c/c++性能优化--- cache优化的一点杂谈
c/c++性能优化--- cache优化的一点杂谈
之前写了一篇关于c/c++优化的一点建议,被各种拍砖和吐槽,有赞成的有反对的,还有中立的,网友对那篇博客的的评论和吐槽,我一个都没有删掉,包括一些具有攻击性的言论。笔者有幸阅读过IBM某个项目的框架代码,和我以前看过的一些代码(包括国内某顶级电信商的代码),感觉人家在细节上做的比较细,对代码的效率和安全性花了不少心思。当然国内公司也有好的代码,但是我觉得中国和美国不仅在硬件方面落后,软件方面也要落后(额,可能有人不同意我的观点。。)。这篇关于C/C++ cache优化的一点建议,个人理解能力的确有限,希望能有牛人补充一些内容,大家多多交流。同时这篇文章也是对上篇博文的一些补充性说明。后续还会有其他的关于性能调优的内容出来,欢迎大家吐槽和拍砖。关于代码要不要优化,怎么优化,优化过了,会不会影响可移植性,大家都各有说辞。也希望给出自己的观点
内容提要:
一:为什么需要memory optimization
在过去的20年cpu的速率每年提高60%左右,但是memoryspeed 每年提高10%左右。因此,人们用cache memory 弥补他们之间的速度gap,cache的使用不当可能会导致lower performance,同时你有没有思考过:SIMD指令为什么能比普通指令快上2~8倍,我们的硬件按照摩尔定律不断的提升性能,主流编译器能不能跟上这个脚步呢??
这一段简单介绍一下cache的基础知识:cache一般由两部分构成data cache和code cache(要说明一下code cache是给instruction用的),cache 还有一个level的概念,后面将介绍。为了快速访问memory,cache引入了cache line的机制,它是指把cache分成许多个32~64bytes的line单元,还有direct-mapped和N-way set-associative,这里不再详细介绍。图1给出了一些主流设备的Cache值
|
|
L1 cache (I/D) |
L2 cache |
| PS2 |
16K/8K† 2-way |
N/A |
| GameCube |
32K/32K‡ 8-way |
256K 2-way unified |
| XBOX |
16K/16K 4-way |
128K 8-way unified |
| PC |
~32-64K |
~128-512K |
图1 cache memory
二:memory结构
结构如下图2所示,各个层的访问速度是有差别的cpu是1 cycle左右,L1 cache 1-5个cycle左右,L2 Cache 5-20个左右,而memory在40-100左右。
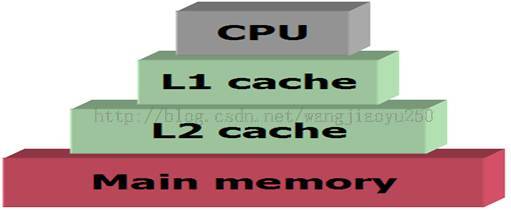
图2 memory hierarchy
关于cache优化问题,很多人嗤之以鼻,他们认为cache太小了,以至于cache missing是不可避免的。其实通过Rearrange、Reduce和Resue这三个被有些公司称为3R 准则,是可以避免一部分cache missing ,一定程度上提高访问速度。当然有些人反问:提高了又怎么样,能有明显提高吗,应该更关注功能而不是效率,不应该在一些细枝末叶上下功夫,而且你过分的优化,会导致可移植性变差,人力成本上升?好吧,你可以持有这种观点,但是我仍然希望你能把这篇文章读完。
三:针对code和data的cache优化
这里给出几个建议,第一 reorder你的函数,我指的是尽量使函数彼此引用变得紧凑,额,如果你能reorder 在linking期的object files更好了,另外如果能理解gcc的__attribute__编译属性就更好了。另外,一些大的encapsulation也会导致cache missing问题。额,关于encapsulation,很多人站出来喊:老子用C++或者其它面向对象的语言就是因为看好encapsulation所带来的安全性和易用性,当然这个观点我不反对,这里就是说明一下可能会导致cache missing问题;第二 内联、递归和大的宏可能会导致code cache missing问题,额,希望不要理解成不要用内联、宏和递归。第三:prefetching的时间要把握好,还有preloading,这两个貌似很难,具体的详细内容可以看这两篇文章CPU cache prefetching: Timing evaluation of hardware implementations,和An Effcient Architecture for LoopBased Data Preloading,这里提到这两个概念,是为了后面例子铺垫的。
例一:
// Loop through and process all 4n elements
for (int i = 0; i < 4 * n; i++)
Process(elem[i]);
const int kLookAhead = 4; // Some elementsahead
for (int i = 0; i < 4 * n; i += 4) {
Prefetch(elem[i + kLookAhead]);
Process(elem[i + 0]);
Process(elem[i + 1]);
Process(elem[i + 2]);
Process(elem[i + 3]);
}
Elem a = elem[0];
for (int i = 0; i < 4 * n; i += 4) {
Elem e = elem[i + 4]; // Cache miss, non-blocking
Elem b = elem[i + 1]; // Cache hit
Elem c = elem[i + 2]; // Cache hit
Elem d = elem[i + 3]; // Cache hit
Process(a);
Process(b);
Process(c);
Process(d);
a= e;
}
这里三段程序功能上是一样的,实现过程是有区别的,读者可以思考一下他们之间的差异性会,要考虑到cache读取数据时,是按照line读入的,函数调用时尽量能读入同一个line中的数据。下面再举一个例子说明(该例子来自Rogue WaveSoftware)例一留给读者思考。
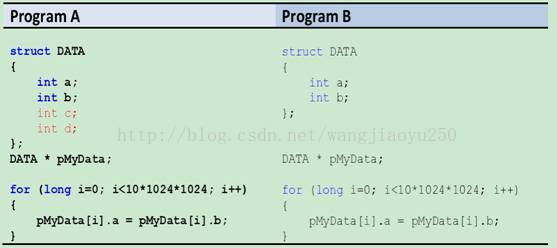
大家看到这两个代码唯一不同的就是DATA结构体的大小,那么这对运算速度有何影响呢,实际测试program B的速度大概为program A的速度二倍左右,这只是个估计值,具体到不同的平台可能会有所差别。下面分析一下,为什么会有这种差别呢?下面看看这两个不同的DATA在cache中的情况:


上两个图可以明显看出:programB 程序一个cache line能容纳更多的a,b这个减小了cache 交换数据的次数,也节省了时间。说的专业点就是program B的fetch利用率比program A的要高,关于fetch 利用率的问题可以参考PierceJ, Mudge T. Wrong-path instructioning。读者可以考虑下面这两段代码在效率上有何不同,
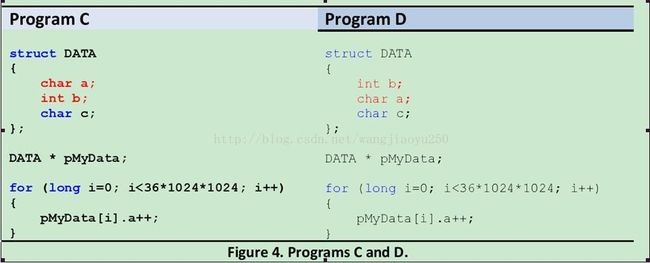

第四:注意你的编译器padding机制,大家在你机器上测试一下这3个结构体的大小。你封装的数据最好紧凑些,这对fetch的效率有帮助。前面已经举过例子。
struct X {
int8 a;
int64 b;
int8 c;
int16 d;
int64 e;
floatf;
};
struct Y {
int8 a,pad_a[7];
int64 b;
int8 c,pad_c[1];
int16 d, pad_d[2];
int64 e;
float f, pad_f[1];
};
struct Z {
int64 b;
int64 e;
float f;
int16 d;
int8 a;
int8 c;
};
第五:关于使用树的问题,很明显不同的遍历方式和存储方式会对效率产生影响,也有很多算法对树的访问以及结构做了调整,当然这都是针对具体问题而言的,例子希望大家补充。Breadth-first order和Depth-first order很显然这两种访问方式会有不同的效果,也会有不同的fetch 效率。可以参看Ren J,Pan W, Zheng Y, et al. Array based HV/VH tree: an effective data structure for layout representation.无论怎样设计和访问树,尽量使你要用到的数据线性排列(可以理解成要使用的数据相互挨着),这样做的好处前面已经提到。有些程序员使用内存池去减轻一些大数据所带来的频繁内存申请和释放操作所带来的负荷和内存碎片,额,写到树想起来的,有点跑题了。。关于内存池的使用务必要小心谨慎,跟具体的程序有关。
四:Aliasing问题
所谓的Aliasing(更详细的可以参考Understanding StrictAliasing by Mike Acton)是指对同一storage location出现多次引用(如int n; int *p1 = &n; int *p2 = &n;),这的确可以影响cache性能,ANSI c/c++有这段话:Each area of memory can only beassociated with one type during its lifetime and Aliasing may only occurbetween references of the same compatible type(还有人提出这种问题也会导致编译器优化不足,,具体我也解释不清,欢迎补充)额,跑题了。当Aliasing出现时,cache区分不了多次引用来同一个storage location,它会根据变量名去prefetch data。会导致来自同一个storage location的内容被多次读入,而且可能会在不同的line中。有些编译器引入了restrict 型指针和引用来规避这种问题,这个关键词1999的ANSI/IOS已经引入了。但我不知道你的编译器是否支持。更有大牛提出了SIMD+restrict这种搭配方案可以参(http://scc.ustc.edu.cn/zlsc/sugon/intel/compiler_c/main_cls/optaps/common/optaps_vec_simd.htm),还有有的人提出尽量使用局部变量代替全局变量,尽可能的让这些引用同一stroagelocation的变量紧凑些。
五:常用的优化工具,现在主流的优化和调试工具主要来自像IBM,INTEL,GOOGLE等公司,当然还有专门做此类软件的公司,我用过的有boundcheck,IBM Rational ,FileMon,TrueCoverage,Logiscope,KlocWork 7等,都有各自的特点。希望能帮你定位的程序的问题,当然这些工具不限于优化级别,还可以帮你查错。
c/c++性能优化--I/O优化(上)
这节本想直接介绍I/O优化的,后来思考一下有必要对常用的I/O操作函数的特点介绍一下,这样要好些。下面就先介绍和I/O有关的库函数(以C99为准)
不同的操作系统有不同的文件管理方式,现行的主要有FAT(fileallocation table)、FAT32、NTFS(new technoly file system)、NWFS(netware file system)以及UFS(unix file system)当然还有一些分布式文件管理系统如:AFS(andrew filesystem)、DFS、Micorsoft DFS和NFS(net file system),这些文件系统的安全机制和属性都有着区别,所以当你做I/O优化时,要关注一下你所用的文件系统类型。
第一:对于一些格式化输入输出函数要注意检查format的类型是否匹配如fprintf(),printf(), sprintf(), snprintf(), vfprintf(), vprintf(), vsprintf()和vsnprintf()等。
第二:remove(),rename(),fopen(),freopen()这几个函数使用时要注意两点:a,要指定文件名和操作属性;b,这些操作可以改变文件属性,有的改动是不可逆的,一定要小心。如fopen的时候,remove就不能使用。多路并发的时候尤其要注意。关于多线程/多进程的风险控制,后面会有详细介绍,这里提到一下。
第三:文件路径推荐标准化处理,另外根据要求,选择相对路径和绝对路径。有很多公司都有封装好的canonicalize path name module,如果你是新人,问一下老员工。千万别等到软件发布时,才发现路径有问题。
第四:fopen使用的时候,要知道你是要创建一个文件还是打开一个已经存在的。有些人为了避免混淆,在fopen做了一层封装(wrapper),如创建文件用creat_file封装fopen的创建文件功能,对我自己而言,我不太喜欢用这种wrapper。当然这是个人习惯。总之你要知道自己的目的。
第五:文件操作函数,如果有返回值的一定要检查返回值,确定文件操作结果是你想要的。
使用error_no解析文件操作结果时,多线程时要注意控制粒度。具体解决方案,可以参考任何一本多线程书籍。或多或少都有提及怎么安全使用error_no。
第六:用fseek()替换rewind(),原因很简单rewind没有返回值,无法做安全性检查。fseek(stream, 0L, SEEK_SET)在功能上和rewind一样。
第七:remove,rename操作的时候,确定文件的状态是否是open。
第八:当代码对数据完整性有要求时,请用fflush()刷新缓冲区。
第九:用setvbuf代替setbuf ,同样理由是前者可以做安全性检查setbuf(stream, buf)==setvbuf(stream, buf, _IOFBF, BUFSIZ) or setvbuf(stream, buf, _IONBF, BUFSIZ)
第十:了解text mode和binary mode的区别。这两种模式下使用fseek和ungetc的方式是不同的。希望读者自己总结
第十一:习惯用foef和ferror来检查文件结尾和文件操作错误
第十二:getc()和putc()是宏,所以有边际效应。如char *file_name;
FILE *fptr;
/*Initialize file_name */
int c = getc(fptr = fopen(file_name,"r"));
if (c == EOF) {
/*Handle error */
}
//文件被打开了两次。。所以会出错。应该这样写:
int c;
char *file_name;
FILE *fptr;
/*Initialize file_name */
fptr= fopen(file_name, "r");
if (fptr == NULL) {
/*Handle error */
}
c= getc(fptr);
if (c == EOF) {
/*Handle error */
}
第十三:最后再强调一下,文件打开要关闭,返回类型要做安全检查。
关于C++流操作的话题,将会在后面的内容介绍,这里只介绍C的,也欢迎大家补充这方面的内容