spark环境构建及示例
spark提供了三种集群模式:standalone、yarn以及Mesos,三种模式里面standalone模式是一个基础,本篇先从standalone模式讲解一个基础的spark集群搭建过程,并且基于这个集群我们再介绍一下spark-shell的使用、spark提供的例子如何运行,以及开发一个简单的例子通过任务提交的方式运行起来。
Spark集群搭建(standalone模式)
安装
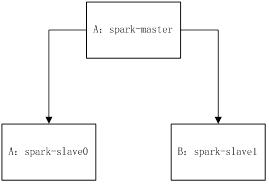
我们以两台机器作为集群搭建,其中spark-master作为master,同时也作为slave,名称为spark-slave0,另外一台机器作为slava,名称为spark-slave1,他们的网络架构如下图所示:
步骤1:进入spark官网下载bin安装包,http://spark.apache.org/downloads.html

步骤2:tar -xvf spark-2.0.1-bin-hadoop2.6
步骤3:cd ./spark-2.0.1-bin-hadoop2.6/conf
步骤4:cp slaves.template slaves
步骤5:cp spark-env.sh.template spark-env.sh
步骤6:修改启动环境变量脚本vim spark-env.sh,添加
export JAVA_HOME="/usr/local/java"
export SCALA_HOME="/usr/local/scala"
export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6"
export SPARK_MASTER_HOST=spark-master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
步骤7:修改slaves配置,vim slaves,添加
spark-slave0 spark-slave1
步骤8:系统环境变量配置(假设系统已安装jdk及scala),vim /etc/profile,添加
export JAVA_HOME="/usr/local/java" export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6" export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib
步骤9:source /etc/profile
步骤10:修改host配置 vim /etc/hosts 添加
A-host-ip spark-master A-host-ip spark-slave0 B-host-ip spark-slave1
注:此处请务必注意,A-host-ip一定要写的是A机器的IP,而不是127.0.0.1,如果是写了后者,master启动后会只监听本地回环地址127.0.0.1,而导致其他slave例如B机器连接被拒绝。
步骤11:B机器配置按照A机器配置完全一样复制一份即可。
配置ssh集群间无密登录
步骤1:确保A,B机器之间ping通
步骤2:关闭防火墙限制
2.1、重启后生效
开启: chkconfigiptables on
关闭: chkconfigiptables off
2.2、即时生效,重启后失效
开启: service iptablesstart
关闭: service iptables stop
步骤3:使用root用户在各个节点创建密钥对
[root@spark-slave0 ~]$ ssh-keygen -t rsa [root@spark-slave1 ~]$ ssh-keygen -t rsa 如下所示: [root@spark-slave0 conf]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): /root/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: c5:54:cf:ee:3b:43:19:9d:63:72:11:83:d5:84:b6:ad root@SIP1 The key's randomart image is: +--[ RSA 2048]----+ | ... o*+| | o +o.o| | o .o+o| | . oo=o| | S =+.| | .E | | .. | | o. | | .o | +-----------------+
这样执行之后就在/root/.ssh/目录下生成了一对ssh的公私钥。id_rsa 以及id_rsa.pub
步骤4:切换到spark-master节点合并节点公钥。
[[email protected]]$ ssh spark-slave1cat /root/.ssh/id_rsa.pub>>authorized_keys
[[email protected]]$ ssh spark-slave0cat /root/.ssh/id_rsa.pub>>authorized_keys
两台slave的公钥在master上合并完成。
注:本例采用的是root账号执行,如果你采用的是hadoop账号执行以上所有安装操作就需要修改authorized_keys文件的属性(.ssh目录为700,authorized_keys文件为600,用chmod命令修改),不然ssh登录的时候还需要密码。
步骤5:验证一下ssh无密是否成功:[root@spark-master .ssh]$ ssh spark-slave1 date
启动standalone集群
cd /data/spark-2.0.1-bin-hadoop2.6/sbin
./start-all.sh
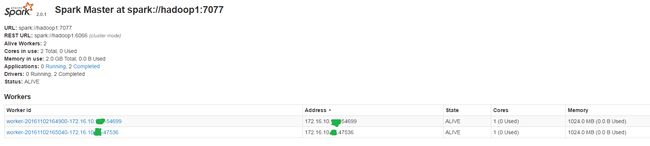
启动之后,master有一个webui界面,访问如下地址:http://A:8080如下
Spark-shell使用
Spark-shell提供了基于scala语言的脚本执行环境,在启动的时候会自动创建一个名为sc的sparkContext上下文,具体启动方式
cd /data/spark-2.0.1-bin-hadoop2.6/bin
./spark-shell
执行一条简单的数组各元素累加的scala命令

另外spark-shell还可以提交任务来允许,如下几种模式:
本地master4核运行
$ ./bin/spark-shell --master local[4]
添加jar包加载到classpath运行
$ ./bin/spark-shell --master local[4] --jars code.jar
还可以添加maven的dependency运行
$ ./bin/spark-shell --master local[4] --packages "org.example:example:0.1"
任务提交
我们首先编写一个RDD(spark的存储文件类型,后续章节我们重点介绍下RDD的结构)测试小程序,通过这个小程序打包jar提交到我们刚才搭建的环境中运行。Spark任务提交是通过spark-submit来提交的,一个典型的spark-submit的参数解释如下:
./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]
--class 要执行的类
--master sparkmaster的地址,一般的写法是spark://host:port
--deploy-model 部署模式集群执行cluster:集群各节点分布式运行client:本地运行
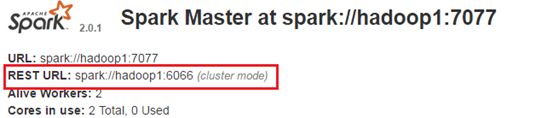
请注意cluster运行的时候master一定要写它的rest地址,这个可以再master的webui上查看具体地址。
--conf spark的配置参数,键值对形式
Application-jar 所需要运行的jar包路径
我们编写的小实例:
Pom.xml文件如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>spark.test</groupId> <artifactId>rdd</artifactId> <version>1.0</version> <dependencies> <dependency> <!-- Spark dependency --> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.1</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.10</artifactId> <version>1.6.1</version> <scope>provided</scope> </dependency> <dependency> <groupId>commons-cli</groupId> <artifactId>commons-cli</artifactId> <version>1.2</version> </dependency> </dependencies> </project>实现源码如下:
package rdd;
import java.util.Arrays;
import java.util.HashMap;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
/**
*
* @author flyking
*
*/
public class TestRDD {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("spark://master:port").setAppName("SimpleRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3 ,3), 2);
System.out.println("rdd collect" + rdd.collect());
System.out.println("rdd count" + rdd.count());
System.out.println("rdd countByValue" + rdd.countByValue());
System.out.println("rdd take" + rdd.take(2));
System.out.println("rdd top" + rdd.top(2));
System.out.println("rdd takeOrdered" + rdd.takeOrdered(2));
System.out.println("rdd map "+ rdd.map(new Function<Integer, HashMap<String,Integer>>() {
public HashMap<String,Integer> call(Integer v1) throws Exception {
return (HashMap<String, Integer>) new HashMap().put(String.valueOf(v1), v1);
}
}));
System.out.println("rdd reduce" + rdd.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}));
}
}
把文件上传到master服务器/data/rdd-1.0.jar,我们采取本地模式提交任务运行
cd /data/spark-2.0.1-bin-hadoop2.6/bin ./spark-submit --class rdd.TestRDD --master local[2] --executor-memory 2G --num-executors 5 /data/rdd-1.0.jar
运行后的结果如下:
rdd collect[1, 2, 3, 3]
rdd count4
rdd countByValue{2=1, 1=1, 3=2}
rdd take[1, 2]
rdd top[3, 3]
rdd takeOrdered[1, 2]
rdd map MapPartitionsRDD[6] at map at TestRDD.java:26
rdd reduce9