- 概述
- 命名空间Namesystem
- 文件目录管理
- i-node介绍
- linux i-node介绍
- hdfs的 INode介绍
- INodeFile
- INodeDirectory
- i-node介绍
- 块管理
- 数据块BlockInfoContiguous
- 集群中所有的块的管理
- 文件目录管理
- DatanodeStorageInfo 数据节点存储
- 总结
http://zhangjun5965.iteye.com/blog/2377005
概述
hdfs的内部的文件和目录是如何以树的结构存储的,每个文件对应的块是如何存储的,每个块对应的怎么对应到每一个datanode的,这些结构在hdfs的内部源码是用哪些变量存储的,整体结构是怎么连接起来的,下面我们通过Hadoop的最新稳定版代码(2.7.3)来学习一下。
命名空间Namesystem
org.apache.hadoop.hdfs.server.namenode.FSNamesystem类是hdfs的核心,存储了hdfs的命名空间相关的很多东西,具体来说就是为DataNode做簿记工作,所有datanode的请求都经过FSNamesystem类来处理。
具体他做了哪些重要的工作,我们来看相关注释
/*************************************************** * FSNamesystem does the actual bookkeeping work for the * DataNode. * * It tracks several important tables. * 文件名 -> 数据块(存放在磁盘,也就是FSImage和日志中) * 1) valid fsname --> blocklist (kept on disk, logged) 合法的数据块列表(上面关系的逆关系) * 2) Set of all valid blocks (inverted #1) 数据块 -> DataNode(只保存在内存中,根据DataNode发过来的信息动态建立) * 3) block --> machinelist (kept in memory, rebuilt dynamically from reports) DataNode上保存的数据块(上面关系的逆关系) * 4) machine --> blocklist (inverted #2) 通过LRU算法保存最近发送过心跳信息的DataNode * 5) LRU cache of updated-heartbeat machines ***************************************************/文件目录管理
/** The namespace tree. */
FSDirectory dir;
private final BlockManager blockManager;在namenode中,对hdfs的目录以及下面的子目录、文件的操作相当的复杂,会涉及到内存、硬盘的相关操作,还需要和很多对象打交道,FSDirectory主要就是对这个内部的复杂的操作做了一个简单的封装,对外提供一个简单的操作接口。
FSDirectory中很多重要的操作都和ClientProcotol协议中定义的相关方法一一对应,如addBlock等.
FSDirectory对象中有一个非常重要的INodeDirectory类型的变量rootDir,这个变量在内存中保存这个整个hdfs的目录树,下面我们对INode相关的知识做一下介绍。
i-node介绍
linux i-node介绍
在Linux中,inode是一个非常重要的设计,具体我这里就不介绍了,大家可以参考下这个文章。
http://www.ruanyifeng.com/blog/2011/12/inode.html
hdfs的 INode介绍
org.apache.hadoop.hdfs.server.namenode.INode类是整个文件的一个抽象,其子类INodeDirectory和INodeFile分别表示目录和相应的文件,我们来看下具体的类之间的关系

其中,INode的直接子类INodeWithAdditionalFields存储了一个文件或者目录共有的一些东西,如id、名字、访问权限、访问时间等
/** The inode id. */
final private long id;
/** * The inode name is in java UTF8 encoding; * The name in HdfsFileStatus should keep the same encoding as this. * if this encoding is changed, implicitly getFileInfo and listStatus in * clientProtocol are changed; The decoding at the client * side should change accordingly. */
private byte[] name = null;
/** * Permission encoded using {@link PermissionStatusFormat}. * Codes other than {@link #clonePermissionStatus(INodeWithAdditionalFields)} * and {@link #updatePermissionStatus(PermissionStatusFormat, long)} * should not modify it. */
private long permission = 0L;
/** The last modification time*/
private long modificationTime = 0L;
/** The last access time*/
private long accessTime = 0L;INodeFile
在INodeFile类的内部,有一个非常重要的变量blocks,以一个数组的的形式保存着这个文件对应的块,具体的BlockInfoContiguous的相关信息将在下节来讲述。
private BlockInfoContiguous[] blocks;INodeDirectory
INodeDirectory重要就是表示的hdfs中的目录树,和其他文件系统类似,一个目录最重要的就是他的子目录,在该类中,用一个INode类型的集合变量children表示。
private List<INode> children = null;块管理
hdfs中所有块的管理通过FSNamesystem中的BlockManager变量来管理,主要可以提供一些常用的的服务,比如通过blockid查询块,某一个块位于哪个datanode等等
private final BlockManager blockManager;BlockManager通过BlocksMap来存储信息
private final Namesystem namesystem;
private final DatanodeManager datanodeManager;
/** * Mapping: Block -> { BlockCollection, datanodes, self ref } * Updated only in response to client-sent information. */
final BlocksMap blocksMap;数据块BlockInfoContiguous
接下来我们说说hdfs中块的最重要的 一个类,这个类里最核心的变量是一个Object的数组triplets。
/** * This array contains triplets of references. For each i-th storage, the * block belongs to triplets[3*i] is the reference to the * {@link DatanodeStorageInfo} and triplets[3*i+1] and triplets[3*i+2] are * references to the previous and the next blocks, respectively, in the list * of blocks belonging to this storage. * * Using previous and next in Object triplets is done instead of a * {@link LinkedList} list to efficiently use memory. With LinkedList the cost * per replica is 42 bytes (LinkedList#Entry object per replica) versus 16 * bytes using the triplets. */
private Object[] triplets;
/** * Construct an entry for blocksmap * @param replication the block's replication factor */
public BlockInfoContiguous(short replication) {
this.triplets = new Object[3*replication];
this.bc = null;
}我们通过代码看到,object数组的长度就是3*replication(3乘以block的副本数),
triplets[i]:存储DatanodeStorageInfo对象,Block所在的DataNode;
triplets[i+1]:存储BlockInfoContiguous对象,该DataNode上该block前一个Block;
triplets[i+2]:存储BlockInfoContiguous,该DataNode上该block后一个Block;
这样通过存储块在DataNode上的上一个和下一个块实现了一个双向链表。就能快速的遍历该datanode上的所有的block,其实就是一个linkedlist,但是按照注释中的说法,要比linkedlist节省空间,对于hdfs这些一个巨大的文件系统来说,每个块存储多一点空间,整体上将会是巨大的开销。
集群中所有的块的管理
集群中所有的块的管理通过BlockManager中BlocksMap类型的对象blocksMap来管理
BlocksMap通过GSet存储映射
private GSet<Block, BlockInfoContiguous> blocks;GSet是自定义的一个set集合,如下代码所示,E必须是K的子类
/** * A {@link GSet} is set, * which supports the {@link #get(Object)} operation. * The {@link #get(Object)} operation uses a key to lookup an element. * * Null element is not supported. * * @param <K> The type of the keys. * @param <E> The type of the elements, which must be a subclass of the keys. */
@InterfaceAudience.Private
public interface GSet<K, E extends K> extends Iterable<E>保存hdfs的块的管理用的是GSet的子类LightWeightGSet.
DatanodeStorageInfo 数据节点存储
在介绍BlockInfoContiguous的时候,我们知道object数组第一项存储的是该块所在的datanode信息,即DatanodeStorageInfo类型的对象。
/** * A Datanode has one or more storages. A storage in the Datanode is represented * by this class. */
public class DatanodeStorageInfo{
........................
private final DatanodeDescriptor dn;
private final String storageID;
private StorageType storageType; //存储类型,disk,ssd等
private State state;
private long capacity;
private long dfsUsed;
private volatile long remaining;
private long blockPoolUsed;
private volatile BlockInfoContiguous blockList = null;
private int numBlocks = 0;
// The ID of the last full block report which updated this storage.
private long lastBlockReportId = 0;
/** The number of block reports received */
private int blockReportCount = 0;
..............................
}通过注释,我们了解到一个datanode有不止一个存储,该类所表示的是datanode相关的存储信息。
其中DatanodeDescriptor对象是namenode对datanode的抽象,里面封装了一些datanode基本信息.
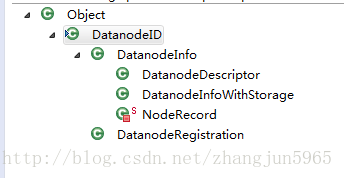
DatanodeDescriptor相关的类的继承关系如上图,DatanodeID封装了datanode相关的一些基本信息,如ip,host等。
private String ipAddr; // IP address
private String hostName; // hostname claimed by datanode
private String peerHostName; // hostname from the actual connection
private int xferPort; // data streaming port
private int infoPort; // info server port
private int infoSecurePort; // info server port
private int ipcPort; // IPC server port
private String xferAddr;总结
通过上面的学习,我们基本捋请了整个hdfs的目录和文件是如何存储的,每个文件包含了哪些数据块,每个数据块存储在哪个datanode上,具体的host和port是多少。
还简单了解了下hdfs是如何通过blockmanage来管理hdfs中所有的数据块