【caffe-Windows】cifar实例编译之model的生成
参考:<span style="font-family: Arial, Helvetica, sans-serif;">http://blog.csdn.net/chengzhongxuyou/article/details/50715455</span>
准备工作
按照之前的教程,成功生成过caffe,并且编译整个caffe.sln项目工程,在\caffe-master\Build\x64\Debug生成了一堆exe文件,后面会使用到除了caffe.exe的另外一个exe
【PS】很多VS安装过程中出现问题的,比如XX加载失败,XX未找到等,请自行寻找问题,很可能是原来的VS没卸载干净,或者VS版本缺少一些文件等导致。正常情况下,第一次编译只有libcaffe.lib显示失败,不会出现其它error
第一步
下载cifar的数据集
官网地址:http://www.cs.toronto.edu/~kriz/cifar.html
我的百度云地址:二进制数据文件链接:http://pan.baidu.com/s/1hrRApwC 密码:1dxy
.mat格式连接:链接:http://pan.baidu.com/s/1hr6B7Xa密码:f343
多一句嘴,这个数据集是彩色图片,也即具有RGB三通道,数据存储方式是一行为一张图片,包含3*32*32=3072个像素属性,具体多少张图片,有兴趣的可以去官网看看,或者看看数据集的存储格式:样本数(图片数)*3072
【与训练model无关】下面代码是用matlab写的,用于显示其中一个样本,当然你可以用reshape函数,前面我介绍过这个函数
image=zeros(32,32,3);
count=0;
for i=1:3
for j=1:32
for k=1:32
count=count+1;
image(j,k,i)=data(1000,count);
end
end
end
imshow(uint8(image))
第二步
下载完毕以后,解压得到数据,请核对是否与下图一样
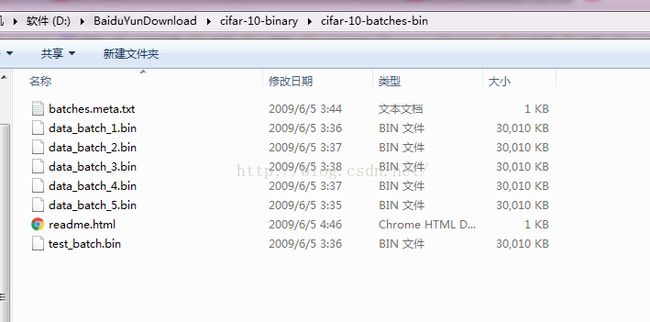
按照下列路径,在自己的caffe目录下建立input_folder文件夹,并拷贝相应数据集
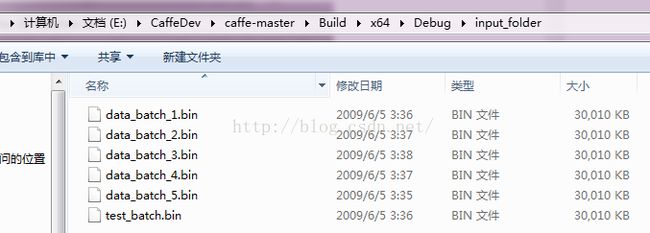
第三步
在input_folder的上一级目录,也就是Debug目录建立一个bat文件(名称随意,我用的是convert.bat),用于转换数据集格式,内容如下
convert_cifar_data.exe input_folder output_folders leveldb pause【PS】此处的exe就是在编译caffe.sln时候生成的,如果没有,请在VS中修改生成模式为DEBUG,而非release
【PS】caffe-windows是caffe官方提供的caffe,与caffe-master差不多,我这里为了从头演示,没有在master里面操作,无视之即可
运行此bat文件,会生成一个文件夹output_folders,里面有两个文件夹,请核对路径以及文件数目
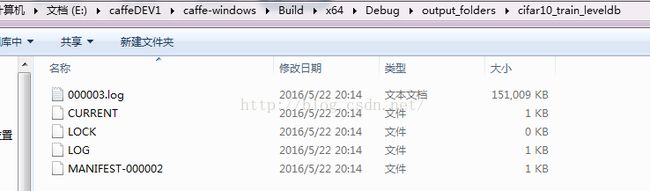
第四步
计算均值,新建另一个bat文件(本文采用mean.bat),如下图所示,请核对路径
compute_image_mean.exe output_folders/cifar10_train_leveldb mean.binaryproto pause
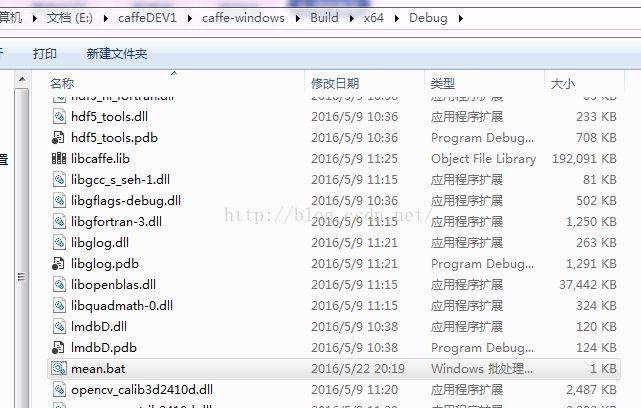
双击此bat文件,不出意外会出现下面问题:
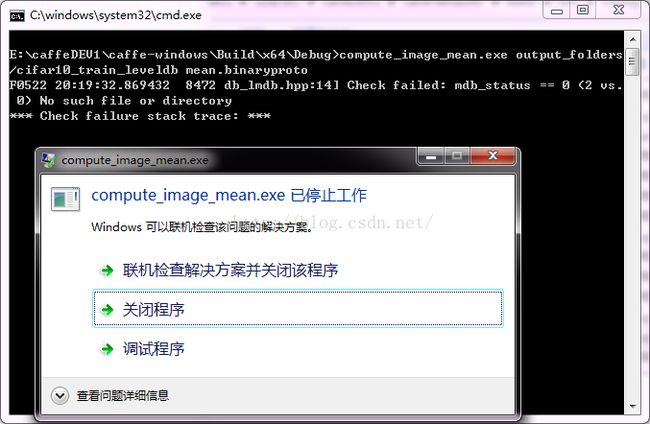
解决方法,打开caffe.sln,修改compute_image_mean.cpp
重新生成一下,得到新的计算均值的exe文件【电脑编译中。。。等待ing。。。。】
编译完毕,重新运行bat文件,仔细检查debug文件夹,会发现有一个文件名为:mean.binaryproto
第五步
将debug文件夹下的mean.binaryproto以及output_folders下的两个文件夹拷贝到caffe-windows\examples\cifar10
在caffe-windows也就是caffe-master(根据版本自行决定)文件夹下新建一个bat文件,用于训练模型,本文使用train.bat
.\Build\x64\Debug\caffe.exe train --solver=examples/cifar10/cifar10_quick_solver.prototxt pause在运行之前需要修改几个文件,此处截图超过2M了,传不上来,读者自己核对路径以及CPU训练设置
cifar10_quick_solver.prototxt文件:
# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10 # The train/test net protocol buffer definition net: "examples/cifar10/cifar10_quick_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.001 momentum: 0.9 weight_decay: 0.004 # The learning rate policy lr_policy: "fixed" # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 4000 # snapshot intermediate results snapshot: 4000 snapshot_format: HDF5 snapshot_prefix: "examples/cifar10/cifar10_quick" # solver mode: CPU or GPU solver_mode: CPU——————————————————————————————————————————————————————————————————————————
cifar10_quick_train_test.prototxt文件【只贴前面一部分】,需要修改的就是数据格式为leveldb,以及相关路径,自行核对
name: "CIFAR10_quick"
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_train_leveldb"
batch_size: 100
backend: LEVELDB
}
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_test_leveldb"
batch_size: 100
backend: LEVELDB
}
}一定要核对正确,我好像在设置添加路径的时候多了一个空格,结果出现了下面问题
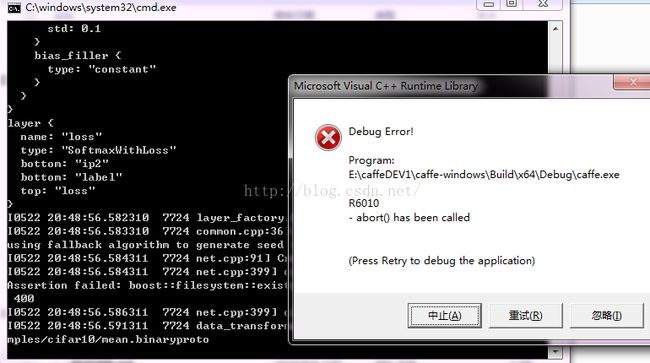
【PS】一定要细心
最后,运行train.bat时候出现如下界面,说明正在训练
是不是感觉和网上看到的不一样呢?网上都是各种iteration 和loss显示在命令窗口,但是这里出现了prefetch batch等。原因在于我们用的是debug模式下生成的caffe在训练,如果想看到如下情形的结果,请将caffe.sln使用release模式生成(用VS2013打卡caffe.sln以后,上方中间部分的dubug改为release,然后右键工程,重新生成)
第六步
训练完成,会得到如下文件
下面是我训练好的cifar10的model,读者可下载,可自行训练
cifar10_quick_iter_4000.caffemodel.h5的链接:http://pan.baidu.com/s/1o8xSqr4 密码:ftc5
cifar10_quick_iter_4000.solverstate.h5的链接:链接:http://pan.baidu.com/s/1eRGPlNs 密码:589n
第七步
附带说一下caffe train 的finetuning。我们在编译成功caffe以后显示的dos窗口显示的有一行是:
commands: train train or finetune a model只要是用caffe train -solver=xxxxxxx,那就是从头开始训练
凡是遇到caffe train -solver=xxxx -weights=xxxxxx.caffemodel(.h5),那就是用已有模型参数(权重偏置)去初始化网络,称为finetune