基于Hadoop生态圈的数据仓库实践 —— 进阶技术(五)
五、快照
前面实验说明了处理维度的扩展。本节讨论两种事实表的扩展技术。
有些用户,尤其是管理者,经常要看某个特定时间点的数据。也就是说,他们需要数据的快照。周期快照和累积快照是两种常用的事实表扩展技术。
周期快照是在一个给定的时间对事实表进行一段时期的总计。例如,一个月销售订单周期快照汇总每个月底时总的销售订单金额。
累积快照用于跟踪事实表的变化。例如,数据仓库可能需要累积(存储)销售订单从下订单的时间开始,到订单中的商品被打包、运输和到达的各阶段的时间点数据来跟踪订单生命周期的进展情况。用户可能要取得在某个给定时间点,销售订单处理状态的累积快照。
下面说明周期快照和累积快照的细节问题。
1. 周期快照
下面以销售订单的月底汇总为例说明如何实现一个周期快照。
首先需要添加一个新的事实表。下图中的模式显示了一个名为month_end_sales_order_fact的新事实表。
该表中有两个度量值,month_order_amount和month_order_quantity。这两个值是不能加到sales_order_fact表中的,原因是,sales_order_fact表和新的度量值有不同的时间属性(数据的粒度不同)。sales_order_fact表包含的是每天一条记录。新的度量值要的是每月的数据。使用下面的脚本建立month_end_sales_order_fact表。
(1)修改工作流作业配置文件
修改后的workflow.xml文件内容如下:
(2)修改协调作业配置文件
修改后的coordinator.xml文件内容如下:
(3)修改协调作业属性文件
修改后的job-coord.properties文件内容如下:
(4)部署工作流和协调作业
(5)运行协调作业进行测试
到了9点半工作流开始运行,等执行完全成功后,month_end_sales_order_fact表中有了2016年6月销售订单汇总的两条数据,如下图所示。
 order_month_sk的值为198,使用下面的查询可以确认对应的年月是2016年6月。
order_month_sk的值为198,使用下面的查询可以确认对应的年月是2016年6月。
2. 累积快照
本小节说明如何在销售订单上实现累积快照。
该累加快照跟踪五个销售订单的里程碑:下订单、分配库房、打包、配送和收货。这五个里程碑的日期及其各自的数量来自源数据库的销售订单表。一个订单完整的生命周期由五行描述:下订单的时间一行,订单商品被分配到库房的时间一行,产品打包的时间一行,订单配送的时间一行,订单客户收货的时间一行。每个里程碑各有一个状态:N为新订单,A为已分配库房,P为已打包,S为已配送,R为已收货。源数据库的sales_order表结构必须做相应的改变,以处理五种不同的状态。
(1)修改数据库模式
执行下面的脚本修改数据库模式。
对源数据库的修改如下:把order_date列改名为status_date,添加了名为order_status的列,并把order_quantity列改名为quantity。正如名字所表示的,order_status列用于存储N,A,P,S或R之一。它描述了status_date列对应的状态值。如果一条记录的状态为N,则status_date列是下订单的日期。如果状态是R,status_date列是收货日期。对数据仓库的修改如下:给现有的sales_order_fact表添加四个数量和四个日期代理键,要加的新列是allocate_date_sk、allocate_quantity、packing_date_sk、packing_quantity、ship_date_sk、ship_quantity、receive_date_sk、receive_quantity。还要在日期维度上使用数据库视图角色扮演生成四个新的日期代理键。
(2)重建Sqoop作业
使用下面的脚本重建Sqoop作业,因为源表会有多个相同的order_number,所以不能再用它作为检查字段,将检查字段改为id
(3)修改定期装载regular_etl.sql文件
需要依据数据库模式修改定期装载的HiveQL脚本,修改后的脚本如下所示。
3. 测试
(1)新增两个销售订单
(2)设置cdc_time的日期
(3)执行定期装载脚本
(4)查询sales_order_fact表里的两个销售订单,确认定期装载成功

(5)添加销售订单作为这两个订单的分配库房和/或打包的里程碑
(6)修改cdc_time的日期
(7)执行定期装载脚本
(8)查询sales_order_fact表里的两个销售订单,确认定期装载成功

(9)添加销售订单作为这两个订单后面的里程碑:打包、配送和/或收货。注意四个日期可能相同。
(10)修改cdc_time的日期
(11)执行定期装载脚本
(12)查询sales_order_fact表里的两个销售订单,确认定期装载成功

(13)还原
将regular_etl.sql文件中的SET hivevar:cur_date = DATE_ADD(CURRENT_DATE(),2);行改为SET hivevar:cur_date = CURRENT_DATE();
前面实验说明了处理维度的扩展。本节讨论两种事实表的扩展技术。
有些用户,尤其是管理者,经常要看某个特定时间点的数据。也就是说,他们需要数据的快照。周期快照和累积快照是两种常用的事实表扩展技术。
周期快照是在一个给定的时间对事实表进行一段时期的总计。例如,一个月销售订单周期快照汇总每个月底时总的销售订单金额。
累积快照用于跟踪事实表的变化。例如,数据仓库可能需要累积(存储)销售订单从下订单的时间开始,到订单中的商品被打包、运输和到达的各阶段的时间点数据来跟踪订单生命周期的进展情况。用户可能要取得在某个给定时间点,销售订单处理状态的累积快照。
下面说明周期快照和累积快照的细节问题。
1. 周期快照
下面以销售订单的月底汇总为例说明如何实现一个周期快照。
首先需要添加一个新的事实表。下图中的模式显示了一个名为month_end_sales_order_fact的新事实表。
USE dw;
CREATE TABLE month_end_sales_order_fact (
order_month_sk INT COMMENT 'order month surrogate key',
product_sk INT COMMENT 'product surrogate key',
month_order_amount DECIMAL(10,2) COMMENT 'month order amount',
month_order_quantity INT COMMENT 'month order quantity'
)
CLUSTERED BY (order_month_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true'); 建立了month_end_sales_order_fact表后,现在需要向表中装载数据。月底销售订单事实表的数据源是已有的销售订单事实表。month_sum.sql文件用于装载月底销售订单事实表,该文件内容如下。
-- 设置变量以支持事务
set hive.support.concurrency=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on=true;
set hive.compactor.worker.threads=1;
USE dw;
SET hivevar:pre_month_date = add_months(current_date,-1);
delete from month_end_sales_order_fact
where month_end_sales_order_fact.order_month_sk in
(select month_sk
from month_dim
where month = month(${hivevar:pre_month_date})
and year = year(${hivevar:pre_month_date}));
insert into month_end_sales_order_fact
select b.month_sk, a.product_sk, sum(order_amount), sum(order_quantity)
from sales_order_fact a,
month_dim b,
order_date_dim d -- 视图
where a.order_date_sk = d.order_date_sk
and b.month = d.month
and b.year = d.year
and b.month = month(${hivevar:pre_month_date})
and b.year = year(${hivevar:pre_month_date})
group by b.month_sk, a.product_sk ; 每个月第一天,在每天销售订单定期装载执行完后,执行此脚本,装载上个月的销售订单数据。为此需要修改Oozie的工作流定义。
(1)修改工作流作业配置文件
修改后的workflow.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.1" name="regular_etl">
<start to="fork-node"/>
<fork name="fork-node">
<path start="sqoop-customer" />
<path start="sqoop-product" />
<path start="sqoop-sales_order" />
</fork>
<action name="sqoop-customer">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<arg>import</arg>
<arg>--connect</arg>
<arg>jdbc:mysql://cdh1:3306/source?useSSL=false</arg>
<arg>--username</arg>
<arg>root</arg>
<arg>--password</arg>
<arg>mypassword</arg>
<arg>--table</arg>
<arg>customer</arg>
<arg>--hive-import</arg>
<arg>--hive-table</arg>
<arg>rds.customer</arg>
<arg>--hive-overwrite</arg>
<file>/tmp/hive-site.xml#hive-site.xml</file>
<archive>/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar</archive>
</sqoop>
<ok to="joining"/>
<error to="fail"/>
</action>
<action name="sqoop-product">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<arg>import</arg>
<arg>--connect</arg>
<arg>jdbc:mysql://cdh1:3306/source?useSSL=false</arg>
<arg>--username</arg>
<arg>root</arg>
<arg>--password</arg>
<arg>mypassword</arg>
<arg>--table</arg>
<arg>product</arg>
<arg>--hive-import</arg>
<arg>--hive-table</arg>
<arg>rds.product</arg>
<arg>--hive-overwrite</arg>
<file>/tmp/hive-site.xml#hive-site.xml</file>
<archive>/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar</archive>
</sqoop>
<ok to="joining"/>
<error to="fail"/>
</action>
<action name="sqoop-sales_order">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<command>job --exec myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop</command>
<file>/tmp/hive-site.xml#hive-site.xml</file>
<archive>/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar</archive>
</sqoop>
<ok to="joining"/>
<error to="fail"/>
</action>
<join name="joining" to="hive-node"/>
<action name="hive-node">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<job-xml>/tmp/hive-site.xml</job-xml>
<script>/tmp/regular_etl.sql</script>
</hive>
<ok to="decision-node"/>
<error to="fail"/>
</action>
<decision name="decision-node">
<switch>
<case to="month-sum">
${date eq 20}
</case>
<default to="end"/>
</switch>
</decision>
<action name="month-sum">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<job-xml>/tmp/hive-site.xml</job-xml>
<script>/tmp/month_sum.sql</script>
</hive>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
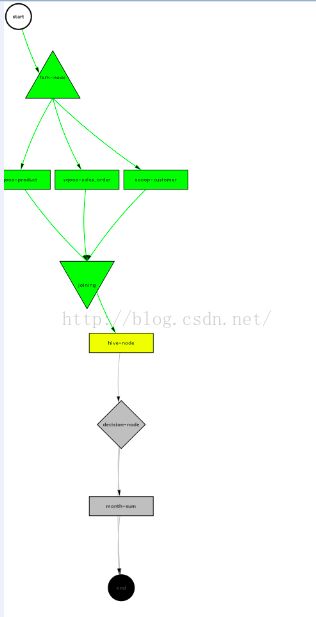
</workflow-app> 在该文件中增加了一个decision-node,当date参数的值等于20时,执行month_sum.sql文件后结束,否则直接结束。之所以这里是20是为了测试。month_sum.sql文件中用的是add_months(current_date,-1)取上个月的年月,因此不必要非得1号执行,任何一天都可以。这个工作流保证了每月汇总只有在每天汇总执行完后才执行,并且每月只执行一次。工作流DAG如下图所示。
(2)修改协调作业配置文件
修改后的coordinator.xml文件内容如下:
<coordinator-app name="regular_etl-coord" frequency="${coord:days(1)}" start="${start}" end="${end}" timezone="${timezone}" xmlns="uri
:oozie:coordinator:0.1">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
<property>
<name>date</name>
<value>${date}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app> 在该文件中增加了一个date属性,用于向workflow.xml文件传递date参数的值。
(3)修改协调作业属性文件
修改后的job-coord.properties文件内容如下:
nameNode=hdfs://cdh2:8020
jobTracker=cdh2:8032
queueName=default
oozie.use.system.libpath=true
oozie.coord.application.path=${nameNode}/user/${user.name}
timezone=UTC
start=2016-07-20T01:30Z
end=2020-12-31T01:30Z
workflowAppUri=${nameNode}/user/${user.name} 该文件中只修改了start和end属性的值以用于测试。
(4)部署工作流和协调作业
hdfs dfs -put -f coordinator.xml /user/root/ hdfs dfs -put -f /root/workflow.xml /user/root/ hdfs dfs -put -f /etc/hive/conf.cloudera.hive/hive-site.xml /tmp/ hdfs dfs -put -f /root/mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /tmp/ hdfs dfs -put -f /root/regular_etl.sql /tmp/ hdfs dfs -put -f /root/month_sum.sql /tmp/
(5)运行协调作业进行测试
oozie job -oozie http://cdh2:11000/oozie -config /root/job-coord.properties -run -D date=`date +"%d"`通过命令行的-D参数传递date属性的值,date为当前日期数,执行时是20号。
到了9点半工作流开始运行,等执行完全成功后,month_end_sales_order_fact表中有了2016年6月销售订单汇总的两条数据,如下图所示。
select year,month from month_dim where month_sk=198;
2. 累积快照
本小节说明如何在销售订单上实现累积快照。
该累加快照跟踪五个销售订单的里程碑:下订单、分配库房、打包、配送和收货。这五个里程碑的日期及其各自的数量来自源数据库的销售订单表。一个订单完整的生命周期由五行描述:下订单的时间一行,订单商品被分配到库房的时间一行,产品打包的时间一行,订单配送的时间一行,订单客户收货的时间一行。每个里程碑各有一个状态:N为新订单,A为已分配库房,P为已打包,S为已配送,R为已收货。源数据库的sales_order表结构必须做相应的改变,以处理五种不同的状态。
(1)修改数据库模式
执行下面的脚本修改数据库模式。
-- MySQL
USE source;
-- 修改销售订单事务表
ALTER TABLE sales_order
CHANGE order_date status_date datetime
, ADD order_status VARCHAR(1) AFTER status_date
, CHANGE order_quantity quantity INT;
-- 删除sales_order表的主键
alter table sales_order change order_number order_number int not null;
alter table sales_order drop primary key;
-- 建立新的主键
alter table sales_order add id int unsigned not null auto_increment primary key comment '主键' first;
-- Hive
-- rds.sales_order并没有增加id列,原因有两个:
-- 1. 该列只作为增量检查列,不用存储
-- 2. 不用再重新导入所有数据
use rds;
alter table sales_order
change order_date status_date timestamp comment 'status date';
alter table sales_order
change order_quantity quantity int comment 'quantity';
alter table sales_order
add columns (order_status varchar(1) comment 'order status');
USE dw;
-- 事实表增加八列
alter table sales_order_fact rename to sales_order_fact_old;
create table sales_order_fact
(
order_sk int comment 'order surrogate key',
customer_sk int comment 'customer surrogate key',
product_sk int comment 'product surrogate key',
order_date_sk int comment 'order date surrogate key',
allocate_date_sk int comment 'allocate date surrogate key',
allocate_quantity int comment 'allocate quantity',
packing_date_sk int comment 'packing date surrogate key',
packing_quantity int comment 'packing quantity',
ship_date_sk int comment 'ship date surrogate key',
ship_quantity int comment 'ship quantity',
receive_date_sk int comment 'receive date surrogate key',
receive_quantity int comment 'receive quantity',
request_delivery_date_sk int comment 'request delivery date surrogate key',
order_amount decimal(10,2) comment 'order amount',
order_quantity int comment 'order quantity'
)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
insert into sales_order_fact
select order_sk,
customer_sk,
product_sk,
order_date_sk,
null,
null,
null,
null,
null,
null,
null,
null,
request_delivery_date_sk,
order_amount,
order_quantity
from sales_order_fact_old;
drop table sales_order_fact_old;
-- 建立四个日期维度视图
CREATE VIEW allocate_date_dim (allocate_date_sk, allocate_date, month, month_name, quarter, year, promo_ind)
AS
SELECT date_sk,
date,
month,
month_name,
quarter,
year,
promo_ind
FROM date_dim ;
CREATE VIEW packing_date_dim (packing_date_sk, packing_date, month, month_name, quarter, year, promo_ind)
AS
SELECT date_sk,
date,
month,
month_name,
quarter,
year,
promo_ind
FROM date_dim ;
CREATE VIEW ship_date_dim (ship_date_sk, ship_date, month, month_name, quarter, year, promo_ind)
AS
SELECT date_sk,
date,
month,
month_name,
quarter,
year,
promo_ind
FROM date_dim ;
CREATE VIEW receive_date_dim (receive_date_sk, receive_date, month, month_name, quarter, year, promo_ind)
AS
SELECT date_sk,
date,
month,
month_name,
quarter,
year,
promo_ind
FROM date_dim ; 修改后的数据仓库模式如下图所示。
(2)重建Sqoop作业
使用下面的脚本重建Sqoop作业,因为源表会有多个相同的order_number,所以不能再用它作为检查字段,将检查字段改为id
last_value=`sqoop job --show myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop | grep incremental.last.value | awk '{print $3}'`
sqoop job --delete myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop
sqoop job \
--meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop \
--create myjob_incremental_import \
-- \
import \
--connect "jdbc:mysql://cdh1:3306/source?useSSL=false&user=root&password=mypassword" \
--table sales_order \
--columns "order_number, customer_number, product_code, status_date, entry_date, order_amount, quantity, request_delivery_date, order_status" \
--hive-import \
--hive-table rds.sales_order \
--incremental append \
--check-column id \
--last-value $last_value
(3)修改定期装载regular_etl.sql文件
需要依据数据库模式修改定期装载的HiveQL脚本,修改后的脚本如下所示。
-- 设置变量以支持事务
set hive.support.concurrency=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on=true;
set hive.compactor.worker.threads=1;
USE dw;
-- 设置SCD的生效时间和过期时间
SET hivevar:cur_date = CURRENT_DATE();
SET hivevar:pre_date = DATE_ADD(${hivevar:cur_date},-1);
SET hivevar:max_date = CAST('2200-01-01' AS DATE);
-- 设置CDC的上限时间
INSERT OVERWRITE TABLE rds.cdc_time SELECT last_load, ${hivevar:cur_date} FROM rds.cdc_time;
-- 装载customer维度
-- 设置已删除记录和地址相关列上SCD2的过期,用<=>运算符处理NULL值。
UPDATE customer_dim
SET expiry_date = ${hivevar:pre_date}
WHERE customer_dim.customer_sk IN
(SELECT a.customer_sk
FROM (SELECT customer_sk,
customer_number,
customer_street_address,
customer_zip_code,
customer_city,
customer_state,
shipping_address,
shipping_zip_code,
shipping_city,
shipping_state
FROM customer_dim WHERE expiry_date = ${hivevar:max_date}) a LEFT JOIN
rds.customer b ON a.customer_number = b.customer_number
WHERE b.customer_number IS NULL OR
( !(a.customer_street_address <=> b.customer_street_address)
OR !(a.customer_zip_code <=> b.customer_zip_code)
OR !(a.customer_city <=> b.customer_city)
OR !(a.customer_state <=> b.customer_state)
OR !(a.shipping_address <=> b.shipping_address)
OR !(a.shipping_zip_code <=> b.shipping_zip_code)
OR !(a.shipping_city <=> b.shipping_city)
OR !(a.shipping_state <=> b.shipping_state)
));
-- 处理customer_street_addresses列上SCD2的新增行
INSERT INTO customer_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.shipping_address,
t1.shipping_zip_code,
t1.shipping_city,
t1.shipping_state,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
t2.customer_number customer_number,
t2.customer_name customer_name,
t2.customer_street_address customer_street_address,
t2.customer_zip_code customer_zip_code,
t2.customer_city customer_city,
t2.customer_state customer_state,
t2.shipping_address shipping_address,
t2.shipping_zip_code shipping_zip_code,
t2.shipping_city shipping_city,
t2.shipping_state shipping_state,
t1.version + 1 version,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM customer_dim t1
INNER JOIN rds.customer t2
ON t1.customer_number = t2.customer_number
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN customer_dim t3
ON t1.customer_number = t3.customer_number
AND t3.expiry_date = ${hivevar:max_date}
WHERE (!(t1.customer_street_address <=> t2.customer_street_address)
OR !(t1.customer_zip_code <=> t2.customer_zip_code)
OR !(t1.customer_city <=> t2.customer_city)
OR !(t1.customer_state <=> t2.customer_state)
OR !(t1.shipping_address <=> t2.shipping_address)
OR !(t1.shipping_zip_code <=> t2.shipping_zip_code)
OR !(t1.shipping_city <=> t2.shipping_city)
OR !(t1.shipping_state <=> t2.shipping_state)
)
AND t3.customer_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(customer_sk),0) sk_max FROM customer_dim) t2;
-- 处理customer_name列上的SCD1
-- 因为hive的update的set子句还不支持子查询,所以这里使用了一个临时表存储需要更新的记录,用先delete再insert代替update
-- 因为SCD1本身就不保存历史数据,所以这里更新维度表里的所有customer_name改变的记录,而不是仅仅更新当前版本的记录
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
SELECT
a.customer_sk,
a.customer_number,
b.customer_name,
a.customer_street_address,
a.customer_zip_code,
a.customer_city,
a.customer_state,
a.shipping_address,
a.shipping_zip_code,
a.shipping_city,
a.shipping_state,
a.version,
a.effective_date,
a.expiry_date
FROM customer_dim a, rds.customer b
WHERE a.customer_number = b.customer_number AND !(a.customer_name <=> b.customer_name);
DELETE FROM customer_dim WHERE customer_dim.customer_sk IN (SELECT customer_sk FROM tmp);
INSERT INTO customer_dim SELECT * FROM tmp;
-- 处理新增的customer记录
INSERT INTO customer_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.shipping_address,
t1.shipping_zip_code,
t1.shipping_city,
t1.shipping_state,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM
(
SELECT t1.* FROM rds.customer t1 LEFT JOIN customer_dim t2 ON t1.customer_number = t2.customer_number
WHERE t2.customer_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(customer_sk),0) sk_max FROM customer_dim) t2;
-- 重载PA客户维度
TRUNCATE TABLE pa_customer_dim;
INSERT INTO pa_customer_dim
SELECT
customer_sk
, customer_number
, customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
, shipping_address
, shipping_zip_code
, shipping_city
, shipping_state
, version
, effective_date
, expiry_date
FROM customer_dim
WHERE customer_state = 'PA' ;
-- 装载product维度
-- 设置已删除记录和product_name、product_category列上SCD2的过期
UPDATE product_dim
SET expiry_date = ${hivevar:pre_date}
WHERE product_dim.product_sk IN
(SELECT a.product_sk
FROM (SELECT product_sk,product_code,product_name,product_category
FROM product_dim WHERE expiry_date = ${hivevar:max_date}) a LEFT JOIN
rds.product b ON a.product_code = b.product_code
WHERE b.product_code IS NULL OR (a.product_name <> b.product_name OR a.product_category <> b.product_category));
-- 处理product_name、product_category列上SCD2的新增行
INSERT INTO product_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
t2.product_code product_code,
t2.product_name product_name,
t2.product_category product_category,
t1.version + 1 version,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM product_dim t1
INNER JOIN rds.product t2
ON t1.product_code = t2.product_code
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN product_dim t3
ON t1.product_code = t3.product_code
AND t3.expiry_date = ${hivevar:max_date}
WHERE (t1.product_name <> t2.product_name OR t1.product_category <> t2.product_category) AND t3.product_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(product_sk),0) sk_max FROM product_dim) t2;
-- 处理新增的product记录
INSERT INTO product_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM
(
SELECT t1.* FROM rds.product t1 LEFT JOIN product_dim t2 ON t1.product_code = t2.product_code
WHERE t2.product_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(product_sk),0) sk_max FROM product_dim) t2;
-- 装载order维度,
-- 前一天新增的销售订单号
INSERT INTO order_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.order_number) + t2.sk_max,
t1.order_number,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
order_number order_number,
1 version,
status_date effective_date,
'2200-01-01' expiry_date
FROM rds.sales_order, rds.cdc_time
WHERE order_status = 'N' AND entry_date >= last_load AND entry_date < current_load ) t1
CROSS JOIN
(SELECT COALESCE(MAX(order_sk),0) sk_max FROM order_dim) t2;
-- 装载销售订单事实表
-- 前一天新增的销售订单
INSERT INTO sales_order_fact
SELECT
order_sk,
customer_sk,
product_sk,
e.order_date_sk,
null,
null,
null,
null,
null,
null,
null,
null,
f.request_delivery_date_sk,
order_amount,
quantity
FROM
rds.sales_order a,
order_dim b,
customer_dim c,
product_dim d,
order_date_dim e,
request_delivery_date_dim f,
rds.cdc_time g
WHERE
a.order_status = 'N'
AND a.order_number = b.order_number
AND a.customer_number = c.customer_number
AND a.status_date >= c.effective_date
AND a.status_date < c.expiry_date
AND a.product_code = d.product_code
AND a.status_date >= d.effective_date
AND a.status_date < d.expiry_date
AND to_date(a.status_date) = e.order_date
AND to_date(a.request_delivery_date) = f.request_delivery_date
AND a.entry_date >= g.last_load AND a.entry_date < g.current_load ;
-- 处理分配库房、打包、配送和收货四个状态
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
select t0.order_sk order_sk,
t0.customer_sk customer_sk,
t0.product_sk product_sk,
t0.order_date_sk order_date_sk,
t2.allocate_date_sk allocate_date_sk,
t1.quantity allocate_quantity,
t0.packing_date_sk packing_date_sk,
t0.packing_quantity packing_quantity,
t0.ship_date_sk ship_date_sk,
t0.ship_quantity ship_quantity,
t0.receive_date_sk receive_date_sk,
t0.receive_quantity receive_quantity,
t0.request_delivery_date_sk request_delivery_date_sk,
t0.order_amount order_amount,
t0.order_quantity order_quantity
from sales_order_fact t0,
rds.sales_order t1,
allocate_date_dim t2,
order_dim t3,
rds.cdc_time t4
where t0.order_sk = t3.order_sk
and t3.order_number = t1.order_number and t1.order_status = 'A'
and to_date(t1.status_date) = t2.allocate_date
and t1.entry_date >= t4.last_load and t1.entry_date < t4.current_load;
DELETE FROM sales_order_fact WHERE sales_order_fact.order_sk IN (SELECT order_sk FROM tmp);
INSERT INTO sales_order_fact SELECT * FROM tmp;
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
select t0.order_sk order_sk,
t0.customer_sk customer_sk,
t0.product_sk product_sk,
t0.order_date_sk order_date_sk,
t0.allocate_date_sk allocate_date_sk,
t0.allocate_quantity allocate_quantity,
t2.packing_date_sk packing_date_sk,
t1.quantity packing_quantity,
t0.ship_date_sk ship_date_sk,
t0.ship_quantity ship_quantity,
t0.receive_date_sk receive_date_sk,
t0.receive_quantity receive_quantity,
t0.request_delivery_date_sk request_delivery_date_sk,
t0.order_amount order_amount,
t0.order_quantity order_quantity
from sales_order_fact t0,
rds.sales_order t1,
packing_date_dim t2,
order_dim t3,
rds.cdc_time t4
where t0.order_sk = t3.order_sk
and t3.order_number = t1.order_number and t1.order_status = 'P'
and to_date(t1.status_date) = t2.packing_date
and t1.entry_date >= t4.last_load and t1.entry_date < t4.current_load;
DELETE FROM sales_order_fact WHERE sales_order_fact.order_sk IN (SELECT order_sk FROM tmp);
INSERT INTO sales_order_fact SELECT * FROM tmp;
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
select t0.order_sk order_sk,
t0.customer_sk customer_sk,
t0.product_sk product_sk,
t0.order_date_sk order_date_sk,
t0.allocate_date_sk allocate_date_sk,
t0.allocate_quantity allocate_quantity,
t0.packing_date_sk packing_date_sk,
t0.packing_quantity packing_quantity,
t2.ship_date_sk ship_date_sk,
t1.quantity ship_quantity,
t0.receive_date_sk receive_date_sk,
t0.receive_quantity receive_quantity,
t0.request_delivery_date_sk request_delivery_date_sk,
t0.order_amount order_amount,
t0.order_quantity order_quantity
from sales_order_fact t0,
rds.sales_order t1,
ship_date_dim t2,
order_dim t3,
rds.cdc_time t4
where t0.order_sk = t3.order_sk
and t3.order_number = t1.order_number and t1.order_status = 'S'
and to_date(t1.status_date) = t2.ship_date
and t1.entry_date >= t4.last_load and t1.entry_date < t4.current_load;
DELETE FROM sales_order_fact WHERE sales_order_fact.order_sk IN (SELECT order_sk FROM tmp);
INSERT INTO sales_order_fact SELECT * FROM tmp;
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
select t0.order_sk order_sk,
t0.customer_sk customer_sk,
t0.product_sk product_sk,
t0.order_date_sk order_date_sk,
t0.allocate_date_sk allocate_date_sk,
t0.allocate_quantity allocate_quantity,
t0.packing_date_sk packing_date_sk,
t0.packing_quantity packing_quantity,
t0.ship_date_sk ship_date_sk,
t0.ship_quantity ship_quantity,
t2.receive_date_sk receive_date_sk,
t1.quantity receive_quantity,
t0.request_delivery_date_sk request_delivery_date_sk,
t0.order_amount order_amount,
t0.order_quantity order_quantity
from sales_order_fact t0,
rds.sales_order t1,
receive_date_dim t2,
order_dim t3,
rds.cdc_time t4
where t0.order_sk = t3.order_sk
and t3.order_number = t1.order_number and t1.order_status = 'R'
and to_date(t1.status_date) = t2.receive_date
and t1.entry_date >= t4.last_load and t1.entry_date < t4.current_load;
DELETE FROM sales_order_fact WHERE sales_order_fact.order_sk IN (SELECT order_sk FROM tmp);
INSERT INTO sales_order_fact SELECT * FROM tmp;
-- 更新时间戳表的last_load字段
INSERT OVERWRITE TABLE rds.cdc_time SELECT current_load, current_load FROM rds.cdc_time;
3. 测试
(1)新增两个销售订单
USE source;
/***
新增订单日期为2016年7月20日的2条订单。
***/
SET @start_date := unix_timestamp('2016-07-20');
SET @end_date := unix_timestamp('2016-07-21');
SET @request_delivery_date := '2016-07-25';
DROP TABLE IF EXISTS temp_sales_order_data;
CREATE TABLE temp_sales_order_data AS SELECT * FROM sales_order WHERE 1=0;
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (1, 1, 1, 1, @order_date, 'N', @request_delivery_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (2, 2, 2, 2, @order_date, 'N', @request_delivery_date, @order_date, @amount, @quantity);
INSERT INTO sales_order
select null,
(@order_number:=@order_number + 1) + 128,
customer_number,
product_code,
status_date,
order_status,
request_delivery_date,
entry_date,
order_amount,
quantity
from temp_sales_order_data t1,(select @order_number:=0) t2
order by t1.status_date;
COMMIT ;
(2)设置cdc_time的日期
use rds; INSERT OVERWRITE TABLE rds.cdc_time SELECT '2016-07-20', '2016-07-21' FROM rds.cdc_time;将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-21';
(3)执行定期装载脚本
./regular_etl.sh
(4)查询sales_order_fact表里的两个销售订单,确认定期装载成功
use dw;
select b.order_number,
c.order_date,
d.allocate_date,
e.packing_date,
f.ship_date,
g.receive_date
from sales_order_fact a
inner join order_dim b on a.order_sk = b.order_sk
left join order_date_dim c on a.order_date_sk = c.order_date_sk
left join allocate_date_dim d on a.allocate_date_sk = d.allocate_date_sk
left join packing_date_dim e on a.packing_date_sk = e.packing_date_sk
left join ship_date_dim f on a.ship_date_sk = f.ship_date_sk
left join receive_date_dim g on a.receive_date_sk = g.receive_date_sk
where b.order_number IN (129 , 130); 查询结果如下图所示,只有order_date列有值,其它日期都是NULL,因为这两个订单是新增的,并且还没有分配库房、打包、配送或收货。
(5)添加销售订单作为这两个订单的分配库房和/或打包的里程碑
USE source;
SET @start_date := unix_timestamp('2016-07-21');
SET @end_date := unix_timestamp('2016-07-22');
SET @mid_date := unix_timestamp('2016-07-21 12:00:00');
SET @request_delivery_date := '2016-07-25';
DROP TABLE IF EXISTS temp_sales_order_data;
CREATE TABLE temp_sales_order_data AS SELECT * FROM sales_order WHERE 1=0;
SET @order_date := from_unixtime(@start_date + rand() * (@mid_date - @start_date));
select order_amount,quantity into @amount,@quantity from sales_order where order_number=129;
INSERT INTO temp_sales_order_data VALUES (1, 129, 1, 1, @order_date, 'A', @request_delivery_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@mid_date + rand() * (@end_date - @mid_date));
INSERT INTO temp_sales_order_data VALUES (2, 129, 1, 1, @order_date, 'P', @request_delivery_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
select order_amount,quantity into @amount,@quantity from sales_order where order_number=130;
INSERT INTO temp_sales_order_data VALUES (3, 130, 2, 2, @order_date, 'A', @request_delivery_date, @order_date, @amount, @quantity);
INSERT INTO sales_order
select null,
order_number,
customer_number,
product_code,
status_date,
order_status,
request_delivery_date,
entry_date,
order_amount,
quantity
from temp_sales_order_data
order by entry_date;
COMMIT ;
(6)修改cdc_time的日期
use rds; INSERT OVERWRITE TABLE rds.cdc_time SELECT '2016-07-21', '2016-07-22' FROM rds.cdc_time;将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-22';
(7)执行定期装载脚本
./regular_etl.sh
(8)查询sales_order_fact表里的两个销售订单,确认定期装载成功
use dw;
select b.order_number,
c.order_date,
d.allocate_date,
e.packing_date,
f.ship_date,
g.receive_date
from sales_order_fact a
inner join order_dim b on a.order_sk = b.order_sk
left join order_date_dim c on a.order_date_sk = c.order_date_sk
left join allocate_date_dim d on a.allocate_date_sk = d.allocate_date_sk
left join packing_date_dim e on a.packing_date_sk = e.packing_date_sk
left join ship_date_dim f on a.ship_date_sk = f.ship_date_sk
left join receive_date_dim g on a.receive_date_sk = g.receive_date_sk
where b.order_number IN (129 , 130); 查询结果如下图所示。第一个订单具有了allocate_date和packing_date,第二个只具有allocate_date。
(9)添加销售订单作为这两个订单后面的里程碑:打包、配送和/或收货。注意四个日期可能相同。
USE source;
SET @start_date := unix_timestamp('2016-07-22');
SET @end_date := unix_timestamp('2016-07-23');
SET @mid_date := unix_timestamp('2016-07-22 12:00:00');
SET @request_delivery_date := '2016-07-25';
DROP TABLE IF EXISTS temp_sales_order_data;
CREATE TABLE temp_sales_order_data AS SELECT * FROM sales_order WHERE 1=0;
SET @order_date := from_unixtime(@start_date + rand() * (@mid_date - @start_date));
select order_amount,quantity into @amount,@quantity from sales_order where order_number=129 limit 1;
INSERT INTO temp_sales_order_data VALUES (1, 129, 1, 1, @order_date, 'S', @request_delivery_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@mid_date + rand() * (@end_date - @mid_date));
INSERT INTO temp_sales_order_data VALUES (2, 129, 1, 1, @order_date, 'R', @request_delivery_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
select order_amount,quantity into @amount,@quantity from sales_order where order_number=130 limit 1;
INSERT INTO temp_sales_order_data VALUES (3, 130, 2, 2, @order_date, 'P', @request_delivery_date, @order_date, @amount, @quantity);
INSERT INTO sales_order
select null,
order_number,
customer_number,
product_code,
status_date,
order_status,
request_delivery_date,
entry_date,
order_amount,
quantity
from temp_sales_order_data
order by entry_date;
COMMIT ;
(10)修改cdc_time的日期
use rds; INSERT OVERWRITE TABLE rds.cdc_time SELECT '2016-07-22', '2016-07-23' FROM rds.cdc_time;将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-23';
(11)执行定期装载脚本
./regular_etl.sh
(12)查询sales_order_fact表里的两个销售订单,确认定期装载成功
use dw;
select b.order_number,
c.order_date,
d.allocate_date,
e.packing_date,
f.ship_date,
g.receive_date
from sales_order_fact a
inner join order_dim b on a.order_sk = b.order_sk
left join order_date_dim c on a.order_date_sk = c.order_date_sk
left join allocate_date_dim d on a.allocate_date_sk = d.allocate_date_sk
left join packing_date_dim e on a.packing_date_sk = e.packing_date_sk
left join ship_date_dim f on a.ship_date_sk = f.ship_date_sk
left join receive_date_dim g on a.receive_date_sk = g.receive_date_sk
where b.order_number IN (129 , 130); 查询结果如下图所示。第一个订单号为129的订单,具有了全部日期,这意味着订单已完成(客户已经收货)。第二个订单已经打包,但是还没有配送。
(13)还原
将regular_etl.sql文件中的SET hivevar:cur_date = DATE_ADD(CURRENT_DATE(),2);行改为SET hivevar:cur_date = CURRENT_DATE();