php解析html类
本想做采集系统,但没有趁手的php版解析器。网上搜到一个simple_html_dom-master,全是英文。看了源码可以操作dom。但我很想自己写一个,不需太强大,可做采集即可。

采取的思路是状态标记解析,如python中的htmlparser。将html分块:startTag endTag 文本块 注释块...我则加了个单标签块
我的类是个抽象类,用法就是自己继承父类并自己填充抽象方法,提供了参数:显示嵌套深度的level变量没有提供
源码,为了节省内存将块字符串换成了块在html源码中的index,length形式的数组
保存块的数组 压入(块类型,标签名,嵌套深度,字符串(index,length))
array_push($this->BlockArr,array(HTML_TEXT,"",0,substr($this->htmlcode,$posL,$i-$posL+1)));
原先的形式:
$tempstr = substr($this->htmlcode,$posL,$posR-$posL+1);
array_push($this->BlockArr,array(HTML_TAG_ST,$tagname,0,$tempstr));
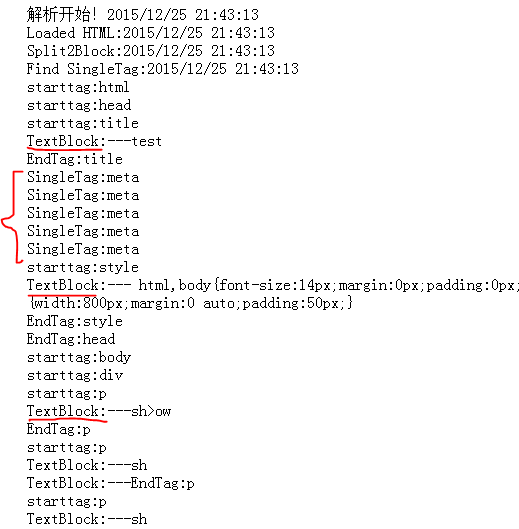
先给效果图,后面紧接源码
<?php
/*
时间:2015-12-25 19:04:34
作者:阮家友
QQ:1439120442
*/
//定义常量 html文件分4种类型块
//开始标签
define("HTML_TAG_ST",1);
//结束标签
define("HTML_TAG_END",2);
// <!开头 文档声明和注释
define("HTML_COMMENT",3);
//文本
define("HTML_TEXT",4);
//单标签
define("HTML_SINGLE_TAG",5);
//左方括号
define("CHAR_L_BRACKET","<");
//右方括号
define("CHAR_R_BRACKET",">");
//单引号
define("CHAR_S_QUOTE","'");
//双引号
define("CHAR_D_QUOTE",'"');
//与
define("CHAR_AND","&");
//感叹号
define("CHAR_GanTanHao",'!');
//斜杠 除法 Unix中表示目录
define("CHAR_XieGang",'/');
//反斜杠 转义
define("CHAR_FanXieGang",'\\');
//tab键
define("CHAR_TAB",'\t');
//空格
define("CHAR_SPACE",' ');
//回车
define("CHAR_ENTENR",'\r');
//换行
define("CHAR_NewLine",'\n');
abstract class parser{
//成员变量
//路径
private $path;
//html源码
private $htmlcode;
//分块数组
private $BlockArr;
//分析层级栈 永远是开始标签
private $Zhan;
//层级变量
private $level;
//属性数组 在标记单标签时借用一下
private $AttributesArr;
//构造函数
function __construct($path){
$this->htmlcode = "";
$this->path = $path;
$this->BlockArr = array();
$this->AttributesArr = array();
$this->Zhan = array();
$this->level=0;
$datetime = new DateTime('Asia/Hong_Kong');
print "解析开始!".$datetime->format('Y/m/d H:i:s')."<br/>";
}
//析构函数
function __destruct(){
$datetime = new DateTime('Asia/Hong_Kong');
print "解析完成!".$datetime->format('Y/m/d H:i:s')."<br/>";
echo "FileSize:".strlen($this->htmlcode)."<br/>";
echo "block length:".count($this->BlockArr);
}
//获取HTML源码
function LoadHTML(){
$this->htmlcode = file_get_contents($this->path);
}
//将HTML源码分割为块
function Split2Block(){
$tempstr="";//保存截取的临时字符串
$temp = array();//匹配結果
$tagname = "";//标签名
$CurrentPos = 0;//当前字符在字符串中的索引 下标 index
$N = strlen($this->htmlcode);//字符串的长度
$posL = 0;//块的左端位置
$posR = 0;//块的右端位置
$type = 0;//当前块的类型
$bCommentOEndTag = false;
$bSingleTag = false;
$bTextStart = false;
$bEndTag = false;
// < 开始
$bLSBracketStart = false;
// > 开始
$bRSBracketStart = false;
// " 开始
$bSQuoteStart = false;
// ' 开始
$bDQuoteStart = false;
for($i=0;$i<$N;$i++){
//只对<>"'!/感兴趣
if(!preg_match('/[<>\'\"!\/]/',$this->htmlcode[$i],$temp)){
continue;
}
// 检测到 ! / StartTag Comment EndTag判断 < 开始设置了默认类型是开始标签 后面第一个字符是 ! 则本块是注释 是/ 则是结束标签
if(true == $bLSBracketStart &&true==$bCommentOEndTag&&(CHAR_GanTanHao== $this->htmlcode[$i]|| CHAR_XieGang == $this->htmlcode[$i])){
// : ! 本块是注释
if(CHAR_GanTanHao == $this->htmlcode[$i]){
$type = HTML_COMMENT;
}
// : / 并且不再字符串内 本块是结束标签
if(CHAR_XieGang == $this->htmlcode[$i]&&false==$bSQuoteStart&&false==$bDQuoteStart){
$type = HTML_TAG_END;
}
//本次块的类型判断结束 还原状态 等待下次
$bCommentOEndTag = false;
continue;
}
//检测到 " '单引号或双引号 true == $bLSBracketStart && HTML_TAG_ST==$type &&(
if($bLSBracketStart && HTML_COMMENT!=$type && (CHAR_S_QUOTE==$this->htmlcode[$i]|| CHAR_D_QUOTE==$this->htmlcode[$i])){
//单引号
if(CHAR_S_QUOTE==$this->htmlcode[$i]){
//单引号开始过则此单引号进行闭合操作
if(true == $bSQuoteStart){
$bSQuoteStart = false;
}
//双引号开始过则跳过
else{
if(true == $bDQuoteStart){
continue;
}
//单引号开头的字符串开启
else{
$bSQuoteStart = true;
}
}
}
//双引号
else{
//双引号开始过则闭合
if(true == $bDQuoteStart){
$bDQuoteStart = false;
}
//单引号开始过则跳过
else{
if(true == $bSQuoteStart){
continue;
}
//双引号开头的字符串开启
else{
$bDQuoteStart = true;
}
}
}
}//引号处理结束
//检测到 <字符
if(CHAR_L_BRACKET==$this->htmlcode[$i]){
//如果在注释或字符串中则跳过
if(HTML_COMMENT == $type||$bSQuoteStart||$bDQuoteStart){
continue;
}
//当前块类型为文本或>开始后遇到<
//将当前块设为文本并push 重新开启 <
if($bTextStart||$bLSBracketStart){
$bTextStart = false;
$temp = trim(substr($this->htmlcode,$posL,$i-$posL));
if(""!=$temp){
array_push($this->BlockArr,array(HTML_TEXT,"",0,array($posL,$i-$posL)));
}
}
$posL=$i;
$type = HTML_TAG_ST;
$bLSBracketStart = true;
$bCommentOEndTag = true;
continue;
}// < 结束
//检测到 >字符
if(CHAR_R_BRACKET==$this->htmlcode[$i]){
//在字符串内则跳过 或<没开始
if($bSQuoteStart||$bDQuoteStart||false==$bLSBracketStart){
continue;
}
$posR = $i;
$bRSBracketStart = true;
//开始块 结束块 注释块在此处理
//文本块不在此处理
//截取出当前块的内容
$tempstr = substr($this->htmlcode,$posL,$posR-$posL+1);
switch($type){
case HTML_TAG_ST:
//提取标签名
$tagname = preg_match("/<\s*(\w+)/i",$tempstr,$temp) ? strtolower($temp[1]):"STerror";
if("STerror" == $tagname){
array_push($this->BlockArr,array(HTML_TEXT,"",0,array($posL,$posR-$posL+1)));
break;
}
//分析是否是单标签
$bSingleTag = preg_match('/\/\s*>$/',$tempstr,$temp)?true:false;
if($bSingleTag){
//将块压到目标数组中 是单标签
array_push($this->BlockArr,array(HTML_SINGLE_TAG,$tagname,0,array($posL,$posR-$posL+1)));
}
else{
//将块压到目标数组中 是开始标签或没正确闭合的标签
array_push($this->BlockArr,array(HTML_TAG_ST,$tagname,0,array($posL,$posR-$posL+1)));
}
break;
case HTML_TAG_END:
//提取标签名
$tagname = preg_match("/<\s*\/\s*(\w+)/i",$tempstr,$temp) ? strtolower($temp[1]):"ENDerror";
if("ENDerror"==$tagname){
array_push($this->BlockArr,array(HTML_TEXT,"",0,array($posL,$posR-$posL+1)));
}
else{
array_push($this->BlockArr,array(HTML_TAG_END,$tagname,0,array($posL,$posR-$posL+1)));
}
break;
case HTML_COMMENT:
//直接将当前块的内容压到目标数组中
array_push($this->BlockArr,array(HTML_COMMENT,"",0,array($posL,$posR-$posL+1)));
break;
default:break;
}
//闭合 <
$bLSBracketStart = false;
$bTextStart = true;
$type = 0;
//为文本做准备
$posL = $i+1;
}
}
}
function MarkSingleTag(){
$bMatched = false;
for($i=0;$i<count($this->BlockArr)-1;$i++){
if(HTML_COMMENT == $this->BlockArr[$i][0]||HTML_TEXT == $this->BlockArr[$i][0]||HTML_SINGLE_TAG == $this->BlockArr[$i][0]){
continue;
}
//开始标签
if(HTML_TAG_ST == $this->BlockArr[$i][0]){
array_push($this->Zhan,$i);
}
//结束标签
else{
for($j = count($this->Zhan)-1;$j>=0;$j--){
if($this->BlockArr[$this->Zhan[$j]][1]==$this->BlockArr[$i][1]){
$bMatched = true;
for($k = count($this->Zhan)-1;$k>=0;$k--){
if($this->BlockArr[$this->Zhan[$k]][1]!=$this->BlockArr[$i][1]){
//没关闭的标签
$this->BlockArr[$this->Zhan[$k]][0]=HTML_SINGLE_TAG;
array_pop($this->Zhan);
}
else{
array_pop($this->Zhan);
break;
}
}
}
}
if(false==$bMatched){
$this->BlockArr[$i][0]=HTML_SINGLE_TAG;
}
$bMatched = false;
}
}
}
//获取开始标签或单标签的属性数组
//预处理 私有不可访问
private function GetAttributes($str){
$AttrArr = array();
//属性字符串提取
$AttrStr = preg_match("/<\s*?[a-zA-Z]+?\s+?([^>\/]*?)[>]/",$str,$temp)?$temp[1]:"";
//化为kv数组
preg_match_all('/\s*?([a-zA-Z]+[-]?[a-zA-Z0-9]+)\s*?[=][\s]*?[\'\"]?([^\s\'\"]+?)[\'\"\s]+?/',$AttrStr,$match);
for($i=0;$i<count($match[0]);$i++){
$AttrArr[$match[1][$i]] = $match[2][$i];
}
return $AttrArr;
}
public function BeginParser(){
//加载html源码
$this->LoadHTML();
$datetime = new DateTime('Asia/Hong_Kong');
print "Loaded HTML:".$datetime->format('Y/m/d H:i:s')."<br/>";
//html分块
$this->Split2Block();
$datetime = new DateTime('Asia/Hong_Kong');
print "Split2Block:".$datetime->format('Y/m/d H:i:s')."<br/>";
//寻找单标签
$this->MarkSingleTag();
$datetime = new DateTime('Asia/Hong_Kong');
print "Find SingleTag:".$datetime->format('Y/m/d H:i:s')."<br/>";
//之前的代码 测试调用 重写父函数抽象方法 的结果
//不过这个版本的每个BlockArr的块中 最后面的不是字符串而是array($index,$length)保存在字符串在原html中的下标和长度
$level = 0;
for($i=0;$i<count($this->BlockArr);$i++){
switch($this->BlockArr[$i][0]){
case HTML_TAG_ST:
$level++;
$this->BlockArr[$i][2]=$level;
$this->StartTag($this->BlockArr[$i][1],$this->GetAttributes(substr($this->htmlcode,$this->BlockArr[$i][3][0],$this->BlockArr[$i][3][1])));
break;
case HTML_TAG_END:
$level--;
$this->BlockArr[$i][2]=$level;
$this->EndTag($this->BlockArr[$i][1]);
break;
case HTML_SINGLE_TAG:
$this->BlockArr[$i][2]=$level;
$this->SingleTag($this->BlockArr[$i][1],$this->GetAttributes(substr($this->htmlcode,$this->BlockArr[$i][3][0],$this->BlockArr[$i][3][1])));
break;
case HTML_TEXT:
$this->BlockArr[$i][2]=$level;
$this->TextBlock(substr($this->htmlcode,$this->BlockArr[$i][3][0],$this->BlockArr[$i][3][1]));
break;
case HTML_COMMENT:
break;
default:break;
}
}
}
//遇到开始标签时调用
abstract function StartTag($tagname,$attrArr);
//遇到结束标签时调用
abstract function EndTag($tagname);
abstract function SingleTag($tagname,$attrArr);
//遇到文本时调用
abstract function TextBlock($txt);
}
//例子
class newparser extends parser{
function StartTag($tagname,$attr){
echo "starttag:".$tagname."<br/>";
}
function EndTag($tagname){
echo "EndTag:".$tagname."<br/>";
}
function SingleTag($tagname,$attr){
echo "SingleTag:".$tagname."<br/>";
}
function TextBlock($str){
echo "TextBlock:---".$str."<br/>";
}
}
$parser1 = new newparser("http://localhost/MyHTMLParser/test.html");
//$parser1 = new newparser("http://localhost/MyHTMLParser/maxLength.html");
$parser1->BeginParser();
?>
一次测试(数组说明(块类型,标签名,嵌套深度,块完整字符串)):
对提取标签属性数组的测试
var_dump(FindAttributes('<meta name="Description"width=100 content="special effect">'));
要想用于采集,分出标签的层次是必须的,找出单标签也不难。开始时我用的递推方法,太傻不拉几了,性能达不到嵌套太深。后来对数组进行栈操作。碰到开始标签则入栈,碰到结束标签则进行归约,不能归约的当做单标签;成功则pop,将中间的开始标签全标记为单标签。
13w多个块,html文档0.55M大小,也只用2s,火狐和谷歌结果是一样的。用来测试的文件很大,Firefox浏览器hold不住,chrome渲染起来也很累
字体编辑用的中日韩Unicode字码表