异常处理机制 --- 相知篇 (七)
----------------------------------------------------------------------------------------------------------------------------
Windows系列操作系统平台中所提供的异常处理机制
本文转自 http://se.csai.cn/ExpertEyes/No157.htm
大家现在知道,在C++中有完善的异常处理机制,同样在C语言中也有很不错的异常处理机制来支持,另外在其它许多现代编程语言中,也都有各自的异常处理编程机制,如Ada语言等。那么为什么现在此处还在讨论,操作系统平台中所提供的异常处理机制呢?这是因为在许多系统中,编程语言所提供的异常处理机制的实现,都是建立在操作系统中所提供的异常处理机制之上,如Windows平台上的VC编译器所实现的C++异常处理模型,它就是建立在SEH机制之上的,在“爱的秘密”篇中,探讨VC中异常处理模型实现的时候,会进行更深入的研究和分析。另外,当然也有其它的系统,如Linux操作系统上的gcc就没有采用到操作系统中所提供的异常处理机制。但是这样会有一个很大的缺点,那就是对于应用程序的开发者而言,它不能够很好在自己的应用程序中,来有效控制操作系统中所出现的一些意外的系统异常,例如程序执行过程中可能出现的段错误,被0除等计算异常,以及其它许多不同类型的系统异常等。所以Linux操作系统上的gcc编译的程序中,它只能捕获程序中,曾经被自己显式地throw出来的异常,而对于系统异常,catch block是毫无办法的。
因此,操作系统平台中所提供的异常处理机制是非常有必要的。而且,异常处理机制的实现也是操作系统设计时的一个重要课题。通常,类Unix操作系统所提供的异常处理机制是大家非常熟悉的,那就是操作系统中的信号量处理(Signal Handling),好像这也应该是Posix标准所定义异常处理接口,因此Window系列操作系统平台也支持这种机制,“信号量处理”编程机制也会在后面的章节中进一步深入讨论。而现在(以及在接下来的几篇文章中),将全面阐述Window系列操作系统平台提供的另外一种更完善的异常处理机制,那就是大名鼎鼎的结构化异常处理(Structured Exception Handling,SEH)的编程方法。
SEH设计的主要动机
下面是出自《Window核心编程》中一小段内容的引用:
“微软在Windows中引入SEH的主要动机是为了便于操作系统本身的开发。操作系统的开发人员使用SEH,使得系统更加强壮。我们也可以使用SEH,使我们的自己的程序更加强壮。使用SEH所造成的负担主要由编译程序来承担,而不是由操作系统承担。当异常块(exception block)出现时,编译程序要生成特殊的代码。编译程序必须产生一些表( t a b l e)来支持处理SEH的数据结构。编译程序还必须提供回调( c a l l b a c k)函数,操作系统可以调用这些函数,保证异常块被处理。编译程序还要负责准备栈结构和其他内部信息,供操作系统使用和参考。在编译程序中增加SEH支持不是一件容易的事。不同的编译程序厂商会以不同的方式实现SEH,这一点并不让人感到奇怪。幸亏我们可以不必考虑编译程序的实现细节,而只使用编译程序的SEH功能。”
的确,SEH设计的主要动机就是为了便于操作系统本身的开发。为什么这么说呢?这是因为操作系统是一个非常庞大的系统,而且它还是处于计算机整个系统中,非常底层的系统软件,所以要求“操作系统”这个关键的系统软件必须要非常强壮,可靠性非常高。当然提升操作系统软件的可靠性有许多有效的方法,例如严谨的设计,全面而科学的测试。但是俗话说得好,“智者千虑,必有一失”。因此在编程代码中,有一个非常有效的异常处理机制,将大大提高软件系统的可靠性。说道这里,也许很多朋友们说:“阿愚呀!你有没有搞错,无论是C++还是C语言中,不都有很好的异常处理机制吗?为什么还需要另外再设计一种呢?”。的确没错,但是请注意,操作系统由于效率的考虑,它往往不会考虑采用C++语言来编写,它大部分模块都是采用C语言来编码的,另外还包括一小部分的汇编代码。所以,这样操作系统中最多只能用goto语句,以及setjmp和longjmp等机制。但Window的设计者认为这远远不够他们的需要,离他们的要求相差甚远。而且,尤其是在操作系统中,最大的软件模块就是设备的驱动程序了,而且设备的驱动程序模块中,其中的又有绝大部分是由第3方(硬件提供商)来开发的。这些第3方开发的驱动程序模块,与操作系统核心关联紧密,它将严重影响到整个操作系统的可靠性和稳定性。所以,如何来促使第3方开发的驱动程序模块变得更加可靠呢?它至少不会影响到操作系统内核的正常工作,或者说甚至导致操作系统内核的崩溃。客观地说,这的确很难做得到,因为自己的命运掌握在别人手里了。但是Window的设计者想出了一个很不错的方法,那就是为第3方的驱动程序开发人员提供SEH机制,来最大程度上提升第3方开发出的驱动程序的可靠性和稳定性。相信有过在Windows平台上开发过驱动程序的朋友们对这一点深有感触,而且有关驱动程序开发的大多数书籍中,都强烈建议你在编程中使用SEH机制。
现在来谈谈为什么说,C语言中的setjmp和longjmp机制没有SEH机制好呢?呵呵!当然在不深入了解SEH机制之前,来讨论并很好地解释清楚这个问题也许是比较困难的。但是主人公阿愚却认为,这里讨论这个问题是最恰当不过的了。因为这样可以很好地沿着当年的SEH的设计者们的足迹,来透析他们的设计思想。至少我们现在可以充分地分析setjmp和longjmp机制的不足之处。例如说,在实际的编程中(尤其是系统方面的编程),是不是经常遇到这种状况,示例代码如下:
#include <stdio.h>
#include <setjmp.h>
#include <stdlib.h>
jmp_buf mark;
void test1()
{
char* p1, *p2, *p3, *p4;
p1 = malloc(10);
if (!p1) longjmp(mark, 1);
p2 = malloc(10);
if (!p2)
{
// 这里虽然可以释放资源,
// 但是程序员很容易忘记,也容易出错
free(p1);
longjmp(mark, 1);
}
p3 = malloc(10);
if (!p3)
{
// 这里虽然可以释放资源
// 但是程序员很容易忘记,也容易出错
free(p1);
free(p2);
longjmp(mark, 1);
}
p4 = malloc(10);
if (!p4)
{
// 这里虽然可以释放资源
// 但是程序员很容易忘记,也容易出错
free(p1);
free(p2);
free(p3);
longjmp(mark, 1);
}
// do other job
free(p1);
free(p2);
free(p3);
free(p4);
}
void test()
{
char* p;
p = malloc(10);
// do other job
test1();
// do other job
// 这里的资源可能得不到释放
free(p);
}
void main( void )
{
int jmpret;
jmpret = setjmp( mark );
if( jmpret == 0 )
{
char* p;
p = malloc(10);
// do other job
test1();
// do other job
// 这里的资源可能得不到释放
free(p);
}
else
{
printf("捕获到一个异常/n");
}
}
上面的程序很容易导致内存资源泄漏,而且程序的代码看上去也比较别扭。程序员编写代码时,总要非常地小心翼翼地释放相关的资源。有可能一个稍微的处理不当,就可能导致资源泄漏,甚至更严重的是引发系统的死锁,因为在编写驱动程序时,毕竟与一般的应用程序有很大的不同,会经常使用到进程间的一些同步和互斥控制等。
怎么办?如果有一种机制,在程序中出现异常时,能够给程序员一个恰当的机会,来释放这些系统资源,那该多好呀!其实这种需求有点相当于C++中的析构函数,因为它不管何种情况下,只要对象离开它生存的作用域时,它总会被得以执行。但是在C语言中的setjmp和longjmp机制,却显然做不到这一点。SEH的设计者们考虑到了这一点,因此在SEH机制中,它提供了此项功能给程序开发人员。这其实也是SEH中最强大,也最有特色的地方。另外,SEH还提供了程序出现异常后,有效地被得以恢复,程序继续执行的机制,这也是其它异常处理模型没有的(虽然一般情况下,没有必要这样做;但是对于系统模块,有时这是非常有必要的)。
SEH究竟何物?
首先还是引用MSDN中关于SEH的有关论述,如下:
Windows 95 and Windows NT support a robust approach to handling exceptions, called structured exception handling, which involves cooperation of the operating system but also has direct support in the programming language.
An “exception” is an event that is unexpected or disrupts the ability of the process to proceed normally. Exceptions can be detected by both hardware and software. Hardware exceptions include dividing by zero and overflow of a numeric type. Software exceptions include those you detect and signal to the system by calling the RaiseException function, and special situations detected by Windows 95 and Windows NT.
You can write more reliable code with structured exception handling. You can ensure that resources, such as memory blocks and files, are properly closed in the event of unexpected termination. You can also handle specific problems, such as insufficient memory, with concise, structured code that doesn’t rely on goto statements or elaborate testing of return codes.
Note These articles describe structured exception handling for the C programming language. Although structured exception handling can also be used with C++, the new C++ exception handling method should be used for C++ programs. See Using Structured Exception Handling with C++ for information on special considerations.
我们虽然都知道,SEH是Window系列操作系统平台提供的一种非常完善的异常处理机制。但这毕竟有些过于抽象了点,对于程序员而言,它应该有一套类似于像C++中那样的try,catch,throw等几个关键字组成的完整的异常处理模型。是的,这的确没错,SEH也有类似的语法,那就是它由如下几个关键字组成:
__try
__except
__finally
__leave
呵呵!这是不是很多在Windows平台上做开发的程序员朋友们都用过。很熟悉吧!但是这里其实有一个认识上的误区,大多数程序员,包括很多计算机书籍中,都把SEH机制与__try,__except,__finally,__leave异常模型等同起来。这种提法是不对的,至少是不准确的。因为SHE狭义上讲,只能算是Window系列操作系统所提供的一种异常处理机制;而无论是__try,__except,__finally,__leave异常模型,还是try,catch,throw异常模型,它们都是VC所实现并提供给开发者的。其中__try,__except,__finally,__leave异常模型主要是提供给C程序员使用;而try,catch,throw异常模型,它则是提供给C++程序员使用,而且它也遵循C++标准中异常模型的定义。这多种异常机制之间的关系如下图所示:
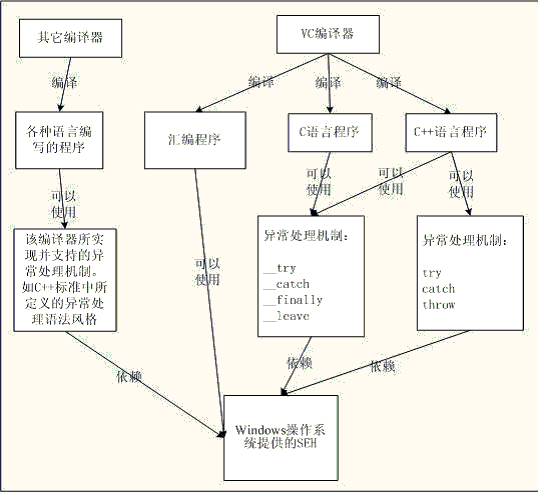
总结
为了更进一步认识SEH机制,认识SEH与__try,__except,__finally,__leave异常模型机制的区别。下一篇文章中,主人公阿愚还是拿出一个具体的例子程序来与大家一起分享。注意,它那个例子中,它既没有使用到__try,__except,__finally,__leave异常模型;也没有利用到try,catch,throw异常模型。它直接使用到Windows操作系统所提供的SEH机制,并完成一个简单的封装。继续吧!GO!
-----------------------------------------------------------------------------------------------------------------------------
更进一步认识SEH
本文转自 http://se.csai.cn/ExpertEyes/No158.htm
上一篇文章阿愚对结构化异常处理(Structured Exception Handling,SEH)有了初步的认识,而且也知道了SEH是__try,__except,__finally,__leave异常模型机制和try,catch,throw方式的C++异常模型的奠基石。
为了更进一步认识SEH机制,更深刻的理解SEH与__try,__except,__finally,__leave异常模型机制的区别。本篇文章特别对狭义上的SEH进行一些极为细致的讲解。
SEH设计思路
SEH机制大致被设计成这样一种工作流程:用户应用程序对一些可能出现异常错误的代码模块,创建一个相对应的监控函数(也即回调函数),并向操作系统注册;这样应用程序在执行过程中,如果什么异常也没出现的话,那么程序将按正常的执行流顺序来完成相对应的工作任务;否则,如果受监控的代码模块中,在运行时出现一个预知或未预知的异常错误,那么操作系统将捕获住这个异常,并暂停程序的执行过程(实际上是出现异常的工作线程被暂停了),然后,操作系统也收集一些有关异常的信息(例如,异常出现的地点,线程的工作环境,异常的错误种类,以及其它一些特殊的字段等),接着,操作系统根据先前应用程序注册的监控性质的回调函数,来查询当前模块所对应的监控函数,找到之后,便立即来回调它,并且传递一些必要的异常的信息作为监控函数的参数。此时,用户注册的监控函数便可以根据异常错误的种类和严重程度来进行分别处理,例如终止程序,或者试图恢复错误后,再使程序正常运行。
细心的朋友们现在可能想到,用户应用程序如何来向操作系统注册一系列的监控函数呢?其实SEH设计的巧妙之处就在与此,它这里有两个关键之处。其一,就是每个线程为一个完全独立的注册主体,线程间互不干扰,也即每个线程所注册的所有监控回调函数会连成一个链表,并且链表头被保存在与线程本地存储数据相关的区域(也即FS数据段区域,这是Windows操作系统的设计范畴,FS段中的数据一般都是一些线程相关的本地数据信息,例如FS:[0]就是保存监控回调函数数据结构体的链表头。有关线程相关的本地数据,这里不再详细赘述,感兴趣的朋友可以参考其它更为详细地资料);其二,那就是每个存储监控回调函数指针的数据结构体,实际上它们一般并不是被存储在堆(Heap)中,而是被存储在栈(Stack)中。大家还记得在《第9集 C++的异常对象如何传送》中,有关“函数调用栈”的布局,呵呵!那只是比较理想化的栈布局,实际上,无论是C++还是C程序中,如果函数模块中,存在异常处理机制的情况下,那么栈布局都会略有些变化,会变得更为复杂一些,因为在栈中,需要插入一些“存储监控回调函数指针的数据结构体”数据信息。例如典型的带SEH机制的栈布局如下图所示。
上图中,注意其中绿线部分所连成链表数据结构,这就是用户应用程序向操作系统注册的一系列的监控函数。如果某个函数中声明了异常处理机制,那么在函数帧栈中将分配一个数据结构体(EXCEPTION_REGISTRATION),这个数据结构体有点类似与局部变量的性质,它包含两个字段,其中一个是指向监控函数的指针(handler function address);另一个就是链表指针(previous EXCEPTION_REGISTRATION)。特别需要注意的是,并不是每个函数帧栈中都有EXCEPTION_REGISTRATION数据结构。另外链表头指针被保存到FS:[0]中,这样无论是操作系统,还是应用程序都能够很好操纵这个链表数据体变量。
EXCEPTION_REGISTRATION的定义如下:
typedef struct _EXCEPTION_REGISTRATION
{
struct _EXCEPTION_REGISTRATION *prev;
DWORD handler;
}EXCEPTION_REGISTRATION, *PEXCEPTION_REGISTRATION;
通过一个简单例子,来理解SEH机制
也许上面的论述过于抽象化和理论化了,还是看一个简单的例子吧!这样也很容易来理解SEH的工作机制原来是那么的简单。示例代码如下:
#include <windows.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct _EXCEPTION_REGISTRATION
{
struct _EXCEPTION_REGISTRATION *prev;
DWORD handler;
}EXCEPTION_REGISTRATION, *PEXCEPTION_REGISTRATION;
// 异常监控函数
EXCEPTION_DISPOSITION myHandler(
EXCEPTION_RECORD *ExcRecord,
void * EstablisherFrame,
CONTEXT *ContextRecord,
void * DispatcherContext)
{
printf("进入到异常处理模块中/n");
printf("不进一步处理异常,程序直接终止退出/n");
abort();
return ExceptionContinueExecution;
}
int main()
{
DWORD prev;
EXCEPTION_REGISTRATION reg, *preg;
// 建立异常结构帧(EXCEPTION_REGISTRATION)
reg.handler = (DWORD)myHandler;
// 把异常结构帧插入到链表中
__asm
{
mov eax, fs:[0]
mov prev, eax
}
reg.prev = (EXCEPTION_REGISTRATION*) prev;
// 注册监控函数
preg = ®
__asm
{
mov eax, preg
mov fs:[0], eax
}
{
int* p;
p = 0;
// 下面的语句被执行,将导致一个异常
*p = 45;
}
printf("这里将不会被执行到./n");
return 0;
}
上面的程序运行结果如下:
通过上面的演示的简单例程,现在应该非常清楚了Windows操作系统提供的SEH机制的基本原理和控制流转移的具体过程。另外,这里分别详细介绍一下exception_handler回调函数的各个参数的涵义。其中第一个参数为EXCEPTION_RECORD类型,它记录了一些与异常相关的信息。它的定义如下:
typedef struct _EXCEPTION_RECORD {
DWORD ExceptionCode;
DWORD ExceptionFlags;
struct _EXCEPTION_RECORD *ExceptionRecord;
PVOID ExceptionAddress;
DWORD NumberParameters;
UINT_PTR ExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS];
} EXCEPTION_RECORD;
第二个参数为PEXCEPTION_REGISTRATION类型,既当前的异常帧指针。第三个参数为指向CONTEXT数据结构的指针,CONTEXT数据结构体中记录了异常发生时,线程当时的上下文环境,主要包括寄存器的值,这一点有点类似于setjmp函数的作用。第四个参数DispatcherContext,它也是一个指针,表示调度的上下文环境,这个参数一般不被用到。
最后再来看一看exception_handler回调函数的返回值有何意义?它基本上有两种返回值,一种就是返回ExceptionContinueExecution,表示异常已经被恢复了,程序可以正常继续执行。另一种就是ExceptionContinueSearch,它表示当前的异常回调处理函数不能有效处理这个异常错误,系统将会根据EXCEPTION_REGISTRATION数据链表,继续查找下一个异常处理的回调函数。上面的例程的详细分析如下图所示:

来一个稍微复杂一点例子,来更深入理解SEH机制
现在,相信大家已经对SEH机制,既有了非常理性的理解,也有非常感性的认识。实际上,从用户角度上来分析,SEH机制确是比较简单。它首先是用户注册一系列的异常回调函数(也即监控函数),操作系统为每个线程维护一个这样的链表,每当程序中出现异常的时候,操作系统便获得控制权,并纪录一些与异常相关的信息,接着系统便依次搜索上面的链表,来查找并调用相应的异常回调函数。
说到这里,也许朋友们有点疑惑了?上一篇文章中讲述到,“无论是__try,__except,__finally,__leave异常模型机制,或是try,catch,throw方式的C++异常模型,它们都是在SEH基础上来实现的”。但是从这里看来,好像上面描述的SEH机制与try,catch,throw方式的C++异常模型不太相关。是的,也许表面上看起来区别是比较大的,但是SEH机制,它的的确确是上面讲到的其它两种异常处理模型的基础。这一点,在深入分析C++异常模型的实现时,会再做详细的叙述。这里为了更深入理解SEH机制,主人公阿愚设计了一个稍微复杂一点例子。它仍然只有SEH机制,没有__try,__except,__finally,__leave异常模型的任何影子,但是它与真实的__try,__except,__finally,__leave异常模型的实现却有几分相似之处。
//seh.c
// seh.c
#include <windows.h>
#include <stdio.h>
typedef struct _EXCEPTION_REGISTRATION
{
struct _EXCEPTION_REGISTRATION *prev;
DWORD handler;
}EXCEPTION_REGISTRATION, *PEXCEPTION_REGISTRATION;
#define SEH_PROLOGUE(pFunc_exception) /
{ /
DWORD pFunc = (DWORD)pFunc_exception; /
_asm mov eax, FS:[0] /
_asm push pFunc /
_asm push eax /
_asm mov FS:[0], esp /
}
#define SEH_EPILOGUE() /
{ /
_asm pop FS:[0] /
_asm pop eax /
}
void printfErrorMsg(int ex_code)
{
char msg[20];
memset(msg, 0, sizeof(msg));
switch (ex_code)
{
case EXCEPTION_ACCESS_VIOLATION :
strcpy(msg, "存储保护异常");
break;
case EXCEPTION_ARRAY_BOUNDS_EXCEEDED :
strcpy(msg, "数组越界异常");
break;
case EXCEPTION_BREAKPOINT :
strcpy(msg, "断点异常");
break;
case EXCEPTION_FLT_DIVIDE_BY_ZERO :
case EXCEPTION_INT_DIVIDE_BY_ZERO :
strcpy(msg, "被0除异常");
break;
default :
strcpy(msg, "其它异常");
}
printf("/n");
printf("%s,错误代码为:0x%x/n", msg, ex_code);
}
EXCEPTION_DISPOSITION my_exception_Handler(
EXCEPTION_RECORD *ExcRecord,
void * EstablisherFrame,
CONTEXT *ContextRecord,
void * DispatcherContext)
{
int _ebp;
printfErrorMsg(ExcRecord->ExceptionCode);
printf("跳过出现异常函数,返回到上层函数中继续执行/n");
printf("/n");
_ebp = ContextRecord->Ebp;
_asm
{
// 恢复上一个异常帧
mov eax, EstablisherFrame
mov eax, [eax]
mov fs:[0], eax
// 返回到上一层的调用函数
mov esp, _ebp
pop ebp
mov eax, -1
ret
}
// 下面将绝对不会被执行到
exit(0);
return ExceptionContinueExecution;
}
EXCEPTION_DISPOSITION my_RaiseException_Handler(
EXCEPTION_RECORD *ExcRecord,
void * EstablisherFrame,
CONTEXT *ContextRecord,
void * DispatcherContext)
{
int _ebp;
printfErrorMsg(ExcRecord->ExceptionCode);
printf("跳过出现异常函数,返回到上层函数中继续执行/n");
printf("/n");
_ebp = ContextRecord->Ebp;
_asm
{
// 恢复上一个异常帧
mov eax, EstablisherFrame
mov eax, [eax]
mov fs:[0], eax
// 返回到上一层的调用函数
mov esp, _ebp
pop ebp
mov esp, ebp
pop ebp
mov eax, -1
ret
}
// 下面将绝对不会被执行到
exit(0);
return ExceptionContinueExecution;
}
void test1()
{
SEH_PROLOGUE(my_exception_Handler);
{
int zero;
int j;
zero = 0;
// 下面的语句被执行,将导致一个异常
j = 10 / zero;
printf("在test1()函数中,这里将不会被执行到.j=%d/n", j);
}
SEH_EPILOGUE();
}
void test2()
{
SEH_PROLOGUE(my_exception_Handler);
{
int* p;
p = 0;
printf("在test2()函数中,调用test1()函数之前/n");
test1();
printf("在test2()函数中,调用test1()函数之后/n");
printf("/n");
// 下面的语句被执行,将导致一个异常
*p = 45;
printf("在test2()函数中,这里将不会被执行到/n");
}
SEH_EPILOGUE();
}
void test3()
{
SEH_PROLOGUE(my_RaiseException_Handler);
{
// 下面的语句被执行,将导致一个异常
RaiseException(0x999, 0x888, 0, 0);
printf("在test3()函数中,这里将不会被执行到/n");
}
SEH_EPILOGUE();
}
int main()
{
printf("在main()函数中,调用test1()函数之前/n");
test1();
printf("在main()函数中,调用test1()函数之后/n");
printf("/n");
printf("在main()函数中,调用test2()函数之前/n");
test2();
printf("在main()函数中,调用test2()函数之后/n");
printf("/n");
printf("在main()函数中,调用test3()函数之前/n");
test3();
printf("在main()函数中,调用test3()函数之后/n");
return 0;
}
上面的程序运行结果如下:
在main()函数中,调用test1()函数之前
被0除异常,错误代码为:0xc0000094
跳过出现异常函数,返回到上层函数中继续执行
在main()函数中,调用test1()函数之后
在main()函数中,调用test2()函数之前
在test2()函数中,调用test1()函数之前
被0除异常,错误代码为:0xc0000094
跳过出现异常函数,返回到上层函数中继续执行
在test2()函数中,调用test1()函数之后
存储保护异常,错误代码为:0xc0000005
跳过出现异常函数,返回到上层函数中继续执行
在main()函数中,调用test2()函数之后
在main()函数中,调用test3()函数之前
其它异常,错误代码为:0x999
跳过出现异常函数,返回到上层函数中继续执行
在main()函数中,调用test3()函数之后
Press any key to continue
总结
本文所讲到的异常处理机制,它就是狭义上的SEH,虽然它很简单,但是它是Windows系列操作系统平台上其它所有异常处理模型实现的奠基石。有了它就有了基本的物质保障,
另外,通常一般所说的SEH,它都是指在本篇文章中所阐述的狭义上的SEH机制基础之上,实现的__try,__except,__finally,__leave异常模型,因此从下一篇文章中,开始全面介绍__try,__except,__finally,__leave异常模型,实际上,它也即广义上的SEH。此后所有的文章内容中,如没有特别注明,SEH机制都表示__try,__except,__finally,__leave异常模型,这也是为了与try,catch,throw方式的C++异常模型相区分开。
朋友们!有点疲劳了吧!可千万不要放弃,继续到下一篇的文章中,可要知道,__try,__except,__finally,__leave异常模型,它可以说是最优先的异常处理模型之一,甚至比C++的异常模型还好,功能还强大!即便是JAVA的异常处理模型也都从它这里继承了许多优点,所以不要错过呦,Let’s go!
-----------------------------------------------------------------------------------------------------------------------
SEH的强大功能之一
本文转自 http://se.csai.cn/ExpertEyes/No159.htm
从本篇文章开始,将全面阐述__try,__except,__finally,__leave异常模型机制,它也即是Windows系列操作系统平台上提供的SEH模型。主人公阿愚将在这里与大家分享SEH的学习过程和经验总结。
SEH有两项非常强大的功能。当然,首先是异常处理模型了,因此,这篇文章首先深入阐述SEH提供的异常处理模型。另外,SEH还有一个特别强大的功能,这将在下一篇文章中进行详细介绍。
try-except入门
SEH的异常处理模型主要由try-except语句来完成,它与标准C++所定义的异常处理模型非常类似,也都是可以定义出受监控的代码模块,以及定义异常处理模块等。还是老办法,看一个例子先,代码如下:
//seh-test.c
#include <stdio.h>
void main()
{
puts("hello");
// 定义受监控的代码模块
__try
{
puts("in try");
}
//定义异常处理模块
__except(1)
{
puts("in except");
}
puts("world");
}
呵呵!是不是很简单,而且与C++异常处理模型很相似。当然,为了与C++异常处理模型相区别,VC编译器对关键字做了少许变动。首先是在每个关键字加上两个下划线作为前缀,这样既保持了语义上的一致性,另外也尽最大可能来避免了关键字的有可能造成名字冲突而引起的麻烦等;其次,C++异常处理模型是使用catch关键字来定义异常处理模块,而SEH是采用__except关键字来定义。并且,catch关键字后面往往好像接受一个函数参数一样,可以是各种类型的异常数据对象;但是__except关键字则不同,它后面跟的却是一个表达式(可以是各种类型的表达式,后面会进一步分析)。
try-except进阶
与C++异常处理模型很相似,在一个函数中,可以有多个try-except语句。它们可以是一个平面的线性结构,也可以是分层的嵌套结构。例程代码如下:
// 例程1
// 平面的线性结构
#include <stdio.h>
void main()
{
puts("hello");
__try
{
puts("in try");
}
__except(1)
{
puts("in except");
}
// 又一个try-except语句
__try
{
puts("in try");
}
__except(1)
{
puts("in except");
}
puts("world");
}
// 例程2
// 分层的嵌套结构
#include <stdio.h>
void main()
{
puts("hello");
__try
{
puts("in try");
// 又一个try-except语句
__try
{
puts("in try");
}
__except(1)
{
puts("in except");
}
}
__except(1)
{
puts("in except");
}
puts("world");
}
// 例程3
// 分层的嵌套在__except模块中
#include <stdio.h>
void main()
{
puts("hello");
__try
{
puts("in try");
}
__except(1)
{
// 又一个try-except语句
__try
{
puts("in try");
}
__except(1)
{
puts("in except");
}
puts("in except");
}
puts("world");
}
try-except异常处理规则
try-except异常处理规则与C++异常处理模型有相似之处,例如,它们都是向上逐级搜索恰当的异常处理模块,包括跨函数的多层嵌套try-except语句。但是,它们的处理规则也有另外一些很大的不同之处,例如查找匹配恰当的异常处理模块的过程,在C++异常处理模型中,它是通过异常对象的类型来匹配;但是在try-except语句的异常处理规则中,则是通过__except关键字后面括号中的表达式的值来匹配查找正确的异常处理模块。还是看看MSDN中怎么说的吧!摘略如下:
The compound statement after the __try clause is the body or guarded section. The compound statement after the __except clause is the exception handler. The handler specifies a set of actions to be taken if an exception is raised during execution of the body of the guarded section. Execution proceeds as follows:
1. The guarded section is executed.
2. If no exception occurs during execution of the guarded section, execution continues at the statement after the __except clause.
3. If an exception occurs during execution of the guarded section or in any routine the guarded section calls, the __except expression is evaluated and the value determines how the exception is handled. There are three values:
EXCEPTION_CONTINUE_EXECUTION (–1) Exception is dismissed. Continue execution at the point where the exception occurred.
EXCEPTION_CONTINUE_SEARCH (0) Exception is not recognized. Continue to search up the stack for a handler, first for containing try-except statements, then for handlers with the next highest precedence.
EXCEPTION_EXECUTE_HANDLER (1) Exception is recognized. Transfer control to the exception handler by executing the __except compound statement, then continue execution at the assembly instruction that was executing when the exception was raised.
Because the __except expression is evaluated as a C expression, it is limited to a single value, the conditional-expression operator, or the comma operator. If more extensive processing is required, the expression can call a routine that returns one of the three values listed above.
对查找匹配恰当的异常处理模块的过程等几条规则翻译如下:
1. 受监控的代码模块被执行(也即__try定义的模块代码);
2. 如果上面的代码执行过程中,没有出现异常的话,那么控制流将转入到__except子句之后的代码模块中;
3. 否则,如果出现异常的话,那么控制流将进入到__except后面的表达式中,也即首先计算这个表达式的值,之后再根据这个值,来决定做出相应的处理。这个值有三种情况,如下:
EXCEPTION_CONTINUE_EXECUTION (–1) 异常被忽略,控制流将在异常出现的点之后,继续恢复运行。
EXCEPTION_CONTINUE_SEARCH (0) 异常不被识别,也即当前的这个__except模块不是这个异常错误所对应的正确的异常处理模块。系统将继续到上一层的try-except域中继续查找一个恰当的__except模块。
EXCEPTION_EXECUTE_HANDLER (1) 异常已经被识别,也即当前的这个异常错误,系统已经找到了并能够确认,这个__except模块就是正确的异常处理模块。控制流将进入到__except模块中。
上面的规则其实挺简单的,很好理解。当然,这个规则也非常的严谨,它能很好的满足开发人员的各种需求,满足程序员对异常处理的分类处理的要求,它能够给程序员提供一个灵活的控制手段。
其中比较特殊的就是__except关键字后面跟的表达式,它可以是各种类型的表达式,例如,它可以是一个函数调用,或是一个条件表达式,或是一个逗号表达式,或干脆就是一个整型常量等等。例如代码如下:
// seh-test.c
// 异常处理模块的查找过程演示
#include <stdio.h>
int seh_filer()
{
return 0;
}
void test()
{
__try
{
int* p;
puts("test()函数的try块中");
// 下面将导致一个异常
p = 0;
*p = 45;
}
// 注意,__except关键字后面的表达式是一个函数表达式
// 而且这个函数将返回0,所以控制流进入到上一层
// 的try-except语句中继续查找
__except(seh_filer())
{
puts("test()函数的except块中");
}
}
void main()
{
puts("hello");
__try
{
puts("main()函数的try块中");
// 注意,这个函数的调用过程中,有可能出现一些异常
test();
}
// 注意,这个表达式是一个逗号表达式
// 它前部分打印出一条message,后部分是
// 一个常量,所以这个值也即为整个表达式
// 的值,因此系统找到了__except定义的异
// 常处理模块,控制流进入到__except模块里面
__except(puts("in filter"), 1)
{
puts("main()函数的except块中");
}
puts("world");
}
上面的程序运行结果如下:
hello
main()函数的try块中
test()函数的try块中
in filter
main()函数的except块中
world
Press any key to continue
这种运行结果应该是在意料之中吧!为了对它的流程进行更清楚的分析,下图描述出了程序的运行控制流转移过程,如下。

另外,对于__except关键字后面表达式的值,上面的规则中已经做了详细规定。它们有三种值,其中如果为0,那么系统继续查找;如果为1,表示系统已经找到正确的异常处理模块。其实这两个值都很好理解,可是如果值为-1的话,那么处理将比较特殊,上面也提到了,此种情况下,“异常被忽略,控制流将在异常出现的点之后,继续恢复运行。”实际上,这就等同于说,程序的执行过程将不受干扰,好像异常从来没有发生一样。看一个例程吧!代码如下:
#include <stdio.h>
void main()
{
int j, zero;
puts("hello");
__try
{
puts("main()函数的try块中");
zero = 0;
j = 10;
// 下面将导致一个异常
j = 45 / zero;
// 注意,异常出现后,程序控制流又恢复到了这里
printf("这里会执行到吗?值有如何呢?j=%d /n", j);
}
// 注意,这里把zero变量赋值为1,试图恢复错误,
// 当控制流恢复到原来异常点时,避免了异常的再次发生
__except(puts("in filter"), zero = 1, -1)
{
puts("main()函数的except块中");
}
puts("world");
}
上面的程序运行结果如下:
hello
main()函数的try块中
in filter
这里会执行到吗?值有如何呢?j=45
world
Press any key to continue
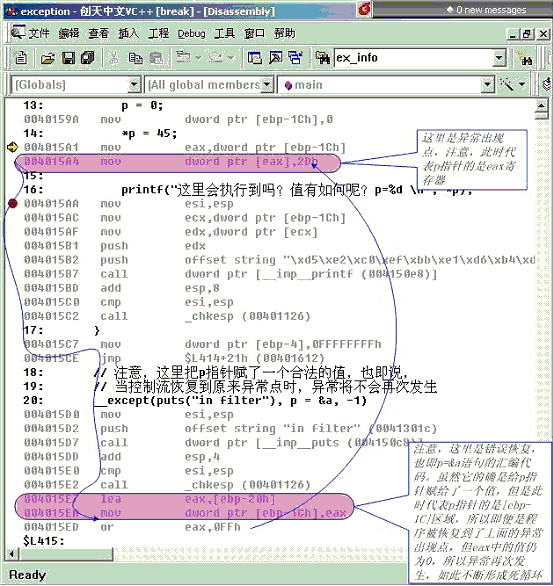
呵呵!厉害吧!要知道C++异常处理模型可没有这样的能力。但是请注意,一般这项功能不能轻易采用,为什么呢?因为它会导致不稳定,再看下面一个示例,代码如下:
#include <stdio.h>
void main()
{
int* p, a;
puts("hello");
__try
{
puts("main()函数的try块中");
// 下面将导致一个异常
p = 0;
*p = 45;
printf("这里会执行到吗?值有如何呢?p=%d /n", *p);
}
// 注意,这里把p指针赋了一个合法的值,也即说,
// 当控制流恢复到原来异常点时,异常将不会再次发生
__except(puts("in filter"), p = &a, -1)
{
puts("main()函数的except块中");
}
puts("world");
}
呵呵!大家猜猜上面的程序的运行结果如何呢?是不是和刚才的那个例子一样,异常也得以被恢复了。朋友们!还是亲自运行测试一把。哈哈!程序运行结果是死了,进行一个无限循环当中,并且控制终端内不断输出“in filter”信息。为什么会出现这种情况,难道MSDN中有关的阐述的有问题吗?或这个异常处理模型实现上存在BUG?NO!不是这样的,实际上这就是由于表达式返回-1值时,给程序所带来的不稳定性。当然,MSDN中有关的阐述也没有错,那么究竟具体原因是为何呢?这是因为,表达式返回-1值时,系统将把控制流恢复到异常出现点之后继续运行。这意味着什么呢?也许大家都明白了,它这里的异常恢复点是基于一条机器指令级别上的。这样就有很大的风险,因为上面的例程中,所谓的异常恢复处理,也即p = &a语句,它实际上的确改变了p指针值,但是这个指针值是栈上的某个内存区域,而真正出现异常时,代表p指针值的很有可能是某个寄存器。呵呵!是不是挺费解的,没关系!还是看看调试界图吧!如下:
try-except深入
上面的内容中已经对try-except进行了全面的了解,但是有一点还没有阐述到。那就是如何在__except模块中获得异常错误的相关信息,这非常关键,它实际上是进行异常错误处理的前提,也是对异常进行分层分级别处理的前提。可想而知,如果没有这些起码的信息,异常处理如何进行?因此获取异常信息非常的关键。Windows提供了两个API函数,如下:
LPEXCEPTION_POINTERS GetExceptionInformation(VOID); DWORD GetExceptionCode(VOID);
其中GetExceptionCode()返回错误代码,而GetExceptionInformation()返回更全面的信息,看它函数的声明,返回了一个LPEXCEPTION_POINTERS类型的指针变量。那么EXCEPTION_POINTERS结构如何呢?如下,
typedef struct _EXCEPTION_POINTERS { // exp
PEXCEPTION_RECORD ExceptionRecord;
PCONTEXT ContextRecord;
} EXCEPTION_POINTERS;
呵呵!仔细瞅瞅,这是不是和上一篇文章中,用户程序所注册的异常处理的回调函数的两个参数类型一样。是的,的确没错!其中EXCEPTION_RECORD类型,它记录了一些与异常相关的信息;而CONTEXT数据结构体中记录了异常发生时,线程当时的上下文环境,主要包括寄存器的值。因此有了这些信息,__except模块便可以对异常错误进行很好的分类和恢复处理。不过特别需要注意的是,这两个函数只能是在__except后面的括号中的表达式作用域内有效,否则结果可能没有保证(至于为什么,在后面深入分析异常模型的实现时候,再做详细阐述)。看一个例程吧!代码如下:
#include <windows.h>
#include <stdio.h>
int exception_access_violation_filter(LPEXCEPTION_POINTERS p_exinfo)
{
if(p_exinfo->ExceptionRecord->ExceptionCode == EXCEPTION_ACCESS_VIOLATION)
{
printf("存储保护异常/n");
return 1;
}
else return 0;
}
int exception_int_divide_by_zero_filter(LPEXCEPTION_POINTERS p_exinfo)
{
if(p_exinfo->ExceptionRecord->ExceptionCode == EXCEPTION_INT_DIVIDE_BY_ZERO)
{
printf("被0除异常/n");
return 1;
}
else return 0;
}
void main()
{
puts("hello");
__try
{
__try
{
int* p;
// 下面将导致一个异常
p = 0;
*p = 45;
}
// 注意,__except模块捕获一个存储保护异常
__except(exception_access_violation_filter(GetExceptionInformation()))
{
puts("内层的except块中");
}
}
// 注意,__except模块捕获一个被0除异常
__except(exception_int_divide_by_zero_filter(GetExceptionInformation()))
{
puts("外层的except块中");
}
puts("world");
}
上面的程序运行结果如下:
hello
存储保护异常
内层的except块中
world
Press any key to continue
呵呵!感觉不错,大家可以在上面的程序基础之上改动一下,让它抛出一个被0除异常,看程序的运行结果是不是如预期那样。
最后还有一点需要阐述,在C++的异常处理模型中,有一个throw关键字,也即在受监控的代码中抛出一个异常,那么在SEH异常处理模型中,是不是也应该有这样一个类似的关键字或函数呢?是的,没错!SEH异常处理模型中,对异常划分为两大类,第一种就是上面一些例程中所见到的,这类异常是系统异常,也被称为硬件异常;还有一类,就是程序中自己抛出异常,被称为软件异常。怎么抛出呢?还是Windows提供了的API函数,它的声明如下:
VOID RaiseException(
DWORD dwExceptionCode, // exception code
DWORD dwExceptionFlags, // continuable exception flag
DWORD nNumberOfArguments, // number of arguments in array
CONST DWORD *lpArguments // address of array of arguments
);
很简单吧!实际上,在C++的异常处理模型中的throw关键字,最终也是对RaiseException()函数的调用,也即是说,throw是RaiseException的上层封装的更高级一类的函数,这以后再详细分析它的代码实现。这里还是看一个简单例子吧!代码如下:
#include <windows.h>
#include <stdio.h>
int seh_filer(int code)
{
switch(code)
{
case EXCEPTION_ACCESS_VIOLATION :
printf("存储保护异常,错误代码:%x/n", code);
break;
case EXCEPTION_DATATYPE_MISALIGNMENT :
printf("数据类型未对齐异常,错误代码:%x/n", code);
break;
case EXCEPTION_BREAKPOINT :
printf("中断异常,错误代码:%x/n", code);
break;
case EXCEPTION_SINGLE_STEP :
printf("单步中断异常,错误代码:%x/n", code);
break;
case EXCEPTION_ARRAY_BOUNDS_EXCEEDED :
printf("数组越界异常,错误代码:%x/n", code);
break;
case EXCEPTION_FLT_DENORMAL_OPERAND :
case EXCEPTION_FLT_DIVIDE_BY_ZERO :
case EXCEPTION_FLT_INEXACT_RESULT :
case EXCEPTION_FLT_INVALID_OPERATION :
case EXCEPTION_FLT_OVERFLOW :
case EXCEPTION_FLT_STACK_CHECK :
case EXCEPTION_FLT_UNDERFLOW :
printf("浮点数计算异常,错误代码:%x/n", code);
break;
case EXCEPTION_INT_DIVIDE_BY_ZERO :
printf("被0除异常,错误代码:%x/n", code);
break;
case EXCEPTION_INT_OVERFLOW :
printf("数据溢出异常,错误代码:%x/n", code);
break;
case EXCEPTION_IN_PAGE_ERROR :
printf("页错误异常,错误代码:%x/n", code);
break;
case EXCEPTION_ILLEGAL_INSTRUCTION :
printf("非法指令异常,错误代码:%x/n", code);
break;
case EXCEPTION_STACK_OVERFLOW :
printf("堆栈溢出异常,错误代码:%x/n", code);
break;
case EXCEPTION_INVALID_HANDLE :
printf("无效句病异常,错误代码:%x/n", code);
break;
default :
if(code & (1<<29))
printf("用户自定义的软件异常,错误代码:%x/n", code);
else
printf("其它异常,错误代码:%x/n", code);
break;
}
return 1;
}
void main()
{
puts("hello");
__try
{
puts("try块中");
// 注意,主动抛出一个软异常
RaiseException(0xE0000001, 0, 0, 0);
}
__except(seh_filer(GetExceptionCode()))
{
puts("except块中");
}
puts("world");
}
上面的程序运行结果如下:
hello
try块中
用户自定义的软件异常,错误代码:e0000001
except块中
world
Press any key to continue
上面的程序很简单,这里不做进一步的分析。我们需要重点讨论的是,在__except模块中如何识别不同的异常,以便对异常进行很好的分类处理。毫无疑问,它当然是通过GetExceptionCode()或GetExceptionInformation ()函数来获取当前的异常错误代码,实际也即是DwExceptionCode字段。异常错误代码在winError.h文件中定义,它遵循Windows系统下统一的错误代码的规则。每个DWORD被划分几个字段,如下表所示:

例如我们可以在winbase.h文件中找到EXCEPTION_ACCESS_VIOLATION的值为0 xC0000005,将这个异常代码值拆开,来分析看看它的各个bit位字段的涵义。
C 0 0 0 0 0 0 5 (十六进制)
1100 0000 0000 0000 0000 0000 0000 0101 (二进制)
第3 0位和第3 1位都是1,表示该异常是一个严重的错误,线程可能不能够继续往下运行,必须要及时处理恢复这个异常。第2 9位是0,表示系统中已经定义了异常代码。第2 8位是0,留待后用。第1 6 位至2 7位是0,表示是FACILITY_NULL设备类型,它代表存取异常可发生在系统中任何地方,不是使用特定设备才发生的异常。第0位到第1 5位的值为5,表示异常错误的代码。
如果程序员在程序代码中,计划抛出一些自定义类型的异常,必须要规划设计好自己的异常类型的划分,按照上面的规则来填充异常代码的各个字段值,如上面示例程序中抛出一个异常代码为0xE0000001软件异常。
总结
(1) C++异常模型用try-catch语法定义,而SEH异常模型则用try-except语法;
(2) 与C++异常模型相似,try-except也支持多层的try-except嵌套。
(3) 与C++异常模型不同的是,try-except模型中,一个try块只能是有一个except块;而C++异常模型中,一个try块可以有多个catch块。
(4) 与C++异常模型相似,try-except模型中,查找搜索异常模块的规则也是逐级向上进行的。但是稍有区别的是,C++异常模型是按照异常对象的类型来进行匹配查找的;而try-except模型则不同,它通过一个表达式的值来进行判断。如果表达式的值为1(EXCEPTION_EXECUTE_HANDLER),表示找到了异常处理模块;如果值为0(EXCEPTION_CONTINUE_SEARCH),表示继续向上一层的try-except域中继续查找其它可能匹配的异常处理模块;如果值为-1(EXCEPTION_CONTINUE_EXECUTION),表示忽略这个异常,注意这个值一般很少用,因为它很容易导致程序难以预测的结果,例如,死循环,甚至导致程序的崩溃等。
(5) __except关键字后面跟的表达式,它可以是各种类型的表达式,例如,它可以是一个函数调用,或是一个条件表达式,或是一个逗号表达式,或干脆就是一个整型常量等等。最常用的是一个函数表达式,并且通过利用GetExceptionCode()或GetExceptionInformation ()函数来获取当前的异常错误信息,便于程序员有效控制异常错误的分类处理。
(6) SEH异常处理模型中,异常被划分为两大类:系统异常和软件异常。其中软件异常通过RaiseException()函数抛出。RaiseException()函数的作用类似于C++异常模型中的throw语句。
本篇文章已经对SEH的异常处理进行了比较全面而深入的阐述,相信大家现在已经对SEH的异常处理机制胸有成竹了。但是SEH的精华仅只如此吗?非也,朋友们!继续到下一篇的文章中,主人公阿愚将和大家一起共同探讨SEH模型的另一项重要的机制,那就是“有效保证资源的清除”。这对于C程序可太重要了,因为在C++程序中,至少还有对象的析构函数来保证资源的有效清除,避免资源泄漏,但C语言中则没有一个有效的机制,来完成此等艰巨的任务。呵呵!SEH雪中送炭,它提供了完美的解决方案,所以千万不要错过,一起去看看吧!Let’s go!