(大)数据处理:从txt到MySql的数据预处理迁徙
Python 2.7
IDE Pycharm 5.0.3
MySQL 5.7
MySQL Workbench 6.3
前言
学长毕业刚好在整大数据,从数据堂花了大价钱买的一个月的北京出租车GPS数据,一天大概11G,一个月就是350G左右,而且数据全部存在txt中,根本无法进行分析处理,而且重复数据非常多,这就需要把txt写到数据库中在进行操作了,于是,我尝试了自己的python。。。。。
猜一下数据
在没有拿到数据前,这是我从一篇博士论文上看到的数据样式:
ok,看起来应该很简单的样子,所以我模拟了一下前几行数据,当然,虽然那么几行,但是我也懒得敲在txt上啊,所以我机智的想到了图像识别pytesser模块,刚好在以前做验证码识别的时候用到过,所以直接拿来用咯,如何使用pytesser请看Python+Selenium+PIL+Tesseract真正自动识别验证码进行一键登录
准备食材
第一步,先把图像切割下,然后保存在工程路径下,就像这样

然后,识别图中的数字并打印!
import pytesser
code= pytesser.image_file_to_string("C:\Users\MrLevo\Desktop\cardata.jpg")#code即为识别出的图片数字str类型
print code当然,理想很丰满,现实太骨感,识别出个这么个玩意!
4S9309,4,1.20110701164753,11612693863,39,928S698,Z7,346,1
154s5s,4,1,20110701084818,115.5092316,39.7901344,15,58,1
49213s,4,1,20110701034811115 3o91025,4o.0215s27,2,2s4,0
035834,4,1,20l10701084811116 3768692,39.986Z785,l9,96,1
05s14e,4,0,201 107010343111 1614244843,39.8958397.48,352,1
哎,还是识别率太低了,所以没办法,手动复制再修改不一样的吧,大多数还是识别出来的。
最后就改成这样的
到这里总算把原料准备好了,这才开始正题!
臆想采集
靠着自己臆想出来的原料数据txt,把他写到sql中应该并不是很难,直接来。
至于怎么对用python写入数据库,请看Python+MySQL用户加密存储验证系统(进阶) 和 Python与MySQL联动实例一两则
贴上核心代码
# -*- coding: utf-8 -*-
#Author:哈士奇说喵
import pymysql
#初始化数据库子函数
def Init():
#创建数据库
try:
cur.execute('create database carnet')#创建名为professors数据库
cur.execute('use carnet')#切到该数据库
cur.execute('create TABLE store(id BIGINT(10) NOT NULL AUTO_INCREMENT,car VARCHAR(100),trigger_events VARCHAR(100),operation_state VARCHAR(100),times VARCHAR(100),longitude VARCHAR(100),latitude VARCHAR(100),speed VARCHAR(100),direction_angle VARCHAR(100),GPS_state VARCHAR(100),created TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,PRIMARY KEY(id))')
print '-------------------------------Create Database Succeed-------------------------------'
except:
#print 'database existed'
cur.execute('use carnet')#切到该数据库
#数据库的存储子函数
def store(a,b,c,d,e,f,g,h,i):
cur.execute("insert into store(car,trigger_events,operation_state,times,longitude,latitude,speed,direction_angle,GPS_state) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)",(a,b,c,d,e,f,g,h,i))
cur.connection.commit()#commit()提交事物,做出改变后必须提交事务,不然不能更新
def readTxt():
f = open("txt2sql.txt","r")
while True:
line = f.readline() #没有足够内存一次读取整个文件的时候要用readline,每次读一行
if line:
#print line
content = line.split(",") #以逗号为分隔符
store(content[0],content[1],content[2],content[3],content[4],content[5],content[6],content[7],content[8])
else:
break
f.close()
def Main():
Init()
readTxt()
#程序入口
if __name__ == '__main__':
try:
conn = pymysql.connect(host = '127.0.0.1',user='root',passwd='A089363b',db='mysql',charset='utf8')
#与数据库建立连接
cur = conn.cursor()
#实例化光标
print "-------------------------------SQL Connection Succeed-------------------------------"
except:
print "Warning!SQL Connection Failed!"
Main()
try:
cur.close()
conn.close()
print "-------------------------------SQL Connection Closed-------------------------------"
print "-------------------------------Over-------------------------------"
except:
print "Warning!Can't Close Connection!"最后实现效果如下,比较圆满,因为格式我看的很清楚,结合数据清洗,一下子就出来了。
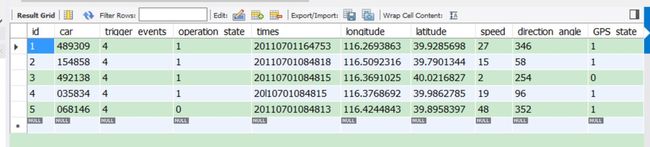
真实的数据
满心欢喜的以为和博士论文中的格式一样,直接套上就行,结果,你给我看这个???

因为,我的电脑,根本打不开那么大的txt!!!!这特么就尴尬了,,,,所以先让学弟把文件分片(我的天,11G的一个txt,他分成4200多个txt,额)。
分析解决
从上面的图可以看出,数据那么连续,而且杂乱无章,实在没办法,我用其他的编辑器打开(Notepad++打开)

ok,好看多了,那么分析一下,数据之间有多个空格,而且不限个数,最后用了换行符来变成下一行数据,根据数据清洗的思想,我先把换行符改成空格,然后把多个空格替换为一个空格,最后用split对空格进行拆分,没错,应该就是这样。
实现代码,先对data0.txt数据进行测试分析(分片之一),限制mysql的显示行数为无限制,一个2.8MB的数据,我想也跑不出花的
# -*- coding: utf-8 -*-
#Author:哈士奇说喵
import pymysql
import re
#初始化数据库子函数
def Init():
#创建数据库
try:
cur.execute('create database carnet')#创建名为professors数据库
cur.execute('use carnet')#切到该数据库
cur.execute('create TABLE store(id BIGINT(10) NOT NULL AUTO_INCREMENT,car VARCHAR(100),trigger_events VARCHAR(100),operation_state VARCHAR(100),times VARCHAR(100),longitude VARCHAR(100),latitude VARCHAR(100),speed VARCHAR(100),direction_angle VARCHAR(100),GPS_state VARCHAR(100),G10 VARCHAR(100),G11 VARCHAR(100),G12 VARCHAR(100),G13 VARCHAR(100),created TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,PRIMARY KEY(id))')
print '-------------------------------Create Database Succeed-------------------------------'
except:
#print 'database existed'
cur.execute('use carnet')#切到该数据库
#数据库的存储子函数
def store(a,b,c,d,e,f,g,h,i,j,k,l,m):
cur.execute("insert into store(car,trigger_events,operation_state,times,longitude,latitude,speed,direction_angle,GPS_state,G10,G11,G12,G13) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(a,b,c,d,e,f,g,h,i,j,k,l,m))
cur.connection.commit()#commit()提交事物,做出改变后必须提交事务,不然不能更新
def readTxt():
f = open("C:\Users\MrLevo\Desktop\data0.txt","r")
#f = open("H:\\20151208.txt","r")
while True:
line = f.readline()
if line:
line = re.sub(' +'," ",line) #把多个空格替换成一个空格
line = re.sub('\t',' ',line)#制表符也替换成空格
content = line.split(" ")
store(content[0],content[1],content[2],content[3],content[4],content[5],content[6],content[7],content[8],content[9],content[10],content[11],content[12].decode('utf-8'))
#content[12].decode('utf-8')因为第13个分割后的是中文字符,需要解码一下
else:
print 'txt2sql succeed!'
break
f.close()
def Main():
Init()
readTxt()
#程序入口
if __name__ == '__main__':
try:
conn = pymysql.connect(host = '127.0.0.1',user='root',passwd='A089363b',db='mysql',charset='utf8')
#与数据库建立连接
cur = conn.cursor()
#实例化光标
print "-------------------------------SQL Connection Succeed-------------------------------"
except:
print "Warning!SQL Connection Failed!"
Main()
try:
cur.close()
conn.close()
print "-------------------------------SQL Connection Closed-------------------------------"
print "-------------------------------Over-------------------------------"
except:
print "Warning!Can't Close Connection!"之后大概过了三分钟,结束程序,采集到16905个数据,和txt中对应,成功。

挑战一下
既然能读分片后的数据,那么我尝试读一下11G的原始数据,吧sql显示行数控制在5W行,运行大概十五分钟停止。
瞎扯
推测一下,11G原始数据我电脑需要不停跑3.6天才能写完到数据库中,这才是数据写入而已啊,哎,还是用hadoop来做吧,不然真的会死人的,这才一天的GPS数据,要是一个月,一年,,,,,所以大数据的发展是必然趋势,我这里只是做一下测试,也算是真正对原始数据进行了一下简单的操作。
致谢
Python网络数据采集[Ryan Mitchell著][人民邮电出版社]
@MrLevo520–Python+MySQL用户加密存储验证系统(进阶)
@MrLevo520–Python与MySQL联动实例一两则
@MrLevo520–Python+Selenium+PIL+Tesseract真正自动识别验证码进行一键登录