━━━━┳━━┻━━━━━━━┻━━━━┳━━┻━━━━━━━┛
上图表示7点-8点之间的60分钟区间内, a、b两人可用的乘车时间点(a上b下)
可以看出每10分钟有一个最小循环, 那么可以先就前10分钟的区间进行分析.
以b为主体, b的时间可以被各时间点切成三份 (30−3,23−5,55−10) , 那么在这个区间里, 两人相遇的概率是
360×30−360+260×130−1360+560×85−1360=753600
需要注意的是后两项"使用了"下一个循环区间的时间, 因此需要单独考虑最后10分钟的相遇概率
360×350−5360+260×1050−6060+560×555−6060=543600
汇总的相遇概率为
753600×5+543600=1431200
2.假设某日是否有雨只和前一日是否有雨相关:今日有雨,则明日有雨的概率是0.7;今日无雨,则明日有雨的概率是0.5。如果周一有雨,求周三也有雨的概率?
解:
转移矩阵为
A=(0.70.50.30.5)
P(周三有雨|周一有雨)=[(1 0)A2]1,1=[(0.7 0.3)(0.70.50.30.5)]1,1=0.643. 有 A 和 B 两路公交车,平均发车间隔分别为 5 分钟和 10 分钟。某乘客在站点 S 可以 任意选择两者之一乘坐,假定 A 和 B 到达 S 的时刻无法确定,那么该乘客的平均等待时间约为多少?
解:首先,平均等待时间即为等待时间的期望,倘若依照题意,发车间隔并不固定又如何呢?
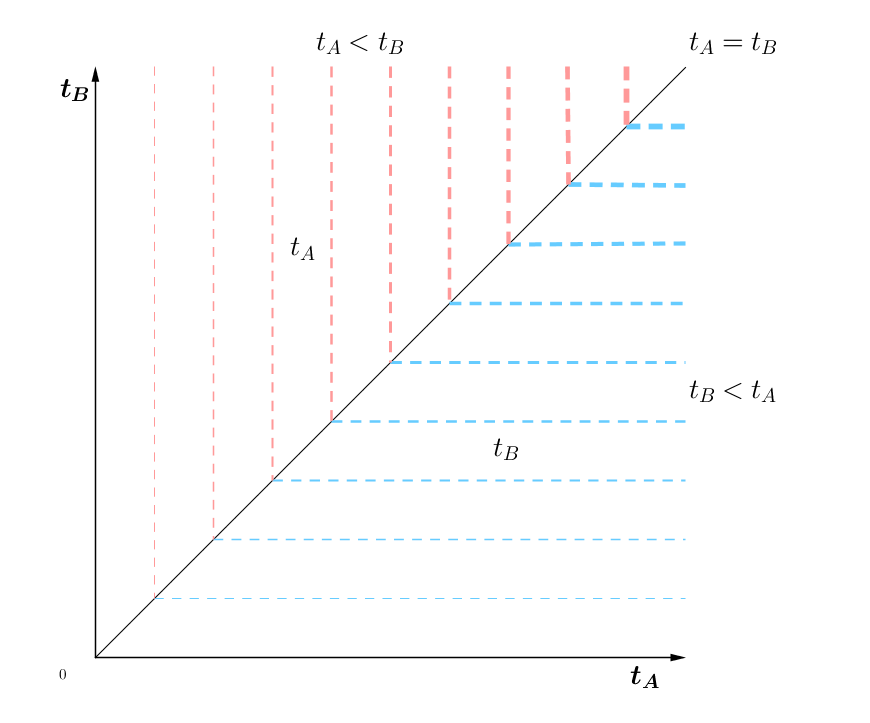
发车间隔不固定,那么 tA,tB 的值域变为 [0,+∞) ,随之而来的是另一个问题,概率密度分布是什么样的?此时值域不再有限,无法使用均等分布。注意这里问题的关键字是等待,说起等待,首先就应该想到泊松分布(Poisson Distribution)和泊松过程(Poisson process)。这里,等车的过程就可以看作两个相互独立的泊松过程。泊松过程的平稳独立增量假设十分重要,这意味着从任意时刻开始分布都是一样的,也就是说并不存在等待越久公车更可能即将到来这件事情。由此,泊松过程中,两次事件中的间隔时间服从指数分布,即
平均间隔时间即期望间隔时间 E[t]=∫+∞0tλe−λt dt=1λ (1)
由这个结论加上已知可得 tA∼15 e−15tA,tA⩾0; tB∼110 e−110tB,tB⩾0
那么仍然根据独立假设,可得 p(tA,tB)=15e−15tA110e−110tB, tA⩾0, tB⩾0
此时积分有
E[t]=∫+∞0∫+∞tBtB15e−15tA110e−110tB dtA dtB+∫+∞0
=∫+∞0tB110e−110tBe−15tB dtB+∫+∞0tA15e−15tAe−110tA dtA
=∫+∞0x(15+110) e−(15+110)x dx
=115+110
=313