C++ AMP: C++ AMP 平铺功能简介
C++ AMP 平铺功能简介
Daniel Moth
下载代码示例
本文介绍将随同 Visual Studio 11 一同发布的名为 C++ AMP 的预发布技术。 所有信息均有可能发生变更。
Visual Studio 11 为异构计算到 c + + 加速大规模并行 (c + + AMP) 通过主流带来支持。 我在这一问题,我认为必备阅读这篇文章中的另一篇文章中介绍了 c + + AMP。 所以如果你还没读,请这样做,p 上启动。 28.
我向你介绍 GPU 编程性能优化技术称为"拼贴"之前,请记住在上一篇文章中,您学习了索引 <N>、 <N> 程度、 < T、 N > array_view、 restrict(amp) 和 parallel_for_each。 你可以使用 c + + AMP API 实现您自己的数据的并行算法,如矩阵乘法在上一篇文章中共享和在这里重复图 1。
图 1 矩阵乘法,简单的模型
1 void MatMul(vector<int>& vC, const vector<int>& vA, const vector<int>& vB, int M, int N, int W ) 2 { 3 array_view<const int, 2> a(M, W, vA), b(W, N, vB); 4 array_view<int, 2> c(M, N, vC); 5 c.discard_data(); 6 parallel_for_each(c.extent, [=](index<2> idx) restrict(amp) 7 { 8 int row = idx[0]; int col = idx[1]; 9 int sum = 0; 10 for(int i = 0; i < b.extent[0]; i++) 11 sum += a(row, i) * b(i, col); 12 c[idx] = sum; 13 }); 14 c.synchronize(); 15 }
如果您不熟悉矩阵乘法,这里是一个在线的参考:bit.ly/HiuP。
在本文中,我将向你介绍拼贴,Gpu 编程时,这是最常用的优化技术。 引入拼贴在你的算法的唯一原因是性能的额外级别,您可能可以实现通过重复使用数据和更好的内存访问模式。 拼贴允许您更好地利用 GPU 内存层次结构的较低级别比您可以用简单的模型,你知道从介绍性的文章。
有两个步骤,拼贴。 首先,您必须显式地平铺 (这一步时发生为你下盖上简单的模型) 的计算 ; 第二,你必须利用 tile_static 内存 (这第二个步骤并不为你自动发生,所以你要做这件事明确自己)。
tiled_extent 类
你知道那 parallel_for_each 接受程度对象作为其第一个参数。 程度描述计算域 — — 也就是说,多少线程 (大小) 和什么形状 (维度) 将执行计算。 考虑以下两种程度的示例:
extent<1> e(12); // 12 threads in a single dimension extent<2> ee(2,6); // 12 threads in two-dimensional space
有平铺到 parallel_for_each 接受 tiled_extent 参数的重载。 Tiled_extent 描述如何打破成同样大小的瓷砖的原始的程度。 您可以获取秩为只有三个高达的 tiled_extent。 如果您有比这更多的维度,您需要坚持做简单的模型或重构您的代码。 在平铺的线程的总数不能超过 1,024。
获取一个 tiled_extent 对象的最简单方法是通过程度,它返回 tiled_extent 为该范围内的对象上调用无参数的模板化瓦方法。 为早期程度上的两个例子中,您可以编写等),以获得相应的 tiled_extent 对象的下列:
tiled_extent<6> t_e = e.tile<6>(); // e.rank==t_e.rank tiled_extent<2,2> t_ee = ee.tile<2, 2>(); // ee.rank==t_ee.rank
图形表示请参阅图 2,其中显示了如何平铺程度分区数据分成较小的子集,这在 c + + AMP 称为拼贴。
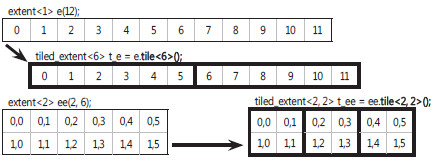
图 2 tiled_extent 是程度分为瓷砖
您选择作为必须在编译时已知的模板参数传递的数字。 他们必须均匀划分传递给 parallel_for_each 的全球范围内尺寸:
- e [0] = 12 是整除 t_e.tile_extent[0]=6
- ee [0] = 2 是整除 t_ee.tile_extent[0]=2
- ee [1] = 6 是整除 t_ee.tile_extent[1]=2
出于性能原因,最小的拼贴大小在最少-重大的尺寸应该为 16。 调整拼贴大小可以产生更好或更糟的性能结果,取决于您使用的硬件。 我的建议是,不要试图这样做 — — 相反,挑选一个数字,同样执行得好的一组广泛的硬件,从开始的这 16,甚至倍数。
tiled_index 类
你知道在 parallel_for_each 调用中传递在 lambda 与第二个参数作为您的代码。 您的代码接收索引的对象,并且你能想到的是索引的对象线程 id。例如:
parallel_for_each(my_extent,[=](index<2> idx) restrict(amp){ my_array_view[idx] = ...
});
当你平铺您传递给 parallel_for_each 的程度时,您传递中的 lambda 的签名接受 tiled_index。 Tiled_index 包含四个索引的对象。 例如,你仍然可以对您期待的 tiled_index 对象,按如下方式使用属性的索引对象:
parallel_for_each(my_extent.tile<2,2>(),[=](tiled_index<2,2> t_idx) restrict(amp){ my_array_view[t_idx.global] = ...
});
在编写时平铺的算法,你可能想知道本地索引到瓦 (不只是到整体计算域全球指数)。 您可以通过本地的 tiled_index 属性来获得该索引的对象。 对于某些算法是有用知道于计算中的其他拼贴瓷砖的索引和也的拼贴起源的全球指数。 您可以通过 tiled_index 的瓷砖和 tile_origin 属性来访问这些索引的对象。
使用前面的示例中的二维程度 (程度 <2> (2,6).tile <2,2> ()),你可以看到在图 3 突出显示广场的上述 tiled_index 属性的值。
图 3 tiled_index 属性返回索引对象
矩阵乘法 Tiled parallel_for_each 再探
在图 1 你看到了一种使用 c + + AMP 的简单模型的矩阵乘法实现。 你如何改变这种算法所以可以显式地平与你们已经学到目前为止 (使用 tiled_extent 和 tiled_index)?
解决方案所示图 4,从较早前以粗体显示的列表的更改。
图 4 矩阵乘法、 Tiled,而不使用步骤 1 tile_static
3 array_view<const int, 2> a(M, W, vA), b(W, N, vB); 4 array_view<int, 2> c(M, N, vC); 5 c.discard_data(); 6 parallel_for_each(c.extent.tile<16,16>(), [=](tiled_index<16,16> t_idx) restrict(amp) 7 { 8 int row = t_idx.global[0]; int col = t_idx.global[1]; 9 int sum = 0; 10 for(int i = 0; i < b.extent[0]; i++) 11 sum += a(row, i) * b(i, col); 12 c[t_idx.global] = sum; 13 }); 14 c.synchronize();
线上 6 我调用瓦法的程度,领料拼贴大小 (此示例中的 16 x 16),并更改接受 tiled_index 用匹配的拼贴大小模板参数 lambda。 Lambda 正文中我 t_idx.global (线 8 和 12) 替换所有 idx 出现。 这种机械论的转换是你应该做第一次为您所有的 c + + AMP 算法当您决定他们的平铺。 它是第一次 — — 但不是唯一的 — — 从简单的模型到平铺模型的旅程上的步骤。
注意到前面讨论的一件事是,这一变化,您需要确保拿均匀的拼贴大小将划分的全球范围内尺寸。 我的示例假定每个维度在哪里被 16 整除的方阵。 它也成静态的 const int 变量或模板参数吊出的拼贴大小通常的做法。
在简单的矩阵乘法样品中图 1,系统瓷砖代表在幕后您计算。 所以它隐式地平铺,而不是显式平铺和你不必担心整除的要求。 简单的模型,您不能做什么,因此你必须做你自己,是平铺的必要的第 2 步:更改使用 tile_static 内存,并且通常的一个或多个索引的其他对象使用的算法。 我深入研究之前,让我们了解一些硬件基础知识绕道而行。
简短的背景上 GPU 内存层次结构
有很多的在线内容,讨论了 GPU 硬件特征。 此内容不同取决于哪个硬件供应商它重点上,和它描述了哪些硬件家庭从每个供应商。 在这一节我提供一个高级别、 跨硬件和粗糙 (每个硬件供应商都有自己的术语和其自己的微妙之处) 的图片,从 AMP c + + 开发人员的角度。
Gpu 有您阵列和 array_view 的数据所驻留的全局内存。 也是为每个线程,这是您的本地变量通常去哪里寄存器 (除非您的硬件驱动程序有其他的想法 — — 例如,如果您使用了太多的选民登记册的硬件上执行的代码,它将波及其内容全局内存)。 是访问全局内存比访问寄存器的慢得多 — — 例如,需要一个 GPU 周期的登记准入与全局内存访问 1000 次。
此外,附近每个他们处理元素,Gpu 有小便笺本内存空间 (例如,为 48 KB,取决于硬件的 16 KB)。 这是更快的访问比全局内存 ; 也许 10 周期每访问,例如。 此内存区域,也称为本地数据存储区,是可编程的高速缓存。 CPU 缓存会自动、 透明地为您管理,并因此任何性能好处自动授予您。 与此相反,你要自己管理此 GPU 高速缓存,通过将数据复制到和它的因此,你要选择的性能收益。 某些编程模型调用此"共享内存,"其他人叫它"本地内存",然而其他人叫它"组共享内存"。在 c + + AMP 此可编程的高速缓存被称为"tile_static 记忆"— — 稍后会详细介绍。
下一步,让我们将逻辑的模型映射到 GPU 的硬件型号,从内存生存期和范围。
一块全局内存是可访问的所有线程,并其生存期超过了寿命的 parallel_for_each 计算,所以后续 parallel_for_each 调用可以对相同数据进行操作。寄存器值才可以访问一个线程,而且其生存期是线程。 一块 tile_static 内存共享的所有线程的 AMP c + + 中调用的线程的瓷砖,子集,其生存期内是这样拼贴。 现在你开始看到为什么你要平铺你计算:不知道一个线程属于哪个瓷砖,你没有办法有此快速 tile_static 的内存使用。
你可以认为作为被"租用"的线程的瓷砖拼贴完成的执行,另一种平铺在哪个点接管之前的 tile_static 内存。 所以,从逻辑上讲,从不同的瓷砖的线程是互相隔绝的 tile_static 内存,它们显示给每一个有 tile_static 内存的所有权。
使用新的 tile_static 存储类
要访问 tile_static 的内存,请使用 tile_static 存储类。 这是第二次的增强,c + + AMP 使为 c + + 语言 (其他被限制,在我以前的文章中报道)。
在 restrict(amp) 函数中,只能使用这种新的存储类和内只当 parallel_for_each 平铺,并且仅用于声明变量的功能块。 指针和引用不能标记为 tile_static,和任何隐式构造函数/tile_static 变量的不调用析构函数。 通常 (但不是总是) 你的 tile_static 变量是数组,和他们是通常成正比的拼贴大小,例如:
tile_static float t[16][16]; // Access t to access tile static memory
利用 tile_static 内存的最常用方法是识别您不止一次访问你的算法的全局内存中的区域。 然后将这些领域复制到 tile_static 内存 (只有一次付出代价的全局内存访问),然后更改你的算法使用的 tile_static (访问它非常快,多次),而不是多次访问全局内存中的数据的数据副本。 可编程的高速缓存很小,所以您不能将您的所有阵列和 array_view 数据复制到 tile_static 变量。 平铺的算法是通常更复杂,因为它需要变通,通过从全局内存复制只拼贴大小-价值的数据。
你看看一个更真实的示例,显示前一段的技术之前,让我们看看简单化、 预谋和越野车的示例,纯粹是专注于 tile_static 我尝试在其上总结一个矩阵中的所有元素的用法:
1 static const int TS = 2; 2 array_view<int, 2> av(2, 6, my_vector); 3 parallel_for_each(av.extent.tile<TS,TS>(), [=](tiled_index<TS,TS> t_idx) restrict(amp) 4 { 5 tile_static int t[TS][TS]; 6 t[t_idx.local[0]][t_idx.local[1]] = av[t_idx.global]; 7 8 if (t_idx.local == index<2>(0,0)) { 9 t[0][0] = t[0][0] + t[0][1] + t[1][0] + t[1][1]; 10 av[t_idx.tile_origin] = t[0][0]; 11 } 12 }); 13 int sum = av(0,0) + av(0,2) + av(0,4); // The three tile_origins
技术术语前面的代码是:可怕。 9 和 13 线利用的拼贴大小是 2 x 2 = 4,总体大小是 2 x 6 = 12 (因此三砖),当真正实现应该写在这样一种方式,以便更改拼贴大小或整体的程度并不意味着改变任何其他代码。 此代码的性能也是可怕的因为它有一种天真算法和其分支不适合进行数据并行化。没有能重用的数据中的算法,因此 tile_static 内存的使用甚至不有道理。 也是我稍后会提及的正确性错误。 但是,此代码是可怕,它已经够简单的人能够理解代码 tile_static 存储品牌新 — — 这就是所有的事情。
第 6 行每个线程,每个拼贴中的复制数据到其 tile_static 内存从全局内存。 在第 9 行,每个拼贴的第一个线程将成第一位的麻将牌 tile_static 内存求和麻将牌的结果。 然后行上 (每个拼贴) 在同一线程将存储结果 10 回全局内存。 然后加速器计算完成,并在 13 号线上的主机端,CPU 线程相加三款项从三拼贴到 sum 变量。
你发现正确性的错误,特别是争用条件吗? 到下一节,了解平铺的 API 的最后部分,这将帮助我们处理这个 bug。
tile_barrier 类
在前面的示例中的争用条件是线 6 和 9 之间。 行 9 具有本地索引 (0,0) 的线程假定所有的值都已经存储在 tile_static 变量 t,即只当拼贴中的所有其他线程已经执行 6 线则为 true。 因为彼此独立的普遍执行的线程,这并不是一个假设,您可以进行。
你在这里需要的是才会拼贴中的所有线程都执行了第 6 行,必须都执行方式编纂的九号线的条件。 您可以使用表示该约束的方法是通过使用 tile_barrier,并调用其等待方法之一。 您不能自己,构造一个 tile_barrier 对象,但您可以获取一个通过屏障属性从传递给您 lambda 的 tiled_index。所以通过 6 行后插入以下行,可修复争用条件:
7 t_idx.barrier.wait();
请注意,您不能放置在第 9 行之前和在条件块中的这条线。 对 tile_barrier::wait 的调用必须出现在哪里拼贴中的所有线程都将达到该位置或所有人都将绕过它的位置。 如果屏障被允许放置在这些地点,然后如果一个线程在平铺没执行等,该程序会挂起,该线程在等待。
编译器能够将其标记为你,这些争用条件的许多和那些不能,调试器可以找到你是否在 Visual Studio 11 您打开异常对话框中,从调试下 GPU 内存访问异常 |例外的菜单。
示例:平铺的矩阵乘法
你还记得中的矩阵乘法示例图 4吗? 它现在是时候拼贴行使时,还会利用 tile_static 内存,不可避免地将使用本地索引和 tile_barrier 对象的第 2 部分。
然后再显示解决方案,我会提醒您我的笔记本电脑机器上简单的 c + + AMP 矩阵乘法的收益率提高性能的 40 倍以上相比为 M = N 系列的 CPU 代码 = W = 1024。 平铺的解决方案您将要用 TS = 16 (因此 16 x 16 = 256 线程每平铺),看是额外的简单模型比快两倍 ! 该测量包括数据传送,所以如果你有已传输了数据,对数据,执行的计算的数量,那么内核执行时间会比变量更多速度快两倍,不使用 tile_static 的内存。 所以什么复杂性价格你付这种性能提升?
完全平铺的矩阵乘法代码所示图 5。
图 5 矩阵乘法,平铺加上使用 tile_static 内存
1 void MatMul(vector<int>& vC, const vector<int>& vA, const vector<int>& vB, int M, int N, int W ) 2 { 3 array_view<const int,2> a(M, W, vA), b(W, N, vB); 4 array_view<int,2> c(M, N, vC); 5 c.discard_data(); 6 7 parallel_for_each(c.extent.tile<TS,TS>(), [=](tiled_index<TS,TS> t_idx) restrict(amp) 8 { 9 int row = t_idx.local[0]; int col = t_idx.local[1]; 10 tile_static int locA[TS][TS], locB[TS][TS]; 11 int sum = 0; 12 for (int i = 0; i < a.extent[1]; i += TS) { 13 locA[row][col] = a(t_idx.global[0], col + i); 14 locB[row][col] = b(row + i, t_idx.global[1]); 15 t_idx.barrier.wait(); 16 17 for (int k = 0; k < TS; k++) 18 sum += locA[row][k] * locB[k][col]; 19 t_idx.barrier.wait(); 20 } 21 c[t_idx.global] = sum; 22 }); 23 c.synchronize(); 24 }
虽然中的代码图 5为任何作品贴图大小和任何总范围大小,(符合前面所述的规则),最简单的方法来了解它的作用是使用小的数字。 小号码不执行好在运行时,但他们做帮助我们怎么控制上。 现在,让我们假定是由 2 2 的瓷砖 (TS = 2) M = 2,N = 6 和 W = 4。 此配置描绘了图 6。
图 6 矩阵乘法示例 2 由 2 砖 12 个线程
理解代码,请按照只是一个拼贴,第二个瓦 (三个),并只是一个特定的线程:计算结果 160 的线程 (这以突出显示图 6— — 包括突出显示的行和列的 B 此线程需要访问到的 C 的单元格中计算结果的)。
让我们走过的代码图 5 同时密切注意的有用图片图 6。
当我 = 0,并行监视窗口,在图 7 第 16 行中显示的值,直到内部循环相关的变量。

图 7 时我 = 0,其他变量的值显示在每个列中,每一行都是一个线程
正如您所看到的四个线程拼贴的合作,将数据复制到两个阵列失水事故 tile_static 和 locB 从矩阵 A 和 b。 然后,他们所有行 15 屏障在相遇后,他们可以进入内部循环线 17 上的情况。 请参阅图 8 的相关变量的值,对于这两个 k = 0,然后 k = 1。
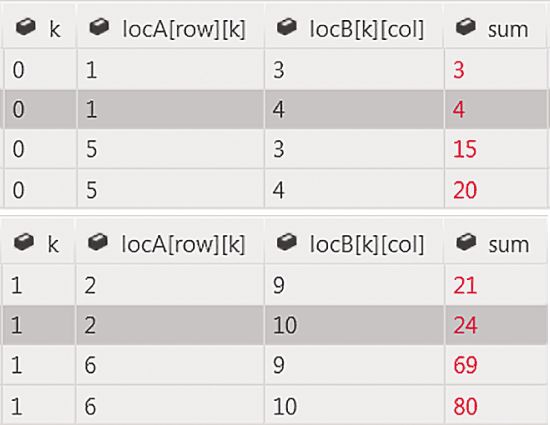
图 8 直到我 = 0,其他变量的值显示为 k = 0 和 k = 1
此时你们正在跟随的线程计算 1 x 4 部分款项并在第二个变量 k 迭代添加到 2 x 10,即共 24 (请参见图 8)。 然后,它满足其他线程在 19 线上的障碍。 现在,他们随时准备投入外环路上的第二个迭代。 注意到我的变量就会有 2、 价值和图 9 显示相关新直到屏障的变量的值。

图 9 时我 = 2,此表所示的其他变量的值
再一次的四个线程拼贴的合作,将数据复制到两个 tile_static 阵列失水事故和从矩阵 A 和 B,向右移动矩阵 A 和向下矩阵 B.locB 然后,他们都在行 15 屏障见面后,他们再次输入内部循环线 17 ; 请参阅图 10 的相关变量的值,对于这两个 k = 0 和 k = 1。
在这一点上,根据图 10、 你们正在跟随的线程将添加到 24 3 x 16 产品和对第二个 k 它进一步的迭代添加 4 x 22,制作一总计 160 笔。 然后,它满足其他线程在 19 线上的障碍。 现在可以对外部循环,进入第三次迭代的线程,但他们意识到循环条件不再纳为变量我,所以他们跳到 21 行。 你们正在跟随的线程使用其全球的索引更新的全局内存在 C
图 10 直到我 = 2,其它变量的值显示为 k = 0 和 k = 1
您可以看到现在如何矩阵中的每个元素是从全局内存一次复制,每个线程,然后重复使用每个拼贴中的其他线程。 如我较早前所说,性能提高来自能将数据块从全局内存一次复制到 tile_static 的内存,然后重复使用多次在代码中的数据的那块。
为帮助您理解代码,我选择了 4 (TS = 2) 的拼贴大小加上小扩展盘区,但在实际代码,这两个问题将是一种较大。 我共享早些时候倚的 16 x 16 = 256 的性能数字线程每瓦,所以我重用一块 256 倍从快速内存,而不是从全局内存访问每个时间的数据。 平铺的矩阵乘法实现另外更好的内存访问模式,矩阵 A (虽然在所有实现高效地访问的矩阵 B 和 C),但内存合并的好处是超出了本文的范围。
这是平铺的矩阵乘法的 tile_static 内存优势,采用的结论。 如果您希望更多的实践工作出平铺的算法,在"并行编程中的本机代码"团队博客上看到样品 bit.ly/xZt05R。
权衡
在这篇文章我介绍你给平铺,最常见的优化技术,优化您的 AMP c + + 代码。
加上 tile_static 存储类,您学习了如何使用三个新的 c + + AMP 类 (tiled_extent、 tiled_index 和 tile_barrier)。 你知道你可以简单的 (不是显式拼接) 执行。 然后你可以通过调用 (采摘的拼贴大小) 在多大程度上对象上的瓷砖函数修改执行和修改您的 lambda 签名接受 tiled_index (以相同的拼贴大小模板参数)。
完成机械化的第一步。 第二个也是最后一步,为你改写你适当使用的同步使用 tile_barrier tile_static 内存使用的算法。 这是创造性的步骤,为每个算法有想出一个全新的解决方案。 矩阵乘法的简单、 平铺的实现表明引入的拼贴,复杂性及还其用法为什么会导致性能收益。 代价是你的选择中,或选择不。
值得一提的这种高速缓存感知编程可能会导致您的 CPU 代码速度的提升,太,因为你会帮助透明的自动缓存管理系统做的更好。 另外,平铺的代码成为更适于矢量化由智能的编译器。
超越我的两篇文章,有丰富的 c + + AMP 上的并行编程团队博客的内容 (文档、 提示、 模式、 视频和样品的链接) (bit.ly/bWfC5Y) 我大力鼓励您阅读。
Daniel Moth 是 Microsoft Developer Division 的首席项目经理。他可取道 danielmoth.com/Blog。
多亏了以下的技术专家审查这篇文章:Steve Deitz、Yossi Levanoni、Robin Reynolds-Haertle、Stephen Toub 和 Weirong Zhu
http://msdn.microsoft.com/zh-cn/magazine/hh882447.aspx