leetcode 题解 3. Longest Substring Without Repeating Characters
这一题的目标是找出字符串中最长的子串,要求字符串无重复。
先是一个错误的解法:
- 首先找出最长的无重复子串
- 从该子串的下一个字母开始,继续执行判断过程。
但这一方法存在一定的漏洞,对于其中的测试用例:“dvdf”,如果采用以上思路,则首先得到子串“dv”;再从d开始判断,得到子串“df”,此时处理过程结束。但以上过程并不能得到最优结果“vdf”。因此为解决这种情况,解法又回到了暴力方法。
暴力法的思路如下:
使用每一个字母作为子串的开头,查找最长的无重复子串,直到最后一个字母,源码如下:
int lengthOfLongestSubstring(char* s) {
int length = strlen(s);
if(length==0) return 0;
int curLength = 1;
int maxLength = 1;
int start = 0;
int i,j,k;
for(i=0;i<length;i++){
for(j=i+1;j<length;j++){
for(k=i;k<j;k++){
if(s[k]==s[j]) break;
}
if(k!=j) break;
else curLength++;
}
if(curLength>maxLength) maxLength = curLength;
curLength = 1;
}
return maxLength;
}
以上方法的时间复杂度为O(n^3)。这种方法大概排在后5.97%。
可以进行一点简单的优化,不必运行到最后一个字母,若之前获得的maxLength大于1,则只需执行到length-maxLength,因为若继续执行,即使得到了一个无重复的子串,其长度也只能小于等于maxLength。
所以上述循环结束条件可以转变为:
i<length-maxLength
这一优化对性能提升的效果很有限,仅能使排名提高到后7.13%。
leetcode中还给出了一种参考答案,基本思路如下:
使用滑动窗口的概念,其实和我第一种思路比较相似,但不同之处在于当出现重复字符时,不是直接移动到重复的字符,而是将窗口的左端向右移动一位。
使用一幅图表示这一过程。
第一种错误的思路:
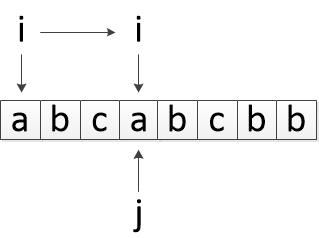
出现重复字符时,窗口左端直接移动到重复字符处。
再来通过一幅图,对比一下:
若出现重复字符则只是将窗口左端向右移动一位。此时子串中一定不会出现重复的字符。
上述思路的源码如下:
int isUnique(char* s,int start,int end);
int lengthOfLongestSubstring(char* s) {
int length = strlen(s);
if(length==0) return 0;
int start = 0;
int end = 1;
int maxLength = 1;
int i;
while(start<length&&end<length){
if(isUnique(s,start,end)) ++end;
else ++start;
maxLength = maxLength>(end-start)?maxLength:(end-start);
}
return maxLength;
}
int isUnique(char* s,int start,int end){
char temp = s[end];
int i;
for(i=start;i<=end-1;i++){
if(s[i]==temp) return 0;
}
return 1;
}
运行速度提升到后30.51%。
还可以继续提高速度,现在主要制约程序速度的操作时isUnique。能不能再将这一部分的速度提高一些,leetcode同样给出了优化方案。可以使用hashset对子串中的字符进行存储。此处利用hashset进行存储是利用其O(1)的查找时间。
此处直接使用答案中给出的源码:
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length();
Set<Character> set = new HashSet<>();
int ans = 0, i = 0, j = 0;
while (i < n && j < n) {
// try to extend the range [i, j]
if (!set.contains(s.charAt(j))){
set.add(s.charAt(j++));
ans = Math.max(ans, j - i);
}
else {
set.remove(s.charAt(i++));
}
}
return ans;
}
}
速度上提升并不多。
再来看leetcode上给出的最后一种方法。
还是从两个方面对算法进行优化:
首先是滑动窗口[i,j),若j元素与滑动窗口中j‘元素重复,则可以直接将i调整到j’+1,而不必将i逐一的向后移动。
此时,问题的关键点就来到了如何快速的确定j'的位置,其实使用第二种方法修改一下isUnique函数,是可以确定j'的位置的。但leetcode给出了更好的策略:使用map,或直接使用数组对j'的位置进行存储,使用字符对应的ascii值作为索引,
使用第二种策略,源码如下:
int lengthOfLongestSubstring(char* s) {
int n = strlen(s);
int start;
int end;
int maxLength = 0;
int* set = (int*)malloc(sizeof(int)*128);
memset(set,0,sizeof(int)*128);
for(start=0,end=0;end<n;end++){
start = set[s[end]]>start?set[s[end]]:start;
maxLength = maxLength>(end-start+1)?maxLength:(end-start+1);
set[s[end]] = end+1;
}
return maxLength;
}
这一方法的关键就在于:
set[s[end]] = end+1;
速度终于提升到超过60.36%。