jgroups API
Reliable group communication with JGroups原文地址: http://jgroups.org/manual/index.html 本站备份: http://javaarm.com/file/opensource/jgroups/jgroups-manual_2014-10-15.zip YBXIANG: JGroups已经发明了10多年了,我们深入研究它,不仅仅可以学到JGroups相关知识,还可以获取各种设计经验等等,这对于提高我们的设计和编码能力是有巨大帮助的。这也是研究并发(concurrent)的一个好例子,“5.4. The concurrent stack”设计的很不错!
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. ybxiang
2014-10-15 发送消息 Table of Contents
1. Overview 1.1. Channel 1.2. Building Blocks 1.3. The Protocol Stack 2. Installation and configuration 2.1. Requirements 2.2. Structure of the source version 2.3. Building JGroups from source 2.4. Logging 2.5. Testing your setup 2.6. Running a demo program 2.7. Using IP Multicasting without a network connection 2.8. It doesn’t work ! 2.9. Problems with IPv6 2.10. Wiki 2.11. I have discovered a bug ! 2.12. Supported classes 3. API 3.1. Utility classes 3.2. Interfaces 3.3. Address 3.4. Message 3.5. Header 3.6. Event 3.7. View 3.8. JChannel 4. Building Blocks 4.1. MessageDispatcher 4.2. RpcDispatcher 4.3. Asynchronous invocation in MessageDispatcher and RpcDispatcher 4.4. ReplicatedHashMap 4.5. ReplCache 4.6. Cluster wide locking 4.7. Cluster wide task execution 4.8. Cluster wide atomic counters 5. Advanced Concepts 5.1. Using multiple channels 5.2. Sharing a transport between multiple channels in a JVM 5.3. Transport protocols 5.4. The concurrent stack 5.5. Using a custom socket factory 5.6. Handling network partitions 5.7. Flushing: making sure every node in the cluster received a message 5.8. Large clusters 5.9. STOMP support【YBXIANG:暂时略过】 5.10. Bridging between remote clusters【YBXIANG:暂时略过】 5.11. Relaying between multiple sites (RELAY2)【YBXIANG:暂时略过】 5.12. Daisychaining 5.13. Tagging messages with flags 5.14. Performance tests 5.15. Ergonomics 5.16. Supervising a running stack 5.17. Probe 5.18. Determining the coordinator and controlling view generation 5.19. ForkChannels: light-weight channels to piggy-back messages over an existing channel 6. Writing protocols 6.1. Writing user defined headers 7. List of Protocols 7.1. Properties availabe in every protocol 7.2. Transport 7.3. Initial membership discovery 7.4. Merging after a network partition 7.5. Failure Detection 7.6. Reliable message transmission 7.7. Message stability 7.8. Group Membership 7.9. Flow control 7.10. Fragmentation 7.11. Ordering 7.12. State Transfer 7.13. pbcast.FLUSH 7.14. Misc
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2. ybxiang
2014-10-15 发送消息 Copyright Red Hat 1998 - 2015
本文档以 "Creative Commons Attribution-ShareAlike (CC-BY-SA) 3.0" 许可证发布。 本文是 JGroups 手册。它提供的信息包括:
本文的焦点是如何使用 JGroups,而不是JGroups是如何实现的。 贯穿本书全文,我遵循下面2点:
那么,一切是如何开始的? 我从1998年到1999年,在康奈尔大学读博士后,在Ken Birman的小组里面。Ken由于发明了"分组通信范式"而成功,尤其是"虚拟同步模型"。那个时候,他们工作在他们的第三代分组通信原型上,该原型叫做Ensemble。Ensemble紧随Horus(由Robbert VanRenesse以C语言编写)之后,Horus又紧随ISIS (由Ken Birman编写,也是用C语言)。Ensemble是用OCaml语言编写的,在INRIA开发,它是一个函数语言,和ML相关。我从来没有喜欢过OCaml语言,在我的脑子里它的语法太丑陋。因此,我也从没有对Ensemble热心过。 然而,Ensemble有一个Java接口(由一个学生在其学期项目中实现),这使得我能够以Java语言编程并使用Ensemble的底层功能。Ensemble的Java部分要求 Ensemble进程 运行在相同的机器上,通过双向管道连接到Ensemble进程上。这个学生已经开发出了一个简单的协议,用于和Ensemble引擎进行交互,并扩展了该引擎,使之能够响应Java。 然而,我依旧需要为每个不同的平台编译并安装Ensemble 运行环境,这正是为什么当初要开发Java的原因:可移植性。 因此,我开始编写一个简单的框架 (就是现在的JChannel),它使得我能够简单地将 Ensemble 当作另外一个分组通信传输协议,它将随时被纯Java解决方案替换掉。不久我就发现,我自己工作在分组通信传输协议的一个纯粹的Java实现上(现在的: ProtocolStack)。我发现一个纯粹的Java实现 将会比Ensemble中编写的一些东西 更有影响力。最终,我没有花费太多的时间写谁都不会看的科技论文 (我猜我不是一个好的科学家,至少不是一个好的理论科学家),而是花时间编写JGroups,它将会有更大的影响力。对于我而言,得知现实生活中的项目/产品正在使用JGroups 比 一篇论文被一个会议或者期刊接收 更有满足感。 这就是为什么在我的学期结束之后,我离开了康奈尔以及学院 并在硅谷的电信行业开始工作的原因。 就在那个时期前后 (2000年5月),SourceForge刚刚开放站点,我决定用它来托管JGroups。这是JGroups的主要爆发时期,因为其它开发人员可以工作在该代码之上。从那以后,JGroups的页面点击和下载量稳步上升。 在2002年秋天,Sacha Labourey联系了我,告诉我 JGroups 被用作JBoss的集群实现。我在2003年加入了JBoss,然后一直工作在JGroups和JBossCache项目上。我的目标是,让JGroups成为Java界中使用最广泛的集群软件... 我想要感谢所有 现在和以前的JGroups贡献者的工作。没有你们,该项目就不会得以成功。 我也想要感谢Ken Birman和Robbert VanRenesse,关于分组通信和分布式系统的方方面面的许多有价值的讨论。 我想要将本手册献给Jeannette, Michelle 以及 Nicole。 Bela Ban, San Jose, Aug 2002, Kreuzlingen Switzerland 2014
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3. ybxiang
2014-10-15 发送消息
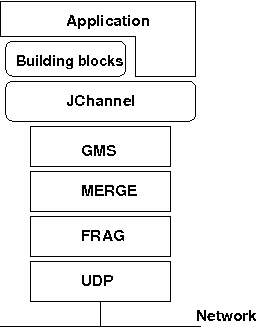
1. Overview分组通信使用了术语 分组(group) 和 成员(member)。成员是分组的一部分。在更加常规的术语中,一个成员是一个节点,一个分组是一个集群。我们混用这些数据。 一个节点是一个进程,位于某个主机上。一个集群可以拥有一个或多个节点。在相同的主机上可以存在多个节点,所有节点可以全部属于相同的集群,也可以只有部分节点属于相同的集群。节点,当然也可以运行在其它主机上。 JGroups是一个用于可靠分组通信的工具。多个进程可以加入一个分组,发送消息到所有组成员或某个成员,也可以从分组中的某些成员接收消息。JGroups系统会追踪每个分组中的各个成员,并且,当有新成员加入分组时 或者 现有成员离开分组或崩溃时,JGroups系统会通知分组成员。一个分组由其名字来标识。不需要明确地创建分组;当一个进程加入一个不存在的分组时,该分组将会被自动创建。一个分组中的多个线程可以位于相同的主机上,可以在相同的LAN之内,也可以跨越一个WAN。一个成员可以属于多个分组。 JGroups的架构展示在 The architecture of JGroups 中。
Figure 1. The architecture of JGroups
它包含3部分: (1) Channel供程序员用于构建可靠的分组通信程序,(2) building blocks, 基于channel之上,提供一个更高的抽象层,(3) 协议栈,实现为特定信道指定的属性。 本文描述如何安装和使用JGroups,也就是Channel API以及building blocks。它所面向的读者是想要利用JGroups来构建可靠的、需要分组通信功能的分布式程序的程序员。 一个信道被连接到一个协议栈。任何时候当应用程序发送一条消息的时候,该信道都会把该消息传递给协议栈,协议栈又会把该消息传递给最顶层的协议。这个顶层协议会处理该消息,然后把它传递给位于它的下一级的协议。就这样,该消息被从一个协议传递到另一个协议,直到底层的(传输)协议把它放到网络上。反方向时,消息处理相同:传输协议监听网络上的消息。当收到消息时,消息会被传递给协议栈,直到该消息到达信道。信道然后调用 应用程序中的receive()回调函数 来递交消息。 当一个应用程序连接到信道时,协议栈就会被启动,当它从该协议栈断开时,协议栈就会被停止。当信道被关闭时,协议栈会被销毁,释放它所占用的资源。 下面的三小节将会概述信道、building blocks以及协议栈。 1.1. Channel(信道)一个进程要想加入一个分组并发送消息,它必须创建一个信道,然后用分组名字连接到该信道上 (所有带有相同名字的信道会形成一个分组)。信道是分组的句柄(XIANG: 操作杆)。当一个成员连接到分组之后,它可以向分组中的所有其它成员发送消息,也可以从它们那里接收消息。客户端通过断开信道来离开一个分组。信道可以被重用:客户端在断开信道之后,可以重新连到该信道上。然而,同一时刻,一个信道只允许一个客户端连上。如果一个客户端想要加入多个分组,那么它可以创建并连接到多个信道上。客户端可以通过关闭信道来表明它不想要再使用一条信道了。之后,该信道就再也不能被使用了。 每条信道都有一个唯一的地址。各个信道总是知道 在这个相同的分组中还包含哪些其它成员:它可以从任何一条信道获取一个成员地址列表。该列表叫做 视图/view。一个进程可以从该列表中选择一个地址,然后发送一条单播消息到该地址 (也可以发给自己),或者发送一条多播消息给位于当前view中的所有成员 (也包括它自己)。任何时候当一个进程加入一个分组或者离开一个分组时,或者检测到有进程崩溃时,一个新的视图将会被发送给所有剩余的组成员。当一个成员进程被怀疑已经崩溃时,所有没问题的成员都会收到一条 怀疑信息。因此,各信道能够接收正常的消息 以及 视图通知和怀疑通知。 通常,信道的属性定义在一个XML文件中,但是JGroups也允许通过简单的字符串、URIs、DOM树、甚至通过程序 进行配置。 Channel API及其相关类 在后面的 API 章节中描述。 1.2. Building Blocks(构建块)信道既简单又原始。它们提供了关于分组通信的朴素功能,它们是根据sockets简单模型而设计的,该模型被广泛使用,而且很好理解。原因是,应用程序可以仅仅使用JGroups的一小部分,而不需要包含所有的、复杂的、甚至不需要的类。此外,相对简单的接口更容易被理解:一个客户端只需要知道5个方法就能够创建并使用一个信道。 信道提供了异步消息发送和接收,有点类似UDP。消息的发送动作本质上是把它放到网络上,然后send()方法立即返回。概念性的请求或它的响应的接收顺序不确定,应用程序必须自己负责对消息及其响应进行匹配。 JGroups提供了构建块,它提供了 基于Channer的、更加复杂的APIs。构建块要么在内部创建和使用信道,要么在创建一个构建块的时,要求指定一个现有的信道。应用程序直接和构建块通信,而不是直接和信道通信。构建块的目的是节省程序员的时间,让他们不必编写冗长乏味的代码以及循环代码,比如对请求-响应进行关联,因此构建块提供了分组通信的一个更高层面的抽象。 构建块在 Building Blocks 描述。 1.3. The Protocol Stack(协议栈)协议栈在一个双向列表中包含了大量的协议层。所有通过信道发送和接收的消息都必须通过所有的协议。每个协议层都可以修改、重新排序或者丢弃消息,或者为消息添加包头。一个分割层可能会将一条消息分割成几条更小的消息,并为每个消息块添加一个带有ID的包头,然后在接收端重组这些消息块。 协议栈的组成,也就是它的各种协议,由信道的创建者来决定:一个XML文件定义了要使用的各种协议 (以及每个协议的各种参数)。该XML配置就可以用于创建一个协议栈。 在应用程序中,只是使用信道的话,关于协议栈的知识不是必需的。然而,如果一个应用程序想要忽略协议栈的默认属性,并配置自己的协议栈时,那么就需要每个协议层是用来做什么的相关知识。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4. ybxiang
2014-10-15 发送消息
2. Installation and configurationYBXIANG:
The installation refers to version 3.x of JGroups. Refer to the installation instructions (INSTALL.html) that are shipped with the JGroups version you downloaded for details. The JGroups JAR can be downloaded from SourceForge. It is named The source code is hosted on GitHub. To build JGroups, ANT is currently used. In Building JGroups from source we’ll show how to build JGroups from source. 2.1. 要求
2.2. 源代码版的结构The source version consists of the following directories and files:
2.3. 从源代码构建JGroups
2.4. 日志JGroups has no runtime dependencies; all that’s needed to use it is to have jgroups.jar on the classpath. For logging, this means the JVM’s logging (java.util.logging) is used. However, JGroups can use any other logging framework. By default, log4j and log4j2 are supported if the corresponding JARs are found on the classpath. 2.4.1. log4j2To use log4j2, the API and CORE JARs have to be found on the classpath. There’s an XML configuration for log4j2 in the conf dir, which can be used e.g. via log4j2 is currently the preferred logging library used by JGroups, and will be used even if the log4j JAR is also present on the classpath. 2.4.2. log4jTo use log4j, the log4j JAR has to be found on the classpath. Note though that if the log4j2 API and CORE JARs are found, then log4j2 will be used, so those JARs will have to be removed if log4j is to be used. There’s an XML configuration for log4j in the conf dir, which can be used e.g. via 2.4.3. JDK logging (JUL)To force use of JDK logging, even if the log4j(2) JARs are present, 2.4.4. Support for custom logging frameworksJGroups allows custom loggers to be used instead of the ones supported by default. To do this, interface The implementation needs to return an implementation of To force using the custom log implementation, the fully qualified classname of the custom log factory has to be provided via 2.5. 测试你的设置To see whether your system can find the JGroups classes, execute the following command: java org.jgroups.Version or java -jar jgroups-x.y.z.jar You should see the following output (more or less) if the class is found: $ java org.jgroups.Version Version: 3.5.0.Final
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5. ybxiang
2014-10-15 发送消息
2.6. 运行演示程序To test whether JGroups works okay on your machine, run the following command twice: java -Djava.net.preferIPv4Stack=true org.jgroups.demos.Draw
2 whiteboard windows should appear as shown in Screenshot of 2 Draw instances. 
Figure 2. Screenshot of 2 Draw instances
If you started them simultaneously, they could initially show a membership of 1 in their title bars. After some time, both windows should show 2. This means that the two instances found each other and formed a cluster. When drawing in one window, the second instance should also be updated. As the default group transport uses IP multicast, make sure that - if you want start the 2 instances in different subnets - IP multicast is enabled. If this is not the case, the 2 instances won’t find each other and the example won’t work. You can change the properties of the demo to for example use a different transport if multicast doesn’t work (it should always work on the same machine). Please consult the documentation to see how to do this. State transfer (see the section in the API later) can also be tested by passing the 2.7. 在没有网络连接的情况下使用IP多播Sometimes there isn’t a network connection (e.g. DSL modem is down), or we want to multicast only on the local machine. For this the loopback interface (typically lo) can be configured, e.g. route add -net 224.0.0.0 netmask 240.0.0.0 dev lo
This means that all traffic directed to the The above instructions may also work for Windows systems, but this hasn’t been tested. Note that not all operating systems allow multicast traffic to use the loopback interface. Typical home networks have a gateway/firewall with 2 NICs: the first (e.g. 2.8. 不工作!
Make sure your machine is set up correctly for IP multicasting. There are 2 test programs that can be used to detect this: McastReceiverTest and McastSenderTest. Start java org.jgroups.tests.McastReceiverTest
Then start java org.jgroups.tests.McastSenderTest
If you want to bind to a specific network interface card (NIC), use You should be able to type in the McastSenderTest window and see the output in the McastReceiverTest. If not, try to use Other means of getting help: there is a public forum on JIRA for questions. Also consider subscribing to the javagroups-users mailing list to discuss such and other problems. 2.8.1. mcastInstead of
2.9. IPv6相关问题Another source of problems might be the use of IPv6, and/or misconfiguration of java -Djava.net.preferIPv4Stack=true org.jgroups.demos.Draw -props /home/bela/udp.xml The JDK uses IPv6 by default, although is has a dual stack, that is, it also supports IPv4. Here’s more details on the subject. 2.10. WikiThere is a wiki which lists FAQs and their solutions at http://www.jboss.org/wiki/Wiki.jsp?page=JGroups. It is frequently updated and a useful companion to this manual.
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6. ybxiang
2014-10-15 发送消息
2.11. 我发现了一个bug!If you think that you discovered a bug, submit a bug report on JIRA or send email to the jgroups-users mailing list if you’re unsure about it. Please include the following information:
2.12. 支持的classesJGroups project has been around since 1998. Over this time, some of the JGroups classes have been used in experimental phases and have never been matured enough to be used in today’s production releases. However, they were not removed since some people used them in their products. The following tables list unsupported and experimental classes. These classes are not actively maintained, and we will not work to resolve potential issues you might find. Their final faith is not yet determined; they might even be removed altogether in the next major release. Weight your risks if you decide to use them anyway.
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
7. ybxiang
2014-10-15 发送消息
2.12.1. 试验性的classes
2.12.2. 不再支持的classes
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8. ybxiang
2014-10-15 发送消息
3. API本章介绍JGroups中用来构建可靠分组通信应用程序的那些classes。焦点是创建和使用信道。 本文中的信息可能不是最新的,但是我们在这里描述的JGroups中的这些classes的性质是相同的。要想获取最新的信息,请参见 在这里讨论的所有的classes都位于 org.jgroups 包下面,除非额外提到的那些classes。 3.1. 辅助类
3.1.1. objectToByteBuffer(), objectFromByteBuffer()第一方法以一个对象作为其参数,该方法用于把该对象序列化为一个byte buffer (该对象必需实现java.io.Serializable接口 或者 java.io.Externalizable接口)。该方法返回一个字节数组。这个方法通常用于将对象序列化为消息的byte buffer(YBXIANG:参见Message(Address dest, Address src, Object obj)这个构造函数如何调用org.jgroups.Message.setObject(Object))。第二个方法从一个buffer返回一个重构之后的对象。这2个方法会抛出异常,如果对象不能被序列化或反序列化的话。 3.1.2. objectToStream(), objectFromStream()第一个方法接受一个对象作为参数,该方法将该对象 写入 作为参数传入的输出流。第二个方法接受一个输入流,并从这个输入流中读取一个对象。这两个方法会抛出异常,如果该对象不能被序列化或反序列化的话。 3.2. 接口这些接口 被下面所描述的APIs使用,因此首先把它们列出来。 3.2.1. MessageListener(消息监听器)下面这个MessageListener接口为消息接收以及状态的读取与设置提供了回调函数: 一旦收到了消息, 3.2.2. MembershipListener(成员关系监听器)MembershipListener接口类似于 通常,唯一需要实现的回调方法是viewAccepted(View new_view),它会在新的成员加入了分组或者现有的成员离开了分组或者崩溃的时候,通知接收者。当一个成员被怀疑已经崩溃、但是还没有从分组中排除掉的时候,JGroups就会调用回调函数suspect(Object suspected_mbr) [1]。
因此
3.2.3. Receiver
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9. ybxiang
2014-10-15 发送消息
3.2.4. ReceiverAdapter整个class实现了 Receiver接口,对该接口做了空操作实现。当我们要实现一个回调函数的时候,我们可以简单地扩展 ReceiverAdapter 并覆写其 receive()方法,以避免实现Receiver接口的所有回调函数。 ReceiverAdapter看起来如下: ReceiverAdapter是实现各种回调方法的推荐方式。
3.2.5. ChannelListener实现ChannelListener的类 可以使用 Channel.addChannelListener()方法 将其注册到一个channel中,用于获取channel的状态改变信息。不论合适,如果一个信道被关闭了、断开了或者打开了,相应的回调方法就会被触发。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
10. ybxiang
2014-10-15 发送消息
3.3. Address分组中的每个成员都有一个地址,该地址用于唯一标识该成员。这样的地址的接口是
地址的实际实现类通常由最底层的协议层(比如UDP或者TCP)来生成。这就使得各种地址都可以在JGroups中使用。 既然一个地址唯一地标识一个信道,也因此能够唯一标识一个分组成员,那么地址就可以用来 将消息发送到该分组成员,也就是说在Messages中设置地址 (参见下一节)。 地址的默认实现是 UUIDs从不直接显示出来,而是显示为一个逻辑名字 (参见 3.8.2 Logical names)。这是通过用户或者JGroups为一个节点设置的名字,其唯一的目的是使得日志输出信息可读性更好。 UUIDs 可以映射到 IpAddresses,后者包括IP地址和端口。IP地址和端口最终会被传输协议用于发送消息。 3.4. Message数据在成员之间以消息( 
Figure 3. Structure of a message
一条消息有5个区域:
一条消息类似一个IP数据包,包含 payload (a byte buffer) 以及 发送者和接收者的地址 (Addresses)。任何放到网络上的数据都可以被转发到其目标(接收者地址),可以将响应 返回到 接收者地址。 发送者在发送消息的时候,通常不需要在消息中填充发送者的地址;在消息被放到网络上之前,协议栈会自动处理。然而,有些情况下,消息发送者不想要填入自己的地址,比如说,用来将响应返回给其它成员。 目标地址(接收者) 可以是一个Address,它代表了一个成员的地址,比如说,从之前接收到的消息中获取到该地址,该地址也可以是null,这就意味着该消息将会被发送给分组中的所有成员。一个常规的多播消息,比如说发送字符串 3.5. Header(头数据)头数据 是客户化的信息,可以添加到每条消息。JGroups大量地使用了头数据,比如为每条消息添加序列号(NAKACK 和 UNICAST),这样这些消息就会以发送时的顺序被传递给接收者。 3.6. Event事件 是JGroups中各种协议的交互方式。事件和Messages在分组成员之间的网络上传输相反,事件只在协议栈中上下传递。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
11. ybxiang
2014-10-15 发送消息
3.7. View视图( 请注意,视图的第一个成员是 协调者 (它会发送出新的视图)。这样,任何时候,当成员关系发生变化时,每个成员都可以轻易地判定谁是协调者,取出视图中的第一个成员既可,而不需要和其它成员进行联系。 下面的代码展示了如何发送一条(单播)消息到视图的第一个成员 (我们省略了错误监测代码): 任何时候,当一个应用程序被通知 新的视图被安装了 (比如,通过
YBXIANG 带有多个节点的View.toString():
[WIN7U-20140428K-59794|0] (1) [WIN7U-20140428K-59794] 3.7.1. ViewId
3.7.2. MergeView任何时,当一个分组分裂成多个子分组(比如说,由于网络分裂导致),然后子分组又合并回来,那么应用程序将会收到一个
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
12. ybxiang
2014-10-15 发送消息
3.8. JChannel一个进程要想缴入一个分组然后发送消息,它必需创建一条信道。信道就像socket。当客户端连接到一条信道上时,会给出该客户端想要加入的分组的名字。这样,一条信道总是和一个特顶的分组相关联(在其连接状态中)。协议栈负责让带有相同分组名字的各条信道 相互找到对方:任何时候,当一个客户端连接到一条信道时,为该信道设置一个分组名字G,然后该信道就会查找带有相同分组名字的、已经存在的信道,然后加入它们,导致一个新的视图(包含新的成员)被装入这些信道。如果不存在现有的成员,那么就会创建一个新的分组。 信道的主要状态的状态转移图 展示在下面的 [ChannelStatesFig] 这幅图中。 当一条信道首次被创建时,它处于 未连接(unconnected) 状态。 如果视图执行只有在已连接(connected)状态下才有效的操作(比如发送/接收消息)的话,就会导致异常。 在客户端成功连接之后,信道就会进入 已连接(connected)状态。现在,该信道将会从其它成员接收消息,也可以相其它成员或者整个分组发送消息,当有新的成员加入或离开时,该信道会被通知。在这个状态下,获取该信道的本地地址 肯定是一个合法的操作 (见下)。 当信道被断开时,它就回到 未连接(unconnected)状态。已连接(connected)和未连接(unconnected)状态下的信道都可以被关闭,这样做该信道就不能再使用了。任何操作都会导致异常。当一条处于 已连接(connected) 状态的信道被直接关闭时,它会首先被断开,然后被关闭。 现在,我们描述创建和操作信道的各种方法。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
13. ybxiang
2014-10-15 发送消息
3.8.1. Creating a channel我们通过信道的公开构造函数(比如 new JChannel())来创建一条信道。 JChannel 最常用的构造函数如下: 这个 props 参数指向一个XML文件,该XML文件它包含了将要被使用的协议栈的配置信息。该参数可以是一个字符串,但是还有其它的构造函数,它们可以接受诸如DOM元素或URL之类的参数 (详细信息请参见 javadoc)。 下面的实例代码展示了如何基于一个XML配置文件创建一条信道: 如果这个 props 参数是 null,则使用默认的属性。如果无法创建该信道,那么就会抛出异常。可能的原因包括 没有找到由这个prop参数所指定的协议,或者协议参数错误。 比如,我们可以用下面的命令启动 Draw 示例: java org.javagroups.demos.Draw -props file:/home/bela/udp.xml
或者 java org.javagroups.demos.Draw -props http://www.jgroups.org/udp.xml
后面这种情况下,应用程序会从一台服务器下载它的协议栈,这使得我们可以对应用程序的属性进行集中管理。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
14. ybxiang
2014-10-15 发送消息
一个示例XML配置文件看起来如下(根据
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
15. ybxiang
2014-10-15 发送消息
一个协议栈用 每个协议都由一个Java类实现。当我们根据上面的XML文件创建一个协议栈时,第一个元素("UDP")变成了最底部的协议层,第二个元素(对应的协议层)被放在第一个(元素对应的协议成)之上,等等;协议栈是从底部 创建到 顶部的。 每个元素的名字 都必需是 位于 每个协议层都有0个或多个参数,直接在尖括号中的 协议名字的后面 用一列name/value pairs来指定参数。这上面这个例子中,我们为 UDP协议配置了一些选项,其中一个是 IP多播端口(
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
16. ybxiang
2014-10-15 发送消息
通过程序创建协议栈通常,我们通过传入JChannel()构造函数中的一个XML配置文件来创建信道。基于这个声明式的配置之上,JGroups提供了一个API,用于通过程序的方式来创建一条信道。 做法是,首先创建一个JChannel,然后创建一个ProtocolStack实例,然后把所有期望的协议都添加到该协议栈中,最后调用该协议栈的 下面是如何通过程序方式来创建一条信道的例子 (拷贝自 首先,我们创建了一个 JChannel (1)。其中的 接着,所有协议被添加到该协议栈中(3)。请注意,添加顺序是从底部协议(传输协议)到顶部协议。因此作为传输协议的 一旦协议栈被配置好了,我们就调用
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
17. ybxiang
2014-10-15 发送消息
3.8.2. Giving the channel a logical name我们可以为信道指定一个逻辑名字,信道就会使用这个逻辑名字 而不是使用 信道地址 比如,假如我们有3个信道,使用了逻辑名字,那么我们肯那个看到这样的一个视图 如果没有设置逻辑名字,那么JGroups会生使用主机名以及随机数成一个,比如 可以用下面的方法来设置信道的逻辑名字: 必须在连接信道之前设置逻辑名字。注意,逻辑名字一致驻留在信道中,直到信道被销毁,否则(如果没有设置逻辑名字),信道会在链接的时候创建一个UUID。 当JGroups启动的时候,它可能会打印出逻辑名字以及相关的物理地址: -------------------------------------------------------------------
GMS: address=mac-53465, cluster=DrawGroupDemo, physical address=192.168.1.3:49932
-------------------------------------------------------------------
逻辑名字是 YBXIANG测试:
3.8.3. Generating custom addresses自从 2.12 版本之后,地址生成功能是可以插入的。这意味着,如果一个应用程序可以决定它想要使用什么样的地址。默认的地址类型是 客户化的地址可以用于传递额外的数据,比如关于节点的位置信息。请注意,在客户化的地址(UUID的子类)中,不应该修改UUID父类的equals()、hashCode() 以及 compare() 方法。 要想使用客户化的地址,必须实现 对于任何 CustomAddress类,要想正确地对它进行序列化的话,需要将它注册到ClassConfigurator中:
然后在 JGroups中有个子类例子是 YBXIANG实践(JGroups-3.5.1):
3.8.4. Joining a cluster当一个客户端想要加入一个集群的时,它会利用想要加入的集群的名字来连接到一条信道: 这里的集群名字是客户端将要加入的集群的名字。所有用相同的名字进行连接的信道会形成一个集群。发送到集群中的任何一条信道上的消息都会被所有的成员收到 (包括发送者)。
3.8.5. Joining a cluster and getting the state in one operation客户端可以在一个操作中执行 加入集群并获取集群状态。理解连接和获取状态的方法的概念的最好的办法是将其看作是对常规的 就像在常规的 connect() 方法中一样,cluster名字表示将要加入的集群。target参数标识了将要从中获取状态的那个集群成员。如果target为null,则表明应该从集群的协调者(cluster coordinator)那里获取状态。如果想要从某个特定的成员中获取状态,而不是从协调者获取,那么客户端只要提供该成员的地址既可。timeout参数设置了整个加入集群和获取状态操作的时间限制。如果超时了,就会抛出异常。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
18. ybxiang
2014-10-15 发送消息
3.8.6. Getting the local address and the cluster name
再一次,如果信道处于 断开或关闭 状态,该方法的结果是不确定的。 3.8.7. Getting the current view下面这个方法可以用于获取某个信道的当前视图: 该方法返回这个信道的当前视图。每当一个新的视图被安装(通过 对处于 未连接或已关闭 状态的信道调用这个方法,返回结果是由信道的实现来定义的。信道可以返回null,也可以返回它所知道的最后一个视图。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
19. ybxiang
2014-10-15 发送消息
3.8.8. Sending messages一旦信道连接上,就可以通过 第一个 其它 如果信道没有连接上,或者关闭了,在试图通过这些方法发送消息时,异常就会被抛出。 这里有一个将一条消息发送给所有成员的一个例子:
这里有一个将一条单播消息发送给某分组中的第一个成员(协调者)的例子: 该示例代码找到了协调者(试图中的第一个成员),然后向它发送了一条"hello world"消息。 Discarding one’s own messagesYBXIANG:抛弃自己发出的消息,前面已经有描述。 有时候,我们不想要处理自己的消息,也即是说,由自己发送出去的消息。要想做到这点,可以将 请注意,这个方法替代了旧的 Synchronous messages【同步发送消息】经 JGroups 确保了消息最终会被发送给所有 无故障的成员,有时候,这可能需要一点时间。比如,如果我们有个基于"negative acknowledgments"重新传输协议,最后一条发送出去的消息丢失了,那么在该消息被重新传输之前,接收者必须等待,直到这个稳定性协议注意到该消息已经丢失了。 可以通过在消息中设置 Message.RSVP 标志位来改变这种行为:当遇到这个标志位时,消息发送操作就会阻塞,直到所有的成员都告知 该消息已经收到 为止 (当然,不包括已经崩溃或者正在离开的那些成员)。 该功能还可以用于另外一个目的:如果我们发送了一条打过RSVP标签的消息,那么,当send()返回时,我们被确保:之前发送出去的消息 也已经被全部交付给所有成员了。因此,举个例子,如果P发送消息1-10,并将消息10打上RSVP标签,那么当JChannel.send()返回时,P就会直到所有成员都已经收到了从P发出的消息 1-10。 请注意,由于打过RSVP标记的消息的发送操作 开销比较大,可能会将发送者阻塞一会儿,因此应该保守地使用。比如,在运算一个工作单元时(也就是P发送N条消息),P需要确定所有消息都被所有成员收到了,因此可以使用RSVP。 要想使用RSVP,需要做2件事: 首先,需要在配置文件中添加 第二,将那些期望确认收到的消息标记为 这里,我们将一条消息发送给所有集群成员( 如果 关于RSVP的配置 RSVP 小节描述。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
20. ybxiang
2014-10-15 发送消息
Non blocking RSVP有时候,发送者期望某条消息被重发,直到它被确认收到或者出现超时为止,但是不期望阻塞发送者。比如 要想解决这个问题,可以使用
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
21. ybxiang
2014-10-15 发送消息
3.8.9. Receiving messages我们可以覆写ReceiverAdapter (或 Receiver)中的 我们可以利用 3.8.10. Receiving view changes如上所示,任何时候,当集群成员关系发生变化时,我们可以用ReceiverAdapter的 如我们在ReceiverAdapter中所讨论的,在回调中的代码必须避免任何需要消耗很多时间的东西,也要避免 阻塞操作;JGroups将该回调方法(YBXIANG:指的是ReceiverAdapter.viewAccepted()方法)作为视图安装的一个步骤进行调用,如果在该回调方法中的用户代码阻塞住了,那么视图的安装过程也会阻塞。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
22. ybxiang
2014-10-15 发送消息
3.8.11. Getting the group’s stateYBXIANG提醒:本小节所描述的getState()方法有2个,一个是状态请求者通过信道读取状态org.jgroups.JChannel.getState(Address, long);另外一个是状态提供者通过 org.jgroups.ReceiverAdapter.getState(OutputStream)回调方法 对外提供状态。 一个新加入的成员在开始工作之前,可能想要接收该集群的状态。可以通过 该方法返回一个成员的状态 (通常是最老的那个成员,也就是协调者)。在向当前的协调者请求状态时,target参数通常可以是null。如果获取状态超时了,那么就会抛出异常。超时时间0将会等待,直到所有状态都传输完毕。
要想参与状态传递,状态提供者和状态请求者都必须实现下面来自ReceiverAdapter (Receiver)的回调方法:
在一个包含了A、B和C的集群中,如果D视图加入该集群,并调用了
下面的代码片段展示了一个分组成员如何参与状态传递: 该代码来自JGroups教程中的Chat例子,其状态是一列字符串。 这个 这个 State transfer protocols要想使用状态传递功能,必须在配置中包含状态传递协议。可以是
STATE_TRANSFER
这时原始的状态传递协议,它用于传输 请注意,由于 更多细节请参见 pbcast.STATE_TRANSFER。
STATE
这时 更多细节请参见pbcast.STATE.
STATE_SOCK
和 For details see STATE_SOCK.
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
23. ybxiang
2014-10-15 发送消息
3.8.12. Disconnecting from a channel通过下面的方法从一条信道断开: 如果该信道已经处于断开状态或者关闭状态,该方法不起任何作用。如果信道处于连接状态,它将离开该集群。该功能是通过发送一条离开请求到当前协调者来实现的(对于一个信道用户而言,是透明的)。后者将会因此从视图中删除这个正在离开的节点,并将新的视图安装到所有的剩余成员中。 信道在成功断开之后,它将进入 未连接 状态,它可以在以后重连。 3.8.13. Closing a channel要想摧毁一个信道实例(摧毁相关的协议栈并释放所有的资源),可以使用 对一条已经连接的信道进行关闭,会首先断开该信道。 该close()方法会将信道移入关闭状态,在该状态下,再也不能执行操作了 (当调用一条已经关闭的信道时,大多数情况下会抛出一个异常l)。在该状态下,信道实例再也不能被应用程序使用了 — 当重新设置该实例的reference时,该信道实际上只会处于游荡状态,直到被Java运行系统进行垃圾回收。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
24. ybxiang
2014-10-15 发送消息
4. Building Blocks构建块是基于信道之上的,当需要更高层面的接口时,可以使用它,而不是信道。 信道是简单的、类似socket的结构,而构建块可以提供复杂得多的接口。在某些情况下,构建块提供对底层信道的访问,因此如果构建块不能提供某种功能,那么可以直接访问其信道。构建块位于相关类位于 4.1. MessageDispatcherChannels是用于异步发送和接收消息的简单模式。然而,在分组通信中,大量的通信模式需要同步通信。比如,某个发送者希望发送一条消息到分组中,并等待所有的响应。或者,应用程序期望发送一条消息到分组中,然后等待直到大多数接收者发回了响应或者出现超时。 MessageDispatcher提供了阻塞的(以及非阻塞的)请求发送以及响应关联。它提供了同步的(以及异步的)消息发送功能 以及 请求-响应相关联功能,比如将一个或多个响应和原来的请求进行匹配。 使用这个class的一个例子是:发送一条消息到所有的集群成员,然后阻塞等待,直到收到所有的确认响应或者出现超时。 相对于RpcDispatcher而言,MessageDispatcher处理的是 发送消息请求 以及 关联消息的响应,而RpcDispatcher处理的是 触发方法调用 以及关联响应。RpcDispatcher 扩展了MessageDispatcher,提供了基于MessageDispatcher之上的、更高级别的抽象。 RpcDispatcher本质上是一种对一个集群触发远程过程调用的方法。 MessageDispatcher和RpcDispatcher两者都基于信道之上;因此MessageDispatcher的实例是利用一个信道作为参数进行创建的。它既可扮演客户端角色,也可以扮演服务器端角色:一个客户端发送请求并接收响应,一个服务器端接收请求并发送响应。MessageDispatcher允许应用程序同时扮演两种角色。要想扮演服务器端的角色对请求作出响应,可以实现
在研究MessageDispatcher的方法之前,让我们首先看看RequestOptions。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
25. ybxiang
2014-10-15 发送消息
4.1.1. RequestOptions在MessageDispatcher发送的每条消息或者在RpcDispatcher中触发的每个请求触发都由一个RequestOptions实例进行管理。该class可以被传递给一个调用,用于定义和该调用相关的各种选项,比如超时时间、调用是否应该阻塞以及各种标志信息(参见 5.13 Tagging messages with flags) 等等。 各种选项包括:
如何使用 RequestOptions 的一个例子是: 发送请求的方法是:
一个
使用这些构建块的好处之一就是,故障成员会被从期望的响应集合中删除。比如,当我们发送一条消息给10个成员并等待所有响应的时,2个成员在将响应发送出去之前崩溃了,该调用就会返回8个有效的响应以及2个被标记为失败的响应。castMessage() 的返回值是一个RspList,它包含了所有的响应(我们没有显示所有的方法):
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
26. ybxiang
2014-10-15 发送消息
4.1.2. Requests and target destinations当一个非空的地址列表(作为目标地址列表)被传递给 如果我们想要将某消息的接收者限制为这些目标成员,那么有几个方法可疑实现:
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
27. ybxiang
2014-10-15 发送消息
4.1.3. Example本节展示一个如何使用MessageDispatcher的例子。 这个例子首先创建了一条信道。接着,基于该信道创建了一个MessageDispatcher实例。然后连接该信道。从现在开始,MessageDispatcher将会发送请求,接收匹配的响应(扮演客户端角色),同时,接收请求并发送响应(扮演服务器端角色)。 然后我们发送10条消息到分组中并等待所有的响应。超时时间参数设置为0,这会导致相关调用一直阻塞着,直到收到所有的响应。
最后,MessageDispatcher和该信道都被关闭。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
28. ybxiang
2014-10-15 发送消息
4.2. RpcDispatcher【YBXIANG:这一节非常重要!】
和MessageDispatcher比较起来,没有 要想触发远程方法调用(单播和多播),使用下面的方法:
可以通过(1)方法名、(2)参数、和(3)参数类型来指定将要被调用的方法,也可以使用MethodCall (包含了一个 和MessageDispatcher一样,返回值为一个
在目标成员中,我们可以用Java的反射API,根据方法名和所提供的参数的数量以及类型,找出要执行的确切方法。如果无法找出某个方法,将会抛出一个运行期异常。 请注意,我们也应该使用method IDs 以及
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
29. ybxiang
2014-10-15 发送消息
4.2.1. Example下面的代码展示了如何使用RpcDispatcher的一个例子: RpcDispatcher这个类定义了一个 如我们所见,RpcDispatcher这个构建块 通过提供应用程序和原始信道之间的一个更高的抽象层,减少了大量的、用于实现基于RCP的分组通信的应用程序代码。 Asynchronous calls with futures当我们触发一个同步调用时,调用线程将会被阻塞,直到收到响应为止。 Future返回允许调用者立即返回,并在之后抓取调用结果。在2.9版本中,RpcDispatcher新增了2个方法,它们返回futures。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
30. ybxiang
2014-10-15 发送消息
4.2.2. Response filters响应过滤器允许应用程序代码 对从集群成员接收响应 进行干涉,也可以让 {请求-响应}的执行与关联操作代码知道:(1)是否可以接收某条响应,(2)是否需要接收更多的响应,或者说,该调用(如果是阻塞式的)是否可以返回。
下面的实例代码展示了如何使用一个RspFilter: 这里,我们调用了一个集群范围内的RPC (dests=null),该调用会阻塞着(mode= 该过滤器接受所有值大于2的响应,一旦收到满足上述条件的2个响应之后,就立即返回。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
31. ybxiang
2014-10-15 发送消息
4.3. Asynchronous invocation in MessageDispatcher and RpcDispatcher默认情况下,MessageDispatcher 或 RpcDispatcher会通过调用RequestHandler的handle()方法,将接收到的消息派发给应用程序: 在RpcDispatcher中,它的 该调用是同步的,也就是说,它是在一个线程中执行的,该线程负责将这条特殊的消息从网络派发出去,向上传递经过协议栈,进入应用程序。因此,在这个方法调用期间,该线程是无用的。 如果调用需要一些时间,比如,需要获取锁或者应用程序需要等待某些I/O操作,由于当前线程处于繁忙状态,所以就会使用另外一个线程来处理不同的请求消息。这就会很快地导致线程池被耗尽,或者,如果线程池带有关联的队列的话,许多消息就会进入队列进行排队。 因此,我们发明了一种新的方法,用于将消息派发给应用程序;异步调用API: AsyncRequestHandler接口扩展了RequestHandler,并添加了一个额外的方法,该方法接收一个请求消息(Message)参数和一个Response对象参数。该请求消息包含的信息和前面的请求消息包含的信息一样 (比如,一个方法调用及其参数)。当处理完毕时,这个Response参数用于在之后发送一个回复(如果需要的话)。 Response封装了与请求的相关信息 (比如请求ID以及发送者),它有一个用于发送响应的 新的API的优势是,它可以,但不是必须的,被异步使用。其默认实现,依旧使用同步调用风格: 当 然而,应用程序可以扩展MessageDispatcher或RpcDispatcher (就像在Infinispan中所做的一样),也可以通过 可以使用 通常,异步调用和应用程序的线程池联合使用。应用程序知道(JGroups不知道)哪些请求是可以并行处理的,哪些是不能的。比如,所有的OOB调用都应该被直接地派发给线程池,因为OOB请求的顺序不重要,但是常规的请求应该被添加到一个队列中,按照次序处理。 这样做的主要好处是,请求派发(以及排序)现在处于应用程序的掌控之中了,如果应用程序想要这么做的话。如果应用程序不想掌控这些,我们依旧可以使用同步调用。 使用异步调用显得很合理的一个例子是,web session复制。如果一个集群节点A有1000个web sessions,那么在集群之中,对这些web sessions的更新信息进行复制所产生的消息来自A。由于JGroups会按照顺序将来自相同发送者的消息递交出去,因此,它也会按照严格的顺序将 与用户消息不相关的web session的更新信息 发送出去。 有了异步调用,应用程序可以设计出消息派发策略,该策略可以将不同的(不相关的)web session的更新信息指派给线程池中任何可用的线程,但是将相同的session的更新信息放入队列,然后用相同的线程处理它们,从而按照顺序处理相同session的更新信息。这么做会加速整体处理速度,因为对A上的某个web session 1的更新操作 不必等到 同样来自A的、与web session 1不相关的web session 2的所有更新处理完毕之后才进行。 这和SCOPE协议试图实现的功能类似。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
32. ybxiang
2014-10-15 发送消息
4.4. ReplicatedHashMap该class用于演示如何在集群中的各节点之间共享状态。我们从没有对它进行过高度的测试,因此不能直接将其用于产品环境中。 ReplicatedHashMap在内部使用了一个并发的hashmap,允许在不同的进程中创建多个hashmaps实例(YBXIANG: 指的是ReplicatedHashMap)。所有这些实例总是具有完全相同的状态。在创建这样的实例时,集群的名字决定了集群中的哪些hashmaps参与复制。新的实例在对请求提供服务之前,将会从现有的集群成员中查询状态,并更新它自己的状态。如果还不存在集群成员,那么它会以空状态启动。 诸如 由于hashtable的keys和values都会被通过网络发送出去,因此,它们必须是可序列化的。如果将一个不可序列化的值放入map中,在对其序列化期间会导致一个异常。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
33. ybxiang
2014-10-15 发送消息
4.5. ReplCache
复制技术取值为-1的话,这意味着{K 和 V}应该被存储在所有的集群成员中。 一个key K以及应该存储它的集群成员之间的映射 总是确定的,是通过一个 持续性哈希函数计算出来的。 请注意,这个class用于展示如何在集群中的节点之间共享状态。我们从没有对它进行过高度的测试,因此不能直接将其用于产品环境中。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
34. ybxiang
2014-10-15 发送消息
4.6. Cluster wide locking在2.12版本中,添加了一个新的分布式的锁定服务,用于替换
下面是一个经典的如何使用LockService的例子: // locking.xml需要包含一个锁定协议,比如CENTRAL_LOCK
JChannel ch=new JChannel("/home/bela/locking.xml");
LockService lock_service=new LockService(ch);
ch.connect("lock-cluster");
Lock lock=lock_service.getLock("mylock"); // gets a cluster-wide lock
lock.lock();
try {
// do something with the locked resource
}
finally {
lock.unlock();
}
在这个例子中,我们创建了一个信道,然后创建了一个 请注意,锁的拥有者总是集群中的某个线程,因此,锁的拥有者具有JGroups地址以及相关线程的ID。这意味着,如果位于相同JVM中的不同的线程试图获取名字相同的锁,那么它们就会竞争该锁。如果
JGroups包含了一个实例类( 当前 (Jan 2011),JGroups中有2个提供锁功能的协议:PEER_LOCK (过时了) 以及 CENTRAL_LOCK (推荐)。锁协议必须位于或者靠近协议栈的顶部(靠近信道)。【YBXIANG:协议栈的顶部,指的是靠近应用程序的那一段;协议栈的底部,指的是靠近传输网络的那一端,通常是UDP/TCP协议】
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
35. ybxiang
2014-10-15 发送消息
4.6.1. Locking and merges下面的场景是对网络分区和后期合并敏感的场景:我们有一个集群视图
因此,这里的推荐解决方案是,让各节点监听
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
36. ybxiang
2014-10-15 发送消息
4.7. Cluster wide task execution2.12版的JGroups中,加入了一个分布式的执行服务。这个新的服务作为一个协议实现,通过
下面是一个经典的如何使用ExecutionService的一个例子: 在这个例子中,我们创建了一个信道,然后创建了一个ExecutionService,接着连接该信道。然后我们提交我们的Callable任务,该操作返回一个Future。然后我们等待该Future返回我们的值,然后对该值进行相关处理。如果出现任何异常,我们打印出该异常的栈追踪信息。 ExecutionService 严格地遵循Producer-Consumer模式。在这种模式下,ExecutionService作为Producer。因此,该服务只将要被处理的任务传递出去,不对这些任务执行任何实际的调用。我们单独为consumer编写了一个类,可以在集群中的任何节点上运行它。这个类是ExecutionRunner,它实现了java.lang.Runnable接口。 JGroups要求用户在集群中的一个节点上运行一个或多个ExecutionRunner实例。通过让一个线程运行某个ExecutionRunner实例,这样,该线程不会主动地运行通过ExecutionService提交到集群中的任何任务。这使得集群中的任何节点都可以参与或者不参与运行这些任务,此外,任何节点可以选择性地运行多个ExecutionRunner,如果该节点具有额外的运行能力的话。一个ExecutionRunner会无休止地运行下去,直到运行该ExecutionRunner的线程被中断。如果该ExecutionRunner被中断时,一个任务正在运行,那么该任务也会被中断。【YBXIANG:如何中断某个任务(比如正在写文件的任务)?】 下面有个例子,展示了启动一个单一节点,然后让10个分布式任务同时在它上面运行是多么容易: 在这个例子中,我们创建一个信道,然后连接该信道,接着创建了一个ExecutionRunner。然后我们创建了一个java.util.concurrent.ExecutorService,我们用它启动10个工作线程,每个工作线程都运行该ExecutionRunner。这样,该节点具有10个线程,不断地接受并处理通过ExecutionService提交到集群中的各个请求。 由于ExecutionService不允许非序列化的class实例作为任务进行传递,JGroups提供了2个辅助类来解决这个我难题。对于那些习惯了使用带有Executor的CompletionService的用户,JGroups提供了一个对等的ExecutionCompletionService,它为用户提供了相同的功能。JGroups本来打算优先使用ExecutorCompletionService,但是由于它的实现使用了 非序列化对象,因此JGroups实现了ExecutionCompletionService,用于和ExecutorService联合使用。 JGroups也设计了辅助类,用于帮助用户提交通过非序列化class实现的任务。Executions类包含了一个叫做serializableCallable的方法,该方法允许用户传入实现了Callable接口的class的一个构造函数及其参数,然后返回给用户一个Callable,它将会在运行期间自动地根据该构造函数创建相关对象,并将相关参数传给它,然后调用该对象的call方法,最后将其结果作为一个常规的callable返回。所有提供的参数仍然必须是可序列化的,返回对象如前所述。 JGroups包含了一个演示类 ( 当然 (July 2011),JGroups带有1个提供执行功能的协议:CENTRAL_EXECUTOR。该执行协议必须位于或者靠近协议栈的顶部(靠近信道)。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
37. ybxiang
2014-10-15 发送消息
4.8. Cluster wide atomic counters集群范围内的计数器提供了带有名字的计数器(类似AtomicLong),可以原子性地改变。如果2个节点都累加相同的、初始值为10的计数器,那么我们将分别看到11和12。 遵循下面的步骤来创建一个带有名字的计数器:
第一步,我们添加将
接着,我们创建一个 在上面的实例代码中,我们首先创建了一个信道,然后创建了引用该信道的 CounterService不消耗它锁使用的信道中的任何消息;相反,它获取COUNTER协议的一个reference,然后直接调用其方法。其优点是 它是非侵入性的:可以基于相同的信道创建许多实例。CounterService甚至和其它使用相同机制的服务共存,比如LockService或ExecutionService (见上)。 返回的计数器实例实现了Counter接口:
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
38. ybxiang
2014-10-15 发送消息
4.8.1. Design我们在CounterService.txt中详细地描述了COUNTER的设计。 简而言之,在集群中,当前的协调者维护了 带有名字的计数器 的一个hashmap。成员发送请求 (递增,递减,等等)到协调者,协调者原子性地应用这些请求,并将响应发送回去。 这种集中处理方法的优势是:不论集群有多大,每个请求都只有固定的执行开销,也就是一个网络循环。 JGroups按照下面的方式处理ygie崩溃的或正在离开集群的协调者。协调者维护者每个计数器值一个版本号。一旦计数器的值有变化,该版本号就会被累加。对于每个修改计数器的请求,计数器的值和版本号都会被返回给请求者。请求者在本地缓存器中缓存所有计数器的值以及该值的相关版本号。 当协调者离开集群或者崩溃时,紧挨着的成员就会变成新的协调者。然后它就会启动一个协调周期,并抛弃所有的请求直到协调周期完成。协调周期 向所有成员征求它们的缓存值以及缓存值的版本号。为了降低流量,请求也携带了所有版本号。 客户端的返回值的版本比新的协调者的值的版本要高。新的协调者等待所有成员的响应或者直到超时。然后,它就会用版本比它自己的版本高的值来更新它自己的hashmap。最后,它停止抛弃请求,并发送一条重发消息给所有的客户端,以便让客户端重新发送可能处于挂起状态的请求。 我们还要考虑另外一种边界情况:如果一个客户端P更新了一个计数器,然后P和协调者都崩溃了,那么相关更新就会丢失。要想减少这种情况发生的概率,COUNTER协议可以启用 将所有计数器变化复制到一个或多个备份协调者中的功能。叫做 num_backups 的属性 定义了这样的备份协调者的数量。一旦计数器在当前的协调者中有所变化,那么也会导致备份协调者做响应更新(异步地)。如果将num_backups设置为0,表示禁止该功能。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
39. ybxiang
2014-10-15 发送消息
5. Advanced Concepts本章讨论关于如何正确地使用和配置JGroups的一些更高级的概念。 5.1. Using multiple channels当我们使用一个完整的、虚拟的、同步的协议栈的时候,性能可能不是很好,因为协议栈中出现了大量的协议。然而,对于某些应用程序而言,吞吐量比顺序更重要,比如视频/音频流 或 飞机追踪。在后面这种情况下,正确地将飞机在管制区之间进行 切换控制是非常重要的,但是,如果有一定数量(少量)的雷达追踪消息(用于判定飞机的具体位置)丢失了,这不是什么大问题。第一种消息不会非常频繁地出现 (通常,每个小时出现一定数量的这种消息),然而,第二种消息可能以10-30条每秒的速率进行发送。这种场景也适应于一个分布式白板(YBXIANG:说的是org.jgroups.demos.Draw这个演示类,它会弹出一个共享白板):代表视频或音频数据流的消息 必须被尽快地递交出去,然而代表在白板上绘制的图形的那些消息 或 代表新成员加入该共享白板的那些消息 必须按照一定的顺序递交出去。 我们可以通过使用两条单独的信道来解决这种应用程序的要求:一条信道用于发送控制类型的消息,比如分组成员关系,floor控制等等,另外一条信道用于发送数据类型的消息,比如视频/音频流 (实际上,你可以考虑使用一条信道来发送音频,使用另外一条发送视频)。控制类型的信道可以用于虚拟同步,该信道相对慢一些,但是,加强了排序和重发功能,数据信道可以使用一条简单的UDP信道,可以包含一个分割/重组协议层,但是不应该包含重传协议成 (重传丢失的数据包的话开销太大)。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
40. ybxiang
2014-10-15 发送消息
5.2. Sharing a transport between multiple channels in a JVM传输协议 (UDP, TCP) 可使用协议栈的所有资源:默认的线程池、OOB线程池以及定时器线程池。如果我们在相同的JVM中使用多条信道,那么我们可以创建一个singleton传输协议,让所有信道的协议栈(比如说4个协议栈)共享该传输协议,而不是为每条信道的协议栈单独创建一个传输协议。 如果各信道所使用的传输协议恰好相同 (比如说,4条信道都使用了UDP),那么我们就可以让多条信道共享传输协议,比如,只创建一个UDP实例。传输协议的实例只创建并启动一次;在创建第一条信道时 创建该传输协议实例,在最后一条信道被关闭时 关闭该传输协议实例。 如果我们4条信道,位于同一个JVM之内 (就像在诸如JBoss这样的应用程序服务器中的那样),那么我们就创建12个单独的线程池(每个传输协议使用3个线程池,总共4个传输协议(YBXIANG: 这里说的是不共享传输协议的情形,每条信道都拥有自己单独的传输协议))。如果这4条信道共享传输协议的话,那么线程池的个数就可以减少到3。 每条基于共享的传输协议层而创建的信道 必须加入 不同的集群。如果某条使用共享的传输协议层的信道 试图 连接到某个集群上,而另外一条信道已经通过相同的传输协议层连接到该集群上了,那么就会抛出异常。【YXIANG: 这里说的是位于相同JVM中的多条信道。如果使用共享的传输协议层的多条信道加入相同的集群,那么就乱套了,传输协议层无法知道某条消息来自/去向哪条信道!】 共享传输协议的做法需要 在"共享的传输协议层与基于该协议层的各种不同协议栈"之间 复用和解复用 消息;假设我们有3条信道 (C1连接到"cluster-1"上,C2连接到"cluster-2"上,C3连接到"cluster-3上"),它们基于共享的传输协议层发送消息,JGroups使用各信道所连接的集群名字将消息复用到共享的传输协议层上:当C1发送一条消息的时,就为该消息添加一个包含了集群名字("cluster-1")信息的包头。 当某条带有"cluster-1"包头的消息被共享的传输协议层接收到时,该包头就会被用于解复用该消息,然后将其派发到正确的信道上 (本例中,是C1) 进行处理。 多条信道如何共享同一个传输协议层: 
这里,我们可以看见,4条信道使用了2个传输协议。注意,前3条共享传输协议层"tp_one"的信道,在这个共享传输协议层之上的其它协议都是相同的。这不是必须的;在"tp_one"之上的、分别属于3条信道的各个协议可以是不同的,只要使用该共享传输协议成的所有应用程序 对 传输协议的配置要求 是一样的就可以了。 传输协议"tp_two"供右边的应用程序使用。 请注意,共享传输协议的信道的物理地址 对于所有连接上的信道而言,是相同的,因此共享第一个传输协议的所有应用程序具有相同的物理地址 要想使用共享的传输协议,我们只需要在传输协议的配置中添加一个"singleton_name"属性既可。所有使用相同singleton名字的信道都会被共享 现在,所有使用该配置的信道,都会共享传输协议"tp_one"。在右边的信道使用了不同的配置,其singleton_name是"tp_two"。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
41. ybxiang
2014-10-15 发送消息
5.3. Transport protocols传输协议指的是在协议栈底层的协议,它负责从网络上收发消息。JGroups支持很多传输协议。我们将在下面的小节中讨论这些协议。 一个使用UDP的经典协议栈配置如下: 简而言之,这些协议包括:
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
42. ybxiang
2014-10-15 发送消息
5.3.1. Message bundling在发送许多很小的消息时,消息捆绑功能就很有用;该功能会将这些小消息进行排队,直到这些小消息能够汇聚成具有一定尺寸的消息,或者汇聚等待超时。之后,排队的小消息就会被组装成一个大一点的消息,然后就会将这个大消息发送出去。在接收端,这个大消息被拆卸,然后将这些小消息向协议栈的上方发送。 在发送许多小消息的时候,消息的负载和消息的包头的比率可能很小;假设我们发送了一个"hello"字符串,负载是7个字节,然而地址和包头(取决于协议栈的配置)可能是30个字节。然而,如果我们将(假设)100条消息捆绑在一起,那么这条大消息的负载就是700字节,而包头依旧是30字节。这样,通过一条大的消息,而不是许多小的消息,我们就能够在网络上发送更多的有效数据。 消息捆绑在概念上类似TCP的零窗口(Nagling)算法. 一个实例配置如下: 这里,捆绑功能被启用了 (默认的)。最大汇聚尺寸为 64'000 字节,我们最多等待 30毫秒。如果在T0时刻,我们准备将总大小为2'000字节的10条小消息捆绑发送出去,但是接着不会发送更多消息,那么JGroups就会等待直到30毫秒之后超时,之后就将这些小消息打包成一条大消息M,并将M发送出去。如果我们要发送1000条消息,每条消息为100字节,那么在达到64'000 字节之后 (大约64条消息之后),我们将吧这条大消息发送出去,这可能只需要3毫秒。
Message bundling and performance尽管消息捆绑功能在异步地发送许多小消息时性能很好,不过在触发同步RPC时性能可能就会很差了:比如,我们正在通过RpcDispatcher (参见RpcDispatcher)在集群中触发10个同步的(阻塞式的) RPCs,由每个调用的所有序列化参数构成的负载小于64K。 由于RPC是阻塞式的,我们将会等待该调用返回之后才调用下一个RPC。 对于每个RPC而言,其请求都会等满30毫秒的超时时间,同样,每个响应也会等满30毫秒的超时时间,这样每次调用总共要消耗60毫米昂。因此10个阻塞式RPCs 总计会消耗600毫秒! 很明显,这是无法接受的。然而,这里有个简单的解决方案:我们可以使用消息标志位(参见 Tagging messages with flags)来覆盖在传输协议中设置的默认绑定行为:
对于10个阻塞式的RPCs而言,使用 除了设置DONT_BUNDLE标志位,还有一种方法,那就是使用 futures 来触发这10个阻塞式RPCs: 这里,我们使用了 callRemoteMethodsWithFuture(),它会立即返回(尽管该调用是阻塞式的!) 一个 future。在触发这10次调用之后,我们才从它们的futures中获取相关调用结果。 和上面的几个毫秒比较起来,这段代码大约需要 60 毫秒 (30毫秒用于请求,30毫秒云南哦关于响应),但这依旧比不使用DONT_BUNDLE标志位时消耗的600毫秒好很多。请注意,如果这10个请求的汇聚尺寸超过了
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
43. ybxiang
2014-10-15 发送消息
5.3.2. UDPUDP使用了IP多播来将消息发送给集群中的所有成员,使用UDP数据报处理单播消息(发送给单个成员)。UDP启动时,它打开一个单播和多播socket:单播socket被用于收/发单播消息,而多播socket被用于收/发多播消息。信道的物理地址是 单播socket的UDP地址和端口号。 Using UDP and plain IP multicasting使用UDP作为传输协议的协议栈,通常被用于集群中,其成员运行在相同的host上,或者分布在LAN中。请注意,在不同的子网中运行多个协议栈实例之前,管理员应该确保IP多播包允许跨越这些子网。通常会出现IP多播包无法跨越子网的情况。如何运行一个测试程序,来判定各集群成员是否能够通过IP多播进行交互,请参见 It doesn’t work ! 这一节。如果还是不行,那么该协议栈就不用使用UDP的IP多播作为其传输协议。在这种情况下,协议栈必须使用非多播的UDP,或者使用不同的传输协议,比如TCP。 Using UDP without IP multicasting使用UDP和PING作为底层协议的协议栈 默认使用IP多播 来将消息发送到所有成员(UDP) 以及发现初始成员 (PING)。然而,如果不能使用IP多播,我们可以配置 UDP协议和PING协议,让它们发送多条单播消息,而不是一条多播消息。
要想配置UDP,让它通过多条单播消息来发送 一条分组消息,而不是使用IP多播来发送,那么必须将 ip_mcast 属性设置为 false。 如果我们禁用了ip_mcast,那么我们改变发现协议(PING)。因为PING协议要求在该传输协议中启用IP多播,我们不能使用它。替代品有:TCPPING (成员地址的静态列表)、TCPGOSSIP (外部查询服务)、FILE_PING (共享的目录)、BPING (使用广播) 或者 JDBC_PING (使用共享的数据库)。 关于如何配置各种发现协议的细节,请参见Initial membership discovery。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
44. ybxiang
2014-10-15 发送消息
5.3.3. TCP在不能使用IP多播的情况下,TCP是UDP的一个替代品。当通过WAN操作时,就是这样的情况,在WAN中,路由器可能会抛弃IP多播包。通常UDP在LAN中作为传输协议,而TCP用于集群分布在多个WANs中的场合。 一个基于TCP的经典协议栈的配置属性看起来如下 (为了简便起见,我们修改过):
当使用TCP时,发送给所有集群成员的消息会被当作多条单播消息发送出去 (每个成员对应一条消息)。由于不能使用IP多播来发现初始成员,必须使用其它机制来发现初始成员关系。这里有一些可选机制(关于所有发现协议的讨论,请参见 Initial membership discovery):
下面谅解展示如何将TCP和TCPPING/TCPGOSSIP联合使用: Using TCP and TCPPING一个使用了TCP和TCPPING的协议栈看起来如下 (省略了其它协议): TCPPING背后的理念是:我们选中的某些集群成员 承担着 提供初始成员关系的已知主机角色。在本例中,HostA和HostB就是被选定的成员,TCPPING通过这两个成员来查询初始的成员关系。在TCP中的属性"bind_port"意味着每个成员都应该试图为其自己指定端口7800。如果不能使用该端口,则试用下一个端口,以此类推,直到它找到一个未被试用的端口为止。 TCPPING试图跟HostA和HostB联系,从端口 Using TCP and TCPGOSSIPTCPGOSSIP 使用一个或多个GossipRouters来:(1) 注册该成员自己 (2) 获取已经注册过的集群成员的信息。配置看起来如下: initial_hosts属性的值是一个以逗号分隔的GossipRouter列表。在这个例子中,有2个GossipRouters,位于HostA和HostB上,端口是 一个成员总是会将其自己注册到所有列举在initial_hosts属性中的GossipRouters中,但是从第一个可访问的GossipRouter获取信息。如果某个无法访问某个GossipRouter,那么就会将其标识为出故障的GossipRouter,并从该列表中删除。然后启动一个任务,周期性地试图重连到出故障的GossipRouter。如果重连成功,那么这个故障的GossipRouter就会被标识为无故障的,并被重新插入到该列表中。 使用多个GossipRouters的好处是,只要有至少一个GossipRouter在运行着,那么新的成员总是能够获取到初始成员关系信息。 请注意,在任何成员启动之前,我们应该首先启动GossipRouter。 YBXIANG提示:GossipRouter应该是和JGroups进程无关的一个Gossip路由器,专门负责存储集群的共享信息。为了防止GossipRouter成为单点故障,因此应该使用多个GossipRouter。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
45. ybxiang
2014-10-15 发送消息
5.3.4. TUNNEL(透传:集群成员通过隧道服务器进行中转透传)防火墙通常置于内网连接到互联网之前。防火墙通过筛选进入内网的数据流并拒绝外部机器试图连接防火墙之内的主机,从而保护了本地网络免遭外部攻击。大多数防火墙系统,允许位于防火墙之内的主机连接到防火墙之外的主机上 (输出的数据流),然而大多数情况下会彻底禁止输入的数据流。【YBXIANG:有时候,防火墙只允许外部主机连接到内部主机的特殊端口上,比如80端口,以获取内部主机对外提供的服务。有时候,防火墙彻底禁止外部主机连接到内部主机上,也就是说禁止内部主机作为SocketServer;只允许内部主机连接防火墙之外的SocketServer,内部主机和外部主机之间建立起一条Socket通道,它们利用Socket的全双工特性进行交互。这就是TUNNEL协议作为中转透传隧道(SocketServer)的应用的场景。】 隧道 是主机协议,该协议封装了其它协议,它会在某一端复用其它协议,然后在另外一端解复用这些协议。任何协议 都可以通过 一个隧道协议 进行 透传。 防火墙的大多数约束性设置 通常是 禁用 所有 流入的数据流,只启用一些选定的端口供 输出数据流(YBXIANG: 禁止外部主机连接进来,只准内部主机连接出去)。在下面的解决方案中,我们假设防火墙启用了一个TCP端口,以供内部主机向外连接到GossipRouter上。 JGroups有一种允许程序员透传防火墙的机制。该解决方案涉及到一个GossipRouter,它位于防火墙之外,因此其它成员(可能位于防火墙之内)可以访问它。 该解决方案工作方式如下。位于防火墙之内的某条信道 必须使用 TUNNEL协议,而不是UDP或TCP作为传输协议。推荐的发现协议为PING协议。这里有个配置: TUNNEL协议使用了一个运行在HostA上、端口为12001的GossipRouter (位于防火墙之外)来进行透传。请注意,如果使用了TUNNEL协议,就不推荐使用TCPGOSSIP提供发现服务,请使用PING协议。TUNNEL协议可以接受一个或多个提供透传功能的GossipRouters;可以在gossip_router_hosts属性中,以“host[port]”格式列举这些GossipRouters,并用逗号隔开。 TUNNEL协议会建立一条TCP连接到GossipRouter进程(位于防火墙之外),GossipRouter接受来自各成员的消息,并将这些消息传递给其它成员。该连接由位于防火墙之内的主机发起,只要该信道连接在一个集群上,该连接就会一直存在。GossipRouter将会使用相同的连接将incoming消息发送回这条发起连接的信道。 这么做是完全合法的,因为TCP连接是全双工的。请注意,如果GossipRouter试图建立它自己的TCP连接到防火墙之内的信道上,就会失败。不过,重用由信道创建的、现成的TCP连接就够了。 请注意,必须为TUNNEL协议设置GossipRouter进程所在的hostname以及端口号。这个例子假设某个GossipRouter运行在HostA上的 任何时候,当信道发出一条消息时,TUNNEL协议就会将该消息转发给GossipRouter,GossipRouter负责将其派发给其接收者:如果消息的目标域为null (发送到分组中的所有成员),那么GossipRouter就会查找属于该分组的所有成员,然后通过这些成员在连接该GossipRouter时创建的那些TCP连接,将该消息转发给这些成员。如果该目标地址是一个有效的成员地址,那么GossipRouter就会查找该成员的TCP连接,然后将该消息转发给它。
单个GossipRouter不是单点故障。在设置多个gossip routers的时候,这些routers不会相互通信,每个信道简单地与多条可用的routers相连接,这样就避免了单点故障。在一个或多个routers宕机的情况下,集群成员依旧可以通过剩余的可用的router实例进行交互,只要还有这样的router实例既可。 对于每个发送调用而言,信道会查询连接routers的、可用的连接列表,利用每条连接来发送消息,直到发送成功为止。如果任何连接都不能将该消息发送出去,那么就会出现异常。如何选择连接的默认策略是:随机性的选择。不过,我们提供了一个插件解开,以供使用其它策略。 GossipRouter配置是静态的,在信道的生命周期内是无法更新的。必须通过信道的配置文件 来提供 可用的routers列表。 要想让JGroups透传一个防火墙,需要采取下面的步骤:
常规设置参见Tunneling a firewall:
Figure 4. Tunneling a firewall
首先,在主机B上创建了一个GossipRouter进程。请注意,主机B应该位于防火墙之外,位于相同分组中的所有信道 应该使用相同的GossipRouter进程。当在主机A上创建一条信道时,该信道的TCPGOSSIP协议层就会将其地址注册到GossipRouter中,然后获取初始成员关系信息 (假设初始成员为C)。现在,主机A就建立了一条连接到该GossipRouter的TCP连接;该连接将一直存在,直到A崩溃或者主动地离开该集群。当A多播一条消息到集群时,GossipRouter就会查询所有的集群成员 (在本例中,为A和C),然后利用这些成员的TCP连接将该消息转发给所有的成员。在本例中,A会收到由它自己发出的那条多播消息的一个拷贝,另外一份拷贝会被发送给C。 这种设计允许,比如Java applets(它们只被允许连接回提供下载它们的主机),使用JGroups:HTTP server位于主机B上,GossipRouter daemon也运行在该主机上。一个applet被下载到A或者C上,该applet被允许创建一条连接到B的TCP连接。此外,位于防火墙之内的多个应用程序可以相互交互并形成一个集群。 然而,这种方案有好几个缺陷:首先,必须维护一条TCP连接,该连接持续存在,这会耗尽其主机系统的资源(比如GossipRouter的资源),从而导致扩展性问题,此外,如果有几个信道位于防火墙之内,那么该方案就不妥了,绝大多数信道实际上可以使用IP多播进行通信,最后,在一个防火墙内的2个端口上允许outgoing数据流通过并不总是可能的,比如说,当防火墙不属于用户时。 YBXIANG:我们通常不会在相同的主机上创建不同的GossipRouter供位于相同集群中的成员访问,这么做纯粹是浪费资源,如法避免GossipRouter主机宕机这种单点故障。因此,上图有点问题,第一个GossipRouter应该位于B上,第二个GossipRouter应该位于D上,这样才有意义。本人猜测,作者的本意是,这2个位于相同主机上的GossipRouter是供不同的集群使用的。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
46. ybxiang
2014-10-15 发送消息
5.4. The concurrent stack并发协议栈 (在2.5中引入)对前期版本做了大量的改进, 前期版本有些缺陷:
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
47. ybxiang
2014-10-15 发送消息
5.4.1. Overview并发协议栈的架构显示在The concurrent stack中。对传输协议(TP, 其子类包括 UDP, TCP and TCP_NIO)做了彻底的修改。因此,用户要想配置这个并发协议栈,就必须在XML文件中修改 比如UDP的配置。
Figure 5. The concurrent stack
这个并发协议栈包含了2个线程池(java.util.concurrent.Executor):带外(OOB)线程池和常规线程池。数据报文由 多播或者单播接收线程(UDP) 接收,或者由ConnectionTable (TCP, TCP_NIO)接收。被表示为OOB的报文(使用Message.setFlag(Message.OOB)来打标记) 被派发给OOB线程池,其它报文被派发给常规线程池。 如果某个线程池被禁掉了,那么我们就是Caller所在的线程(也就是单播或多播接收器线程 或者 ConnectionTable)来将消息发送给上面的协议栈,然后向上传入应用程序。否则,消息就会被来自线程池的线程处理,这些线程会将消息发送给上面的协议栈。当所有的当前线程处于繁忙状态时,JGroups就会创建另外一个线程来处理消息,直到达到定义的最大线程数。此外,还可以选择将报文放入队列进行排队,直到有空闲线程来处理。 使用线程池的一个要点是,接收者线程应该只负责接收报文并将这些报文转发给线程池处理,因为对消息进行反序列化并做相关处理 比单纯接收消息要慢一些,前者(对消息进行反序列化并做相关处理)可以从并行处理中获益。 Configuration请注意,这只是初步的定义,名字或属性可能会有所改变。 我们正在考虑:通过编程方式,将线程池暴露出来,这意味着开发者能够通过编程的方式来配置线程池,比如说,使用TP.setOOBThreadPool(Executor executor)这样的代码进行配置。 下面是新配置的一个例子: 这2个线程池的属性分别以 thread_pool和oob_thread_pool 开头。 相关属性列举在下面。大致和JDK5中的java.util.concurrent.ThreadPoolExecutor选项相对应。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
48. ybxiang
2014-10-15 发送消息
5.4.2. Elimination of up and down threads通过消除每个协议层对应的2个队列和2个线程,我们有效地减少了处理消息的线程数,因此减少了上下文切换时的开销。Channel.send()的语义也更加清晰明了:现在,所有消息都从调用者线程开始,沿着协议栈向下发送,只有当消息已经被发送到网络上之后,send()调用才返回。此外,如果消息依旧没有被放入一个重发缓存的话,异常将会被传递回该调用者。否则,JGroups就会简单地打印错误消息的日志,而不是继续重发该消息。因此,如果调用者得到了一个异常,调用者就应该重发该消息。 在接收端,一条消息被一个线程池处理,要么是常规线程池,要么是OOB线程池。这两个线程池都可以被完全地去除,这样我们就能节省更多的线程,从而进一步地减小上下文切换开销。要点是:现在,开发者需要能够几乎完全地控制线程行为。 5.4.3. Concurrent message delivery直到2.5版,所有消息都是由一个单独的线程处理,即使这些消息由不同的发送者发送。比如,如果A发送了消息1,2 和 3,而B发送了消息34 和 45,如果A的消息已经被全部收到了,那么B的消息 34 和 35 很可能在A的1~3消息被处理完毕之后,才被处理! 现在,我们可以并行地处理来自不同发送者的消息,比如来自A的消息1,2和3可以被线程池中的某个线程处理,来自B的消息34和35可以由另外一个不同的线程处理。 这样,如果一个集群有N个节点,每个节点都正在发送消息,而且我们为线程池配置了至少N个线程,那么我们的速度就快了将近N倍。有一个实际的单元测试(ConcurrentStackTest.java)来展示该并发协议栈的性能。
链接
| 主题↑
| 回复↓
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
49. ybxiang
2014-10-15 发送消息
5.4.4. Scopes: concurrent message delivery for messages from the same sender
在前面的段落中,我们描述了并发协议栈如何并发地递交来自不同发送者的消息。但是来自相同发送者P的所有消息(非OOB消息)会按照P发送它们的顺序被递交出去。然而,这对于某些应用程序而言并不足够好。 让我们分析一个应用程序,它会复制HTTP sessions。如果我们有 sessions X, Y和Z,那么对这些sessions的更新信息就会被按照更新它们时的顺序递交出去,比如:X1, X2, X3, Y1, Z1, Z2, Z3, Y2, Y3, X4。这意味着 更新信息Y1 必须等到 更新信息X1-3 被交出出去之后。如果这些更新需要耗费一些时间,比如说,花费在获取锁或反序列化上的时间,那么所有紧接着的消息就会被延迟, 延迟时间为 它们前面的那些消息 按顺序交付时 所消耗的时间总和。 然而,在大多数情况下,不同的web session的更新信息应该是完全不相关的,因此,应该被并发地递交出去。比如,对会话X的修改不应该对会话Y有任何影响。因此,对X, Y和Z的更新信息 都能够被 并发地递交出去。 这个问题的一个解决方案是带外(OOB)消息 (参见下一个段)。然而,OOB消息不能确保顺序,因此,更新信息X1-3 可能会被按照 X1, X3, X2 这个顺序递交出去。如果这不是我们想要的,而是想要 与某个特定web session会话的所有消息都被并发地递交出去,然后在这个特定session之内排序,那么我们可以求助于scoped messages。 Scoped messages只能用于常规消息(非OOB消息),在scopes之间进行并发递交,然后在给定的scope之内进行排序。比如,我们将上面的sessions用作(比如jsessionid)作为scopes,那么递交顺序可能如下:(-> 表示顺序的,|| 表示并行的):
这意味着,X的所有更新信息 与 Y的所有更新信息、Z的所有更新信息 被并行地递交出去。然而,在一个特定的SCOPE之内,更新信息 被按照它们被更新的顺序 递交出去。因此,X1在X2之前被递交出去,X2在X3之前被递交出去,依次类推。 回到上面的例子,这次我们使用scoped messages,更新信息Y1 不必 等到更新信息X1-3递交完毕,可以立即处理它。 要想设置一条消息的scope,请使用Message.setScope(short)方法。 Scopes是在 叫做SCOPE的、单独的协议中实现的。该协议必须被放置在诸如UNICAST、NAKACK(或处理这个问题的SEQUENCER)之类的排序协议的上面某个地方。
5.4.5. Out-of-band messagesOOB消息完全忽略协议栈可能带有的任何顺序约束。任何被标记为OOB的消息,都将会被OOB线程池处理。当我们不想要某条消息的处理 必须 等到所有来自相同发送者的其它消息被处理之后,才被处理,比如心跳这种情况:如果发送者P发送了5条消息,然后发送了对来自其它节点的某个心跳请求的一个响应,那么处理P的5条消息所消耗的时间可能比心跳超时时间长一些,因此,P就会被错误地作为嫌疑对象!然而,如果我们将心跳响应标记为OOB,那么心跳响应就会被OOB线程池处理,因此 它和在它前面发送的5条消息是并行的,因此不再会导致错误的嫌疑。【YBXIANG:这里的嫌疑指的是被列为已经崩溃的或正在离开集群的嫌疑对象】 两个单元测试 UNICAST_OOB_Test 和 NAKACK_OOB_Test 展示了OOB消息如何影响单播和多播消息的排序。 |