Mysql优化之问题定位
Mysql优化之问题定位
先扯淡下,很久没有来csdn写博客了, 最近在学燕18的mysql优化,并且这位老师讲的高达上还接地气, 今天刚好有空可以来总结这段时间学到的东西
先上一张流程图(这张图引自燕18的教程)
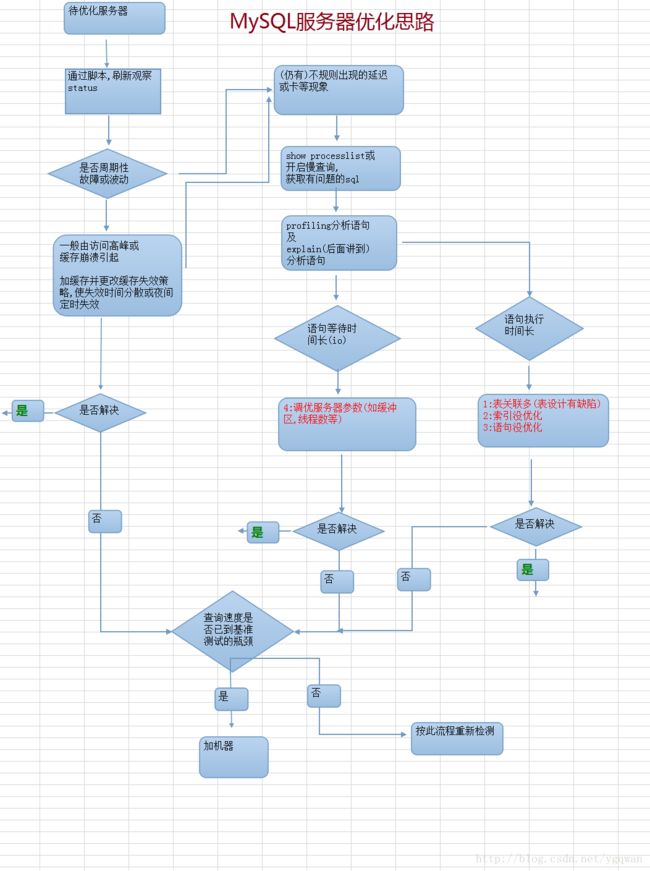
当遇到一台db服务器有问题的时候, 首先不是去看代码哪里有问题, 想sql语句是否写,表的结构是否合理之类的问题;而是需要从宏观的角度去看哪些地方有问题
第一步找出服务器问题所在, 是否是硬件有瓶颈
如果一台服务器硬件本身就不好, 只能承受100M的io读写, 如果你非要它提供的io达到200M, 那么就算你怎么优化也搞不定是吧, 那么我们首先需要基准测试
需要安装sysbench,它提供了cpu, Io, memory, mysql等性能的测试, ;
1.cpu测试
sysbench --test=cpu --cpu-max-prime=2000000 run
2.io测试
sysbench --test=fileio --num-threads=16 --file-total-size=3G --file-test-mode=rndrw prepare sysbench --test=fileio --num-threads=16 --file-total-size=3G --file-test-mode=rndrw run sysbench --test=fileio --num-threads=16 --file-total-size=3G --file-test-mode=rndrw cleanup
这里的Status状态可能情况比较多, 不过我们主要是关注如下几个状态:3.OLTP测试
sysbench --test=oltp --mysql-table-engine=myisam --oltp-table-size=1000000 --mysql-socket=/tmp/mysql.sock --mysql-user=test --mysql-host=localhost --mysql-password=test prepare通过这些测试之后差不过也能知道自己服务器的能力了, 如果发现服务器的性能不错, 但是依然不能满足用户的需求, 那么就只能是软件方面的问题了, 就需要定位到底是哪一块有问题第二步, 观察mysql在某段时间的连接状态, 处理状态
如果硬件问题不大, 那么我们就需要观察mysql的状态了, 一般这个状态不是一时半会儿能搞定的, 都是需要写个脚本在后台记录mysql在某一个周期的压力值记录, 比如是一天, 一周为一个周期;查看mysql的状态命令是show status;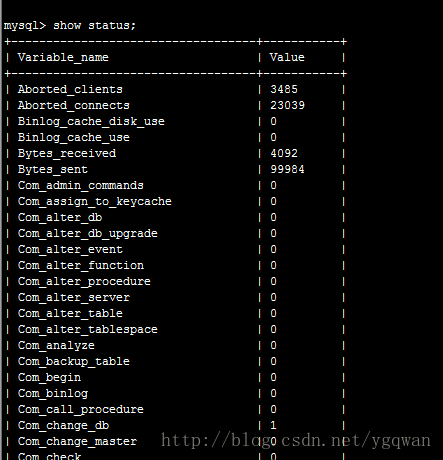
![]() 这个命令返回好几百行的东西, 而我们只需要关注3行
这个命令返回好几百行的东西, 而我们只需要关注3行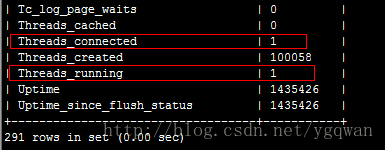 1.Queries, 当前已经发生过的查询(可以用两个时间段的查询数量相减得到时间段内的查询数)
1.Queries, 当前已经发生过的查询(可以用两个时间段的查询数量相减得到时间段内的查询数)![]() 2.Threads_connected ,当前有多少个连接连上mysql
2.Threads_connected ,当前有多少个连接连上mysql![]() 3. Threads_running, 当前有几个线程正在运行
3. Threads_running, 当前有几个线程正在运行![]() 通常是Threads_connected >= Threads_running, 因为连上mysql也不一定要工作, 可能阻塞, 挂起之类的
通常是Threads_connected >= Threads_running, 因为连上mysql也不一定要工作, 可能阻塞, 挂起之类的获取结果
1.我们写个脚本
![]() 每隔一秒去读取这三个数追加到mysql.status文件里面2. 用ab工具模拟访问, 用50个并发, 发送20000个请求(这个页面的每一次请求会多次访问mysql), 这样就能使上面那个脚本得到结果了ab -c 50 -n 2000 http://59.69.128.203/JudgeOnline/nyistoj/index.php/Problem/index
每隔一秒去读取这三个数追加到mysql.status文件里面2. 用ab工具模拟访问, 用50个并发, 发送20000个请求(这个页面的每一次请求会多次访问mysql), 这样就能使上面那个脚本得到结果了ab -c 50 -n 2000 http://59.69.128.203/JudgeOnline/nyistoj/index.php/Problem/index![]()
![]() 我们来查看这个mysql.status文件的内容
我们来查看这个mysql.status文件的内容![]() 我们用上一行的第一个值减去下一行的第一个值就可以得到每一秒的访问mysql数量,差不多是1000+, 也可以看出基本上是有50个连接的, 平均用两个线程在处理请求;可以再次写一个脚本做一下处理
我们用上一行的第一个值减去下一行的第一个值就可以得到每一秒的访问mysql数量,差不多是1000+, 也可以看出基本上是有50个连接的, 平均用两个线程在处理请求;可以再次写一个脚本做一下处理
![]() 这样就得到每一秒的处理数量, 1000多一点儿, 貌似不咋好的感觉
这样就得到每一秒的处理数量, 1000多一点儿, 貌似不咋好的感觉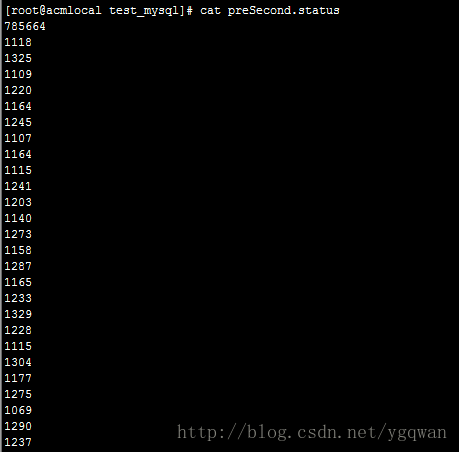
结果分析
1. 访问mysql的频率很稳定(如下图), 那就从mysql的其它部分优化, 比如表的结构, sql语句的优化, mysql的配置, 引擎的选择, 索引的优化等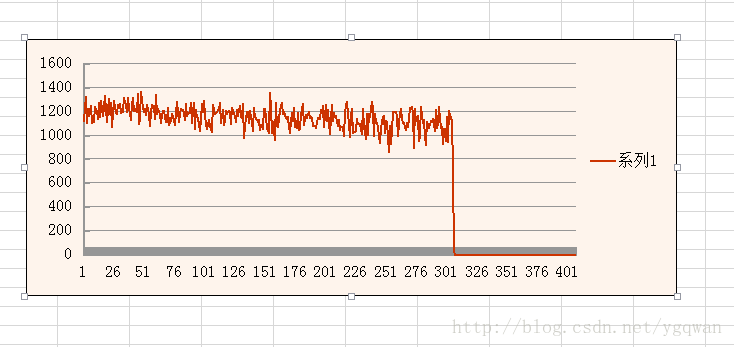
![]() 2.mysql的访问频率呈周期性的变化(如下图), 那么就是从峰值上优化;比如memcatch是否都是周期性失效, 那么就可以用随机方式让失效地更加均匀, 或者是让他在晚上3点左右失效, 这个时候的访问量不大, 到了第二天时memcatch的缓冲也基本上建立好了;或者是从业务角度优化, 比如12306的放票, 可以分省分时间段分批放票, 这样就避免了全国各地大家集体抢票带来的超高峰值; 也可以在高峰期的时候开启慢查询, processlist等工具分析到具体的sql语句;
2.mysql的访问频率呈周期性的变化(如下图), 那么就是从峰值上优化;比如memcatch是否都是周期性失效, 那么就可以用随机方式让失效地更加均匀, 或者是让他在晚上3点左右失效, 这个时候的访问量不大, 到了第二天时memcatch的缓冲也基本上建立好了;或者是从业务角度优化, 比如12306的放票, 可以分省分时间段分批放票, 这样就避免了全国各地大家集体抢票带来的超高峰值; 也可以在高峰期的时候开启慢查询, processlist等工具分析到具体的sql语句;三. 查看mysql进程的状态
如果需要知道mysql这个进程对处理sql语句的整体情况, 那么我们需要用到show processlist 这个工具,这个工具主要是能够记录下来每一条sql执行的过程;我们写一个脚本抓取status, 然后整体看看我们的mysql进程花的时间基本上都是在干什么;show processlist\G![]()
1. Create tmp table; 创建临时表, 比如用了右连接就会新建一张临时表
2. Sending Data ; 发送数据, 比如limit 1, 1000; 那么这样就会传送大量的数据而花费时间, 可以limit小一点儿
3. SortIng for Group; 正在为分组排序, 这个时候就优化一般是借助复合索引
4. Copying to tmp table on desk; 正在将内存的表拷贝的硬盘, 主要是表太大, 比如join一下就产生很大的表只能放硬盘了, 避免join
5. Locked; 锁住数据, 事务性方面优化, 能不用事务就不用
6. Converting HEAP to MyISAM; 查询的结果太大, 正在想硬盘存结果; 优化就是尽量一次稍差点儿数据, 比如新闻列表的读取一次少读点儿, 读者很少一次性读到几百条以后;
那么我们写一个脚本抓取这些status:
然后处理下mysql.process;
就能得到如下结果了:
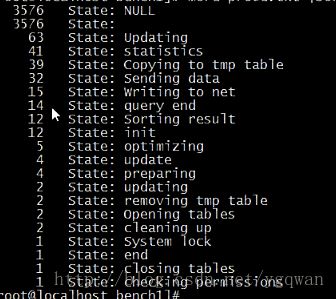
从图中可以看出很多次都是花在了Copying to tmp table ,Sending data, Sort result 的次数不少, 可以大致知道是业务逻辑导致需要取出的数据比较多, 可以变化业务或者做缓冲服务器挡在mysql前面;
看看 Copying to tmp table;
首先打开profiles;
然后执行sql就会被记录了,
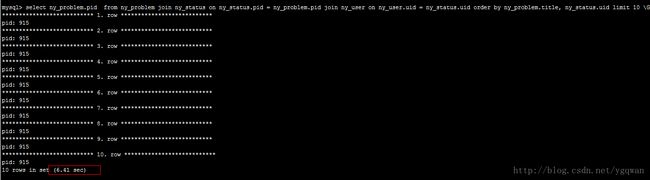 再用show profiles得到刚才语句的id;
再用show profiles得到刚才语句的id;
就能知道该语句的id是27, 花了6秒多,查看id为26的具体内容:
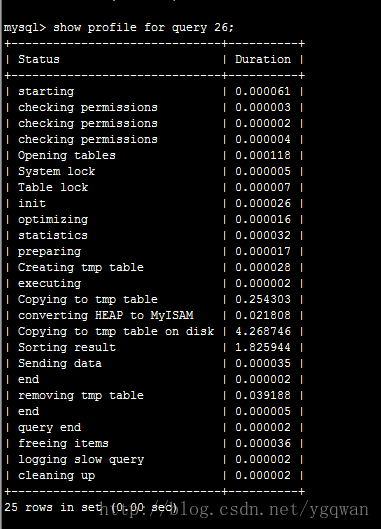
现在我们知道了这条sql花时间在拷贝到硬盘与排序, 因为我们有了三次join, 而这些join的同时用了title排序, 导致无法索引覆盖,从而需要回行到硬盘中的数据这样就导致了一张非常大的表而无法放入到内存中, 只能放到硬盘了;
然后再有针对性的优化就行了这条sql;
总结:
经过上面的几步, 我们已经能逐步能能够定位我们的服务器哪个地方出了问题,是服务器本身不够强, 或者是周期性的问题, 或者就是自己的代码或者表结构不够好, 或者是业务逻辑之类的问题, 后面我们主要是针对具体的问题优化, 这个是下一篇的内容了