Tika常见格式文件抽取内容并做预处理
摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理。首先我们要意识到预处理的重要性。在大数据的背景下,越来越多的非结构化半结构化文本。如何从海量文本中抽取我们需要的有价值的知识显得尤为重要。另外文本格式常常不一,诸如:pdf,word,excl,xml,ppt,txt等常见文件类型你或许经过一番周折还是有办法处理的。倘若遇到database,html,邮件,RTF,图像,语音等文件,你是否素手无策了。基于此本文总结Apache Tika内容抽取工具,其强大之处在于可以处理各种文件,另外节约您更多的时间用来做重要的事情。本文第一节采用核心概念讲解第二节知识扩展补充。第三节典型DOME配有源代码第四节参考核心文件和Tika工具的JAR包共享。(本文作者原创,汇编整理所得,转载请注明:Tika常见格式文件抽取内容并做预处理)
1 Tika介绍
Tika概念
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件,得到文件的metadata,content等内容,返回格式化信息。总的来说可以作为一个通用的解析工具。特别对于搜索引擎的数据抓去和处理步骤有重要意义。Tika是Apache的Lucene项目下面的子项目,在lucene的应用中可以使用tika获取大批量文档中的内容来建立索引,非常方便,也很容易使用。Apache Tika toolkit可以自动检测各种文档(如word,ppt,xml,csv,ppt等)的类型并抽取文档的元数据和文本内容。Tika集成了现有的文档解析库,并提供统一的接口,使针对不同类型的文档进行解析变得更简单。Tika针对搜索引擎索引、内容分析、转化等非常有用。
Tika架构
应用程序员可以很容易地在他们的应用程序集成Tika。Tika提供了一个命令行界面和图形用户界面,使它比较人性化。在本章中,我们将讨论构成Tika架构的四个重要模块。下图显示了Tika的四个模块的体系结构:
- 语言检测机制。
- MIME检测机制。
- Parser接口。
- Tika Facade 类.
语言检测机制
每当一个文本文件被传递到Tika,它将检测在其中的语言。它接受没有语言的注释文件和通过检测该语言添加在该文件的元数据信息。支持语言识别,Tika 有一类叫做语言标识符在包org.apache.tika.language及语言识别资料库里面包含了语言检测从给定文本的算法。Tika 内部使用N-gram算法语言检测。
MIME检测机制
Tika可以根据MIME标准检测文档类型。Tika默认MIME类型检测是使用org.apache.tika.mime.mimeTypes。它使用org.apache.tika.detect.Detector 接口大部分内容类型检测。内部Tika使用多种技术,如文件匹配替换,内容类型提示,魔术字节,字符编码,以及其他一些技术。
解析器接口
org.apache.tika.parser 解析器接口是Tika解析文档的主要接口。该接口从提取文档中的文本和元数据,并总结了其对外部用户愿意写解析器插件。采用不同的具体解析器类,具体为各个文档类型,Tika 支持大量的文件格式。这些格式的具体类不同的文件格式提供支持,无论是通过直接实现逻辑分析器或使用外部解析器库。
Tika Facade 类
使用的Tika facade类是从Java调用Tika的最简单和直接的方式,而且也沿用了外观的设计模式。可以在 Tika API的org.apache.tika包Tika 找到外观facade类。通过实现基本用例,Tika作为facade的代理。它抽象了的Tika库的底层复杂性,例如MIME检测机制,解析器接口和语言检测机制,并提供给用户一个简单的接口来使用。
Tika的特点
-
统一解析器接口:Tika封装在一个单一的解析器接口的第三方解析器库。由于这个特征,用户逸出从选择合适的解析器库的负担,并使用它,根据所遇到的文件类型。
-
低内存占用:Tika因此消耗更少的内存资源也很容易嵌入Java应用程序。也可以用Tika平台像移动那样PDA资源少,运行该应用程序。
-
快速处理:从应用连结内容检测和提取可以预期的。
-
灵活元数据:Tika理解所有这些都用来描述文件的元数据模型。
-
解析器集成:Tika可以使用可在单一应用程序中每个文件类型的各种解析器库。
-
MIME类型检测: Tika可以检测并从所有包括在MIME标准的媒体类型中提取内容。
-
语言检测: Tika包括语言识别功能,因此可以在一个多语种网站基于语言类型的文档中使用。
Tika的功能
Tika支持多种功能:
- 文档类型检测
- 内容提取
- 元数据提取
- 语言检测
文件类型检测
Tika使用不同的检测技术,检测给它的文件的类型。

内容提取
Tika有一个解析器库,可以分析各种文档格式的内容,并提取它们。然后检测所述文档的类型,它从解析器库选择的适当的分析器,并传递该文档。不同类别的Tika方法来解析不同的文件格式。
元数据提取
随着内容,Tika提取具有相同的程序的文件的元数据中的内容的提取。对于某些文件类型,Tika有接口类提取元数据。
语言检测
在内部,Tika如下像一个n-gram算法来检测所述内容的语言的给定文档中。Tika取决于类,如语言识别和Profiler的语言识别。

2 核心知识扩展
解析器接口
org.apache.tika.parser.Parser 接口是 Apache Tika 的关键组件。它隐藏了不同文件格式和解析库的复杂性,而同时又为客户应用程序从各种不同的文档提取结构化的文本内容以及元数据提供了一个简单且功能强大的机制。所有这些都是通过一个简单的方法实现的:
void parse(InputStream stream, ContentHandler handler, Metadata metadata) throws IOException, SAXException, TikaException;
parse 方法接受要被解析的文档以及相关的元数据作为输入,并输出 XHTML SAX 事件以及额外的元数据作为结果。导致这一设计的主要条件如表 1 所示。
表 1. Tika 解析设计的条件
| 条件 | 解释 |
|---|---|
流线化的解析 |
此接口不应要求客户应用程序或解析器实现将完整的文档内容保存在内存内或存放到磁盘。这就让即便很大的文档在没有过多的资源要求的情况下也可被解析。 |
结构化的内容 |
一个解析器实现应该能够包括所提取内容内的结构信息(标题、链接等)。客户应用程序可以使用这个信息,比如,来更好地判断这个被解析文档不同部分的相关性。 |
输入元数据 |
一个客户应用程序应该能够包括像要被解析的文档的文件名或被声明的内容类型这类元数据。这个解析器实现可使用这一信息来更好地指导这个解析过程。 |
输出元数据 |
一个解析器实现应能够返回除文档内容外的文档元数据。很多文档格式都包含对客户应用程序非常有用的元数据,比如作者名字。 |
这些条件在 parse 方法的参数内有所体现。
Document InputStream
第一个参数是 InputStream,用来读取要被解析的文档。
如果此文档流不能被读取,解析就会停止并且抛出的 IOException 就会被传递给客户应用程序。如果这个流可被读取但不能被解析(比如文档被破坏了),解析器就会抛出一个 TikaException。此解析器实现将会使用这个流,但不会关闭它。关闭流是由最初打开它的这个客户应用程序负责的。清单 1 显示了用 parse 方法使用流的建议模式。
清单 1. 用 parse 方法使用流的建议模式
InputStream stream = ...; // open the stream
try {
parser.parse(stream, ...); // parse the stream
} finally {
stream.close(); // close the stream
}
XHTML SAX 事件
此文档流的被解析内容被作为 XHTML SAX 事件的一个序列返回给客户应用程序。XHTML 用来表达此文档的结构化内容,SAX 事件用来启用流线化的处理。请注意这里使用了 XHTML 格式,仅仅是为了表达结构化信息,不是为了呈现文档以供浏览。由此解析器实现生成的这些 XHTML SAX 事件被发送至给到 parse 方法的一个 ContentHandler 实例。如果此内容处理程序处理一个事件失败,解析就会停止并且所抛出的 SAXException 会被发送给客户应用程序。清单 2 显示了所生成的这个事件流的整体结构(并且为了清晰,还添加了缩进)。
清单 2. 所生成的这个事件流的整体结构
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>...</title>
</head>
<body>
...
</body>
</html>
解析器实现通常会使用 XHTMLContentHandler 实用工具类来生成 XHTML 输出。处理这些原始的 SAX 事件可能会非常复杂,所以 Apache Tika(自 V0.2 开始)携带了几个实用工具类,用来处理事件流并将事件流转换为其他的表示。
比如,BodyContentHandler 类可用来只提取 XHTML 输出的主体部分并将其作为 SAX 事件提供给另一个内容处理程序或作为符号提供给一个输出流、一个编写器或 一个字符串。如下的代码片段解析了来自标准输入流的文档并将所提取的文档内容输出到标准输出:
ContentHandler handler = new BodyContentHandler(System.out); parser.parse(System.in, handler, ...);
另一个有用的类是 ParsingReader,它使用了一个后台线程来解析此文档并作为一个字符流返回所提取的文本内容。
清单 3. ParsingReader 的例子
InputStream stream = ...; // the document to be parsed
Reader reader = new ParsingReader(parser, stream, ...);
try {
...; // read the document text using the reader
} finally {
reader.close(); // the document stream is closed automatically
}
文档元数据
parse 方法的最后一个参数用来将文档元数据传递进/出此解析器。文档元数据被表述为一个元数据对象。表 2 列出了更有趣的一些元数据属性。
表 2. 元数据属性
| 属性 | 描述 |
|---|---|
Metadata.RESOURCE_NAME_KEY |
包含了此文档的文件或资源名 — 一个客户应用程序可设置此属性来让解析器通过文件名推断此文档的格式。如果文件格式包含了规范的文件名(比如,GZIP 格式有一个针对文件名的槽),那么文件解析器实现可设置此属性。 |
Metadata.CONTENT_TYPE |
此文档的声明内容类型 — 一个客户机应用程序可基于,比如 HTTP Content-Type 头,设置此属性。所声明的内容类型可帮助解析器正确地解析文档。解析器实现根据被解析的是哪个文档来将此属性设置为相应的内容类型。 |
Metadata.TITLE |
文档的标题 — 如果文档格式包含了一个显式的标题字段,那么此属性将由解析器实现设置。 |
Metadata.AUTHOR |
文档的作者名 — 如果文档格式包含了一个显式的作者字段,那么此属性将由解析器实现设置。 |
注意到,元数据处理还在 Apache Tika 开发团队的讨论之中,所以在 Tika V1.0 之前的版本,在元数据处理方面有可能会有一些(后向不兼容的)差异。
解析器实现
Apache Tika 自带一些解析器类来解析各种文档格式,如表 3 所示。
表 3. Tika 解析器类
| 格式 | 描述 |
|---|---|
| Microsoft® Excel® (application/vnd.ms-excel) | 在所有的 Tika 版本中都有对 Excel 电子数据表的支持,基于的是 POI 的 HSSF 库。 |
| Microsoft Word®(application/msword) | 在所有的 Tika 版本中都有对 Word 文档的支持,基于的是 POI 的 HWPF 库。 |
| Microsoft PowerPoint® (application/vnd.ms-powerpoint) | 在所有的 Tika 版本中都有对 PowerPoint 演示的支持,基于的是 POI 的 HSLF 库。 |
| Microsoft Visio® (application/vnd.visio) | 在 Tika V0.2 中加入了对 Visio 图表的支持,基于的是 POI 的 HDGF 库。 |
| Microsoft Outlook® (application/vnd.ms-outlook) | 在 Tika V0.2 中加入了对 Outlook 消息的支持,基于的是 POI 的 HSMF 库。 |
| GZIP 压缩 (application/x-gzip) | 在 Tika V0.2 中加入了对 GZIP 的支持,基于的是 Java 5 类库中的 GZIPInputStream 类。 |
| bzip2 压缩 (application/x-bzip) | 在 Tika V0.2 中加入了对 bzip2 的支持,基于的是 Apache Ant 的 bzip2 解析代码,而它最初基于的是 Aftex Software 的 Keiron Liddle 的工作成果。 |
| MP3 音频(audio/mpeg) | 在 Tika V0.2 中加入了对 MP3 文件的 ID3v1 标记的解析。如果找到,如下的元数据将被提取并设置:
|
| MIDI 音频 (audio/midi) | Tika 使用 javax.audio.midi 内的 MIDI 支持来解析 MIDI 序列文件。很多卡拉 OK 文件格式都基于的是 MIDI 并包含嵌入文本歌曲形式的歌词,并且 Tika 知道该如何提取。 |
| Wave 音频 (audio/basic) | Tika 通过 javax.audio.sampled 包支持取样的 wave 音频(.wav 文件等)。只有取样元数据才被提取。 |
| Extensible Markup Language (XML) (application/xml) | Tika 使用 javax.xml 类解析 XML 文件。 |
| HyperText Markup Language (HTML) (text/html) | Tika 使用 CyberNeko 库解析 HTML 文件。 |
| 图像 (image/*) | Tika 使用 javax.imageio 类从图像文件中提取元数据。 |
| Java 类文件 | Java 类文件的解析基于的是 ASM 库以及 JCR-1522 的 Dave Brosius 的工作成果。 |
| Java Archive Files | JAR 文件的解析是综合使用 ZIP 和 Java 这两种类文件解析器完成的。 |
| OpenDocument (application/vnd.oasis.opendocument.*) | Tika 使用 Java 语言中的内置 ZIP 和 XML 特性来解析多为 OpenOffice V2.0 或更高版本所用的 OpenDocument 文档类型。较早的 OpenOffice V1.0 格式也受支持,但它们目前不能像较新的格式那样被自动检测。 |
| 纯文本 (text/plain) | Tika 使用 International Components for Unicode Java 库(ICU4J)来解析纯文本。 |
| Portable Document Format (PDF) (application/pdf) | Tika 使用 PDFBox 库来解析 PDF 文档。 |
| Rich Text Format (RTF) (application/rtf) | Tika 使用 Java 的内置 Swing 库来解析 RTF 文档。 |
| TAR (application/x-tar) | Tika 使用来自 Apache Ant 的 TAR 解析代码的调整版本来解析 TAR 文件。而此 TAR 代码基于的是 Timothy Gerard Endres 的工作成果。 |
| ZIP (application/zip) | Tika 使用 Java 的内置 ZIP 类来解析 ZIP 文件。 |
您可以使用您自己的解析器来扩展 Apache Tika,您对 Tika 所做的任何贡献都是受欢迎的。Tika 的目标是尽可能地重用现有的解析器库(比如 Apache PDFBox 或 Apache POI),因此 Tika 内的大多数解析器类都是适应于这些外部库。Apache Tika 还包含一些不针对任何特定文档格式的通用解析器实现。其中最值得一提的是 AutoDetectParser 类,它将所有的 Tika 功能包装进一个能处理任何文档类型的解析器。这个解析器可自动决定入向文档的类型,然后会相应解析此文档。现在,我们可以进行一些实际操作了。如下的这些类是我们在整个教程中要开发的:
BudgetScramble— 显示了如何使用 Apache Tika 元数据来决定哪个文档最近被更改以及在何时更改。TikaMetadata— 显示了如何获得某个文档的所有 Apache Tika 元数据,即便没有数据(只显示所有的元数据类型)。TikaMimeType— 显示了如何使用 Apache Tika 的 mimetypes 来检测某个特定文档的 mimetype。TikaExtractText— 显示了 Apache Tika 的文件提取功能并将所提取的文本保存为合适的文件。LanguageDetector —介绍了 Nutch 语言的识别功能来识别特定内容的语言。Summary —总结了 Tika 特性,比如MimeType、内容 charset 检测和元数据。此外,它还引入了 cpdetector 功能来决定一个文件的 charset 编码。最后,它显示了 Nutch 语言识别的实际使用。
3 Tika文本抽取实例分析
Tika主要通过5个部分完成常规数据抽取:
1 InputStream input=new FileInputStream(new File("./myfile/Active Learning.pdf")); //构建InputStream来读取数据,可以写文件路径,pdf,word,html等
2 BodyContentHandler textHandler=new BodyContentHandler(); //获取内容
3 Metadata matadata=new Metadata();//Metadata对象保存了作者,标题等元数据
4 PDFParser ParseContext context=new ParseContext(); //这里Parser解析器根据不同文件采用不同解析器
5 Parser parser=new AutoDetectParser();//当调用parser,AutoDetectParser会自动估计文档MIME类型,此处输入pdf文件,因此可以使用
6 parser.parse(input, textHandler, matadata, context);//执行解析过程
源码:
/**
* Tika AutoDetectParser类来识别和抽取内容
* @throws TikaException
* @throws SAXException
* @throws IOException
*/
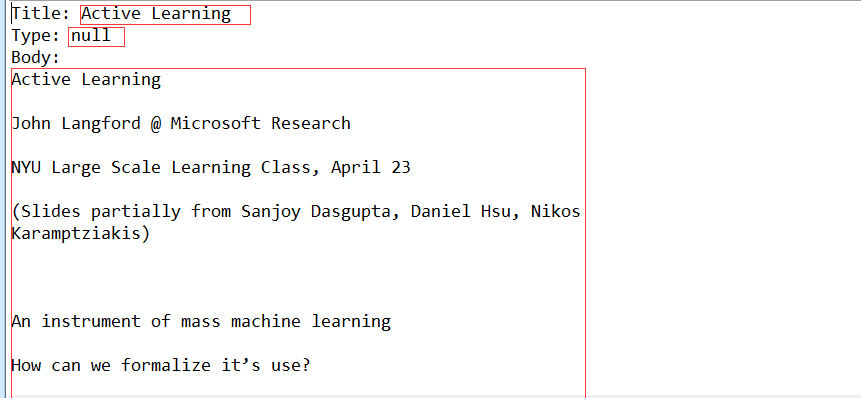
public static void getTextFronPDF() throws IOException, SAXException, TikaException{
//构建InputStream来读取数据
InputStream input=new FileInputStream(new File("./myfile/Active Learning.pdf"));//可以写文件路径,pdf,word,html等
BodyContentHandler textHandler=new BodyContentHandler();
Metadata matadata=new Metadata();//Metadata对象保存了作者,标题等元数据
Parser parser=new AutoDetectParser();//当调用parser,AutoDetectParser会自动估计文档MIME类型,此处输入pdf文件,因此可以使用PDFParser
ParseContext context=new ParseContext();
parser.parse(input, textHandler, matadata, context);//执行解析过程
input.close();
System.out.println("Title: "+matadata.get(Metadata.TITLE));
System.out.println("Type: "+matadata.get(Metadata.TYPE));
System.out.println("Body: "+textHandler.toString());//从textHandler打印正文
}
运行结果:
4 参考文献和JAR包共享
1 用 Apache Tika 理解信息内容
2 Tika教程
3 Apache Tika:通用的内容分析工具
4 Download Apache Tika
5 server-1.12.jar包 访问密码 32cd
【NLP】Tika 文本预处理:抽取各种格式文件内容
标签:des 算法 Lucene class style log com http si
原文:http://www.cnblogs.com/baiboy/p/tika.html