SparkR数据分析
本文的运行环境是ubuntu,在阅读这篇文章前,请先保证你已经成功配置了Spark, 并设置好了全局变量 SPARK_HOME以及 PATH ,能够成功运行Spark.(如果你在终端输入sparkR 运行成功的话就证明你成功了)
如果还没有配置成功的话,参考这里,安装SPARK只需三步
1.下载示例数据
MovieLens 100k数据集
它包含了用户和电影信息,以及10万次用户对电影的评价,将其解压,后可以看到各个文件的形式如下:
$ head -5 u.user
1|24|M|technician|85711
2|53|F|other|94043
3|23|M|writer|32067
4|24|M|technician|43537
5|33|F|other|15213
$ head -5 u.item
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
2|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
3|Four Rooms (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Four%20Rooms%20(1995)|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
4|Get Shorty (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Get%20Shorty%20(1995)|0|1|0|0|0|1|0|0|1|0|0|0|0|0|0|0|0|0|0
5|Copycat (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Copycat%20(1995)|0|0|0|0|0|0|1|0|1|0|0|0|0|0|0|0|1|0|0
$ head -5 u.data
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
2. 通过Rstudio启动SparkR
请保证你的环境变量SPARK_HOME设置正确,如果你没有设好的话,在下面代码”你的spark的路径”处填上你的路径
if (nchar(Sys.getenv("SPARK_HOME")) < 1) {
Sys.setenv(SPARK_HOME = "你的spark的路径")
}
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sc <- sparkR.init(master = "local[*]", sparkEnvir = list(spark.driver.memory="2g"))
sqlContext <- sparkRSQL.init(sc)如果你看到类似以下这图的话,表示启动成功了.
3.简单的数据探索与可视化
先读取数据,这里为了方便起见,我直接用了r的函数读取了数据,然后再转换为Spark的DataFrame格式,一般使用SparkR读取数据的方法有从HIVE读取,或使用read.df函数读取.
> df<-read.table("/home/qj/Desktop/ml-100k/u.user",sep="|")
> userdata <- createDataFrame(sqlContext, df)
> names(userdata)<-c("id","age","gender","occupation","ZIPcode")
> head(userdata)
id age gender occupation ZIPcode
1 1 24 M technician 85711
2 2 53 F other 94043
3 3 23 M writer 32067
4 4 24 M technician 43537
5 5 33 F other 15213
6 6 42 M executive 98101
当然,我们也可以利用RDD API来导入数据,不过目前RDD API 并没有对外开放,所以使用这些函数时必须要加上SparkR:::
> lines<-SparkR:::textFile(sc,"/home/qj/Desktop/ml-100k/u.user")
> items<-SparkR:::map(lines,function(line){
strsplit(line,"[|]")[[1]]
})
> userdata<-createDataFrame(sqlContext, items)
> names(userdata)<-c("id","age","gender","occupation","ZIPcode")
> head(userdata)
id age gender occupation ZIPcode
1 1 24 M technician 85711
2 2 53 F other 94043
3 3 23 M writer 32067
4 4 24 M technician 43537
5 5 33 F other 15213
6 6 42 M executive 98101
对年龄进行分组统计其数量,看看用户的年龄分布,并使用ggplot2作出条形图
> ages<-collect(summarize(groupBy(userdata, userdata$age), count = n(userdata$age)))
> head(ages)
age count
1 31 25
2 32 28
3 33 26
4 34 17
5 35 27
6 36 21
> ggplot(ages,aes(x=age,y=count))+geom_bar(stat="identity")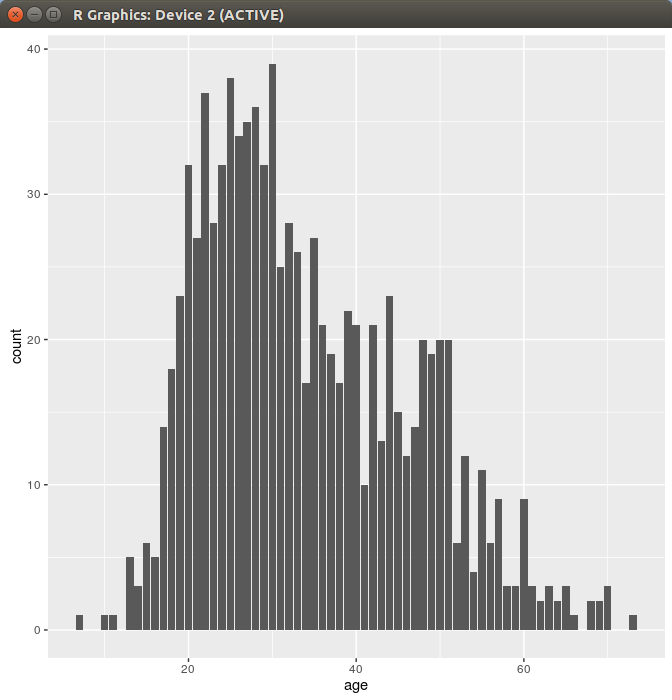
可以看到,用户的年龄主要集中在20到30岁之间.
进一步学习
- SparkR官方指南
- SparkR API文档
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者a358463121专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。