Android中PDF目录,搜索(包含中文),文字选择,高亮等实现
最近折腾了一个Android平台上PDF解析的一个项目,涉及到PDF中一些常见的问题,例如PDF的目录,搜索(包含中文),文字选择,高亮等实现,先借此地分享一下自己的一些成果。代码后期会开源出来,供大家分析,有好的建议也欢迎提出。。
参考文档
Adobe的官方文档
百度上的一篇PDF结构的分析
参考项目
Mupdf http://www.mupdf.com/
APV http://code.google.com/p/apv/
APV是基于Mupdf做了一个英文搜索以及显示方面的优化。
本文也主要基于Mupdf对各种模块进行相关的分析。
PDF的GUI分析工具
Voyeur https://github.com/below/PDF-Voyeur 它能帮你从繁杂的pdf spec中解脱出来,比较直观地了解PDF的内部结构,貌似只有Mac版的。。
Mupdf中的一些基础类
fz_obj 使用一个内联结构体代表了PDF中的基本数据类型
PDF支持8种基本对象类型为:布尔值,整型和浮点数(real numbers),字符串,名字,数组,词典,流,空对象
PDF目录
mupdf.h中目录的定义
- struct pdf_outline_s
- {
- char *title;
- pdf_link *link;
- int count;
- pdf_outline *child;
- pdf_outline *next;
- };
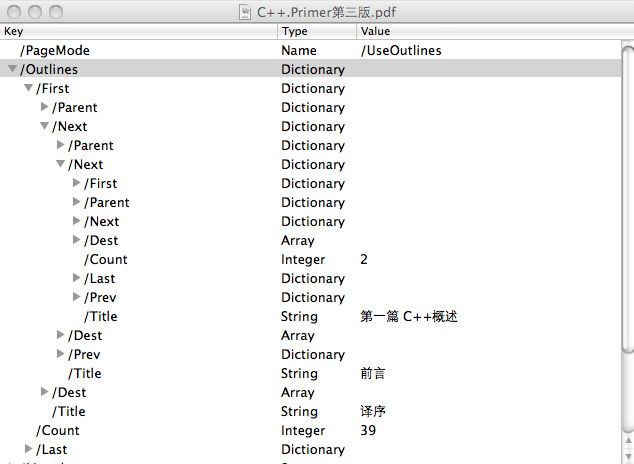
Outlines节点为目录的跟节点,它包含的信息为目录的其实页的字典编号以及尾页的字典编号。 /Count为与First节点平行的节点数目(不过看C++ Primer这边书怎么数都不是39)。
<<
/First dictionary
/Count 39
/Last dictionary
>>
其中/Title对应pdf_outline_s中的 *title
/First /Last 对应 *child
/Next 对应 *next
/Dest 对应 *link ,想知道当前的目录对应于PDF中的哪一页,需要用到此结构 (不同PDF版本此结构有差异,有兴趣的可以自己找找,mupdf适配了不同的差异)
获取pdf_outline的方法
- pdf_outline *outline = pdf_load_outline(xref);
- //获取pdf当前目录对应的页码,需要遍历outline,将outline->link->dest中的refrence与交叉应用表中的page refrence做一个比较。
- int currentPageNum = 0;
- while (outline) {
- for (currentPageNum; currentPageNum < totalPages; currentPageNum++) {
- if (fz_is_array(outline->link->dest)) {
- if (fz_objcmp(pdf_resolve_indirect(fz_array_get(outline->link->dest, 0)),
- xref->page_objs[currentPageNum]) == 0) {
- //currentPageNum为当前outline对应的pdf页码(从0开始)
- LOGE("Got the outline page %d", currentPageNum);
- break;
- }
- }
- }
- outline = outline->next;
- }
搜索(包含中文)
文字选择
文字高亮
(待续。。)
先上一个XOOM平板上的选择效果。可以拖动前后的大头针重新选择区域。
