oracle层次化查询,你可能不知道的地方
层次化查询
疑问
在connect by prior语句后加and用来从生成树中删除整个分支。
但是当删除的分支为根节点时,好像并不起作用。
select level,empno,mgr,lpad(' ',2*level-1)||ename
from emp
start with mgr is null
connect by prior empno=mgr and empno != 7839 ;
--这里empno=7399的结点正是start with指示的结点,按照逻辑应该结果不包含任何行,但是这里显示的结果就好像和没有and子句的结果一样,and后面的东西并没有起作用!--
结果
LEVEL EMPNO MGR LPAD('',2*LEVEL-1)||ENAME
---------- ----- ----- ------------------------
1 7839 KING
2 7566 7839 JONES
3 7788 7566 SCOTT
4 7876 7788 ADAMS
3 7902 7566 FORD
4 7369 7902 SMITH
2 7698 7839 BLAKE
3 7499 7698 ALLEN
3 7521 7698 WARD
3 7654 7698 MARTIN
3 7844 7698 TURNER
3 7900 7698 JAMES
2 7782 7839 CLARK
3 7934 7782 MILLER
14 rows selected
现在删除empno为7566的结点,其子结点都被删除了如下:
select level,empno,mgr,lpad(' ',2*level-1)||ename res from emp
start with mgr is null
connect by prior empno=mgr and empno != 7566
1 7839 KING
2 7698 7839 BLAKE
3 7499 7698 ALLEN
3 7521 7698 WARD
3 7654 7698 MARTIN
3 7844 7698 TURNER
3 7900 7698 JAMES
2 7782 7839 CLARK
3 7934 7782 MILLER
9 rows selected.
同样的逻辑,不同的结果?
其执行顺序到底是什么??
通过实验来进行探寻
-----------------------------------------------------------
通过层次化查询的结果来看,数据的组织方式为数生成树先序遍历得到的输出。这毋庸置疑
select level,empno,mgr,lpad(' ',2*level-1)||ename
from emp
start with mgr is null
connect by prior empno=mgr and empno != 7566;
对于这个结果,如果是首先生成一棵完整的树,然后再剪枝,这是得不偿失的,因为剪枝过程,要把结点本身和其子节点全部删除,本质上和构造一棵树的过程差不多,我们得到
一个结果,要经过两次生成树的过程这是oracle的处理引擎所不可容许的。特别当剪掉的分支规模和整个树规模相当时,所以,我感觉层次化查询肯定是先处理and子句的部分,把
不符合and子句的结点删除,然后再构造结果集,这样被and子句删除的结点,因为其父子关系断层,而其子节点和本身不可能在结果集中出现。
执行过程肯定也是深度优先进行处理的,但是其执行过程到底是什么呢?
思考:
通过查看课本,我发现了一个细节,课本上说用start with 和 connect by来构造层次化查询,并没有指定prior
那prior这个关键字在层次化查询中是不是必要的呢??
然后写了一个如下的sql语句
实验一
select level,empno,mgr,lpad(' ',2*level-1)||ename
from emp
start with mgr is null
connect by empno=mgr;
这种情况下,只有一个输出结果
LEVEL EMPNO MGR LPAD('',2*LEVEL-1)||ENAME
---------- ----- ----- ------------------------------
1 7839 KING
可以输出结果,先不说输出的结果是什么意义(事实上做这个实验的时候真不知道这个查询表达的是什么意思,但后来我明白了),但至少说明语法上允许不存在prior的情况,那prior有什么用呢?
思考:
我猜测prior用来代表父节点(根据层次化查询结果我得到这样的一个理解),因为oracle层次化查询用的是深度优先,prior所指的值会不会是当前扩展的根节点呢?
假设prior代指根节点,那么可以是prior在connect by子句的任意地方,而不仅仅在connect by 之后,基于此,我做了如下的实验
实验二
select level,empno,mgr,lpad(' ',2*level-1)||ename
from emp
start with empno=7900
connect by empno=prior mgr;//表明子节点的员工号等于父节点的管理号
根据以上假设,这样的结果应该是从7900的结点一直回溯的根节点,执行后得到如下结果
LEVEL EMPNO MGR LPAD('',2*LEVEL-1)||ENAME
---------- ----- ----- --------------------------------------------------------------------------------
1 7900 7698 JAMES
2 7698 7839 BLAKE
3 7839 KING
完全正确!
可以用这样的方法来逆向搜索!
思考:
根据以上两个实验,得出了两个结论
1,prior关键字可有可无
2,prior确实是指向当前扩展节点,也就是父节点
猜测:
我的脑海偶尔闪过一个想法,connect by子句很可能向oracle引擎返回一个布尔值。
于是做了如下实验
实验三
select level,empno,mgr,lpad(' ',2*level-1)||ename
from emp
start with mgr is null
connect by 1=1;
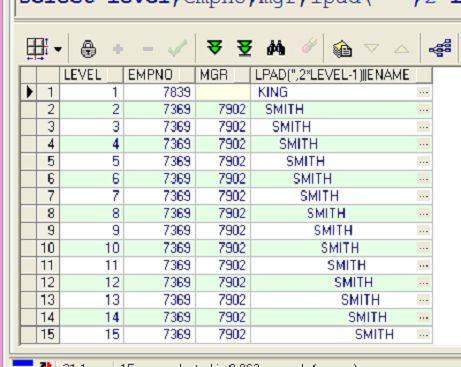
程序竟然出现了无穷递归,从level的值可有看出,oracle搜索引擎进入了死循环!
如果connect by向引擎返回布尔值的话,这样的结果是完全可以理解的!
猜测:
通过以上的思索和实验我得出了一下的一些猜测
1,层次化查询一定是深度优先的
2,start with指定了树的根节点,这个根节点肯定在结果集中存在
3,connect by 返回一个布尔值,布尔值为真的数据行成为当前扩展节点子节点
4,prior指向当前扩展节点
5,and后面是一个表达式,其结果也是布尔值,connect by 和and之间的布尔表达式表明父子的链接关系,and后面的布尔表达式表示筛选条件,多个表达式做逻辑'与'&运算共同决定一个节点是否被扩展(这也解决了我一个疑惑,为什么用一个莫名其妙的AND来限制查询结果,而不是其他的更有意义的一些关键字)。
6, where 子句只在生成的结果集中去掉不和要求的节点,并不会删除其关联分支
证明我的猜测
为了证明我的猜测,我自己写了一个层次化查询的引擎来做一些验证,而引擎的编写原理用到了我以上的六个猜测
下面源码
实验四
//一个递归的函数用来模拟查询
create or replace procedure Treequery(deep in integer,father in emp%rowtype) is
--deep用来模拟level伪列,father用来指向当前的扩展结点,模拟prior
Cursor mycursor is--定义一个游标用来获取符合层次关系的子节点
select * from emp where mgr=father.empno ;//这里用来模拟connect by 和 and逻辑
begin
dbms_output.put_line(deep||' '||father.empno||' '||father.ename||' '||father.mgr);
--输出当前节点的信息,这里为了简化只用了empno,ename,mgr和deep代表深度四个节
for temp in mycursor loop
Treequery(deep+1,temp); //一直向下递归,deep+1
end loop;
end Treequery;
//下面这个过程用来实现对上面Treequery的调用
declare
father emp%rowtype;
begin
select * into father from emp where mgr is null;//这句模拟start with子句,选出一个根节点
if(sql%found) then
Treequery(1,father);
end if;
end;
上面这个过程的意思是,用选出mgr为空的列作为根节点,然后调用treequery函数来实现实现产生一棵子节点的mgr为父节点的empno这样的逻辑
程序运行后得到如下的结果
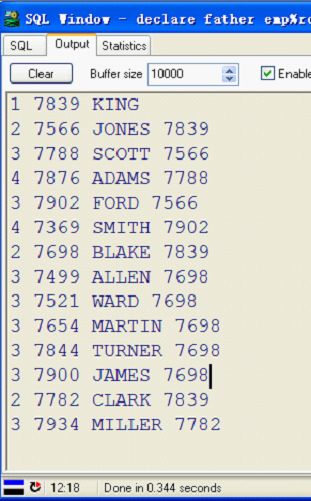
这个和
select level,empno,mgr,ename
from emp
start with mgr is null
connect by prior empno=mgr ;
结果完全一样!
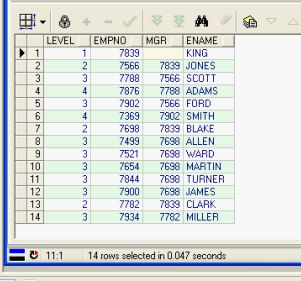
不过oracle引擎显然做得更好,我写的用时0.344s,而oracle用了仅仅0.047秒,比我快8倍!但结果是一样的。
实验五
我想到了刚辞oracle引擎里面的无穷递归问题,如果我程序可以出现类似的效果,那更可以证明我的方法和oracle引擎用的是类似的方法
create or replace procedure Treequery2(deep in integer,father in emp%rowtype) is
Cursor mycursor is
select * from emp where 1=1;//这里模拟了connect by子句永远返回值为真
begin
dbms_output.put_line(deep||' '||father.empno||' '||father.ename||' '||father.mgr);
--输出当前节点的信息,这里为了简化只用了empno,ename,mgr和deep代表深度四个节
for temp in mycursor loop
Treequery2(deep+1,temp);
end loop;
end Treequery2;
下面是调用方法
declare
father emp%rowtype;
begin
select * into father from emp where mgr is null;
Treequery2(1,father); 做了一点改变
end;
一下为程序的运行结果,和预想完全一样!!
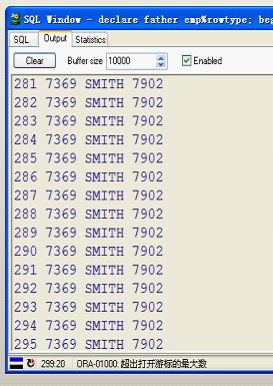
总结
通过以上的实验和思考,我现在可以解决之前的那个问题了,而且用我自己写的"引擎"可以实现完全相同的结果。
不是用and子句来对生成结果来剪枝,而是用and来约束子节点集合。
而且and自己只能对扩展的子节点加约束条件,而对当前扩展节点没有任何影响!
Prior用来指向当前的扩展节点!