Android实战——科大讯飞语音听写SDK的使用,实现语音识别功能
科大讯飞语音听写SDK的使用,实现语音识别功能
事先说明:
语音听写SDK适配安卓6.0需要手动申请权限,各位可以自信查询资料实现,如果嫌麻烦,可以用第三方Bmob集成好的工具类进行实现,详细可以看http://blog.csdn.net/qq_30379689/article/details/52223244,关于语音听写SDK的开发,参考科大讯飞开放平台官网为准
步骤一:百度科大讯飞开发者平台,找到官网进入

步骤二:在科大讯飞开发者平台官网注册账号,并创建应用
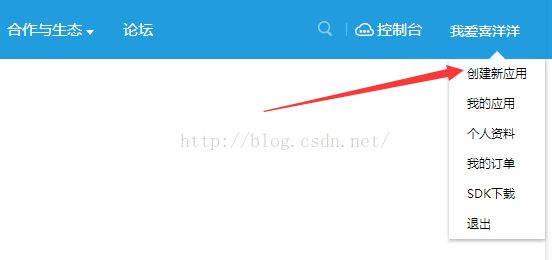
步骤三:在SDK下载中下载语音听写、Android平台、我的应用进行下载

步骤四:解压下载包,在libs中对应导入Android Studio中
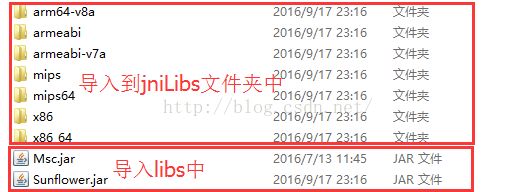
你需要在Android Studio中手动创建一个jniLibs文件夹,记得libs的jar包右键Add As Library
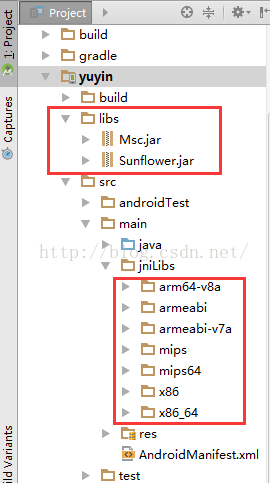
步骤五:复制assets文件夹到项目中
步骤六:根据需求,在Manifests文件中添加权限
<!--连接网络权限,用于执行云端语音能力 -->
<uses-permission android:name="android.permission.INTERNET" />
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO" />
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE" />
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
<!--读取联系人权限,上传联系人需要用到此权限 -->
<uses-permission android:name="android.permission.READ_CONTACTS" />
<!--外存储写权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<!--外存储读权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" />
<!--配置权限,用来记录应用配置信息 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS" />
<!--手机定位信息,用来为语义等功能提供定位,提供更精准的服务--> <!--定位信息是敏感信息,可通过Setting.setLocationEnable(false)关闭定位请求 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
这个步骤有时候会出错,因为如果是文档中复制进来的权限,会在权限中多出几个空格导致报错,所以大家小心
步骤七:在代码中初始化SDK
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 将“12345678”替换成您申请的 APPID
SpeechUtility.createUtility(this, SpeechConstant.APPID +"=12345678");
}
/**
* 初始化语音识别
*/
public void initSpeech(final Context context) {
//1.创建RecognizerDialog对象
RecognizerDialog mDialog = new RecognizerDialog(context, null);
//2.设置accent、language等参数
mDialog.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
mDialog.setParameter(SpeechConstant.ACCENT, "mandarin");
//3.设置回调接口
mDialog.setListener(new RecognizerDialogListener() {
@Override
public void onResult(RecognizerResult recognizerResult, boolean isLast) {
if (!isLast) {
//解析语音
String result = parseVoice(recognizerResult.getResultString());
}
}
@Override
public void onError(SpeechError speechError) {
}
});
//4.显示dialog,接收语音输入
mDialog.show();
}
/**
* 解析语音json
*/
public String parseVoice(String resultString) {
Gson gson = new Gson();
Voice voiceBean = gson.fromJson(resultString, Voice.class);
StringBuffer sb = new StringBuffer();
ArrayList<Voice.WSBean> ws = voiceBean.ws;
for (Voice.WSBean wsBean : ws) {
String word = wsBean.cw.get(0).w;
sb.append(word);
}
return sb.toString();
}
/**
* 语音对象封装
*/
public class Voice {
public ArrayList<WSBean> ws;
public class WSBean {
public ArrayList<CWBean> cw;
}
public class CWBean {
public String w;
}
}
由于语音识别返回的是个JSON数据,所以这里我们使用Gson这个包进行解析,需要在dependencies中添加
compile 'com.google.code.gson:gson:2.2.4'


源码下载:使用Import Module导入