百度2014校园招聘-研发工程师笔试题(济南站)
一、简答题(本题共30分)
1. 当前计算机系统一般会采用层次结构来存储数据,请介绍下典型的计算机存储系统一般分为哪几个层次,为什么采用分层存储数据能有效提高程序的执行效率?(10分)
所谓存储系统的层次结构,就是把各种不同存储容量、存取速度和价格的存储器按层次结构组成多层存储器,并通过管理软件和辅助硬件有机组合成统一的整体,使所存放的程序和数据按层次分布在各种存储器中。目前,在计算机系统中通常采用三级层次结构来构成存储系统,主要由高速缓冲存储器Cache、主存储器和辅助存储器组成。
存储系统多级层次结构中,由上向下分三级,其容量逐渐增大,速度逐级降低,成本则逐次减少。整个结构又可以看成两个层次:它们分别是主存一辅存层次和cache一主存层次。这个层次系统中的每一种存储器都不再是孤立的存储器,而是一个有机的整体。它们在辅助硬件和计算机操作系统的管理下,可把主存一辅存层次作为一个存储整体,形成的可寻址存储空间比主存储器空间大得多。由于辅存容量大,价格低,使得存储系统的整体平均价格降低。由于Cache的存取速度可以和CPU的工作速度相媲美,故cache一主存层次可以缩小主存和cPu之间的速度差距,从整体上提高存储器系统的存取速度。尽管Cache成本高,但由于容量较小,故不会使存储系统的整体价格增加很多。
综上所述,一个较大的存储系统是由各种不同类型的存储设备构成,是一个具有多级层次结构的存储系统。该系统既有与CPU相近的速度,又有极大的容量,而成本又是较低的。其中高速缓存解决了存储系统的速度问题,辅助存储器则解决了存储系统的容量问题。采用多级层次结构的存储器系统可以有效的解决存储器的速度、容量和价格之间的矛盾。
| 第一层:通用寄存器堆 第二层:指令与数据缓冲栈 第三层:高速缓冲存储器 第四层:主储存器(DRAM) 第五层:联机外部储存器(硬磁盘机) 第六层:脱机外部储存器(磁带、光盘存储器等) 这就是存储器的层次结构~~~ 主要体现在访问速度~~~ 1,设置多个存储器并且使他们并行工作。本质:增添瓶颈部件数目,使它们并行工作,从而减缓固定瓶颈。 2,采用多级存储系统,特别是Cache技术,这是一种减轻存储器带宽对系统性能影响的最佳结构方案。本质:把瓶颈部件分为多个流水线部件,加大操作时间的重叠、提高速度,从而减缓固定瓶颈。 3,在微处理机内部设置各种缓冲存储器,以减轻对存储器存取的压力。增加CPU中寄存器的数量,也可大大缓解对存储器的压力。本质:缓冲技术,用于减缓暂时性瓶颈。 |
2. Unix/Linux系统中僵尸进程是如何产生的?有什么危害?如何避免?(10分)
一个进程在调用exit命令结束自己的生命的时候,其实它并没有真正的被销毁,而是留下一个称为僵尸进程(Zombie)的数据结构(系统调用exit,它的作用是使进程退出,但也仅仅限于将一个正常的进程变成一个僵尸进程,并不能将其完全销毁)。
在Linux进程的状态中,僵尸进程是非常特殊的一种,它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。它需要它的父进程来为它收尸,如果他的父进程没安装SIGCHLD信号处理函数调用wait或waitpid()等待子进程结束,又没有显式忽略该信号,那么它就一直保持僵尸状态,如果这时父进程结束了,那么init进程自动会接手这个子进程,为它收尸,它还是能被清除的。但是如果如果父进程是一个循环,不会结束,那么子进程就会一直保持僵尸状态,这就是为什么系统中有时会有很多的僵尸进程。
避免zombie的方法:
1)在SVR4中,如果调用signal或sigset将SIGCHLD的配置设置为忽略,则不会产生僵死子进程。另外,使用SVR4版的sigaction,则可设置SA_NOCLDWAIT标志以避免子进程 僵死。
Linux中也可使用这个,在一个程序的开始调用这个函数 signal(SIGCHLD,SIG_IGN);
2)调用fork两次。
3)用waitpid等待子进程返回.
3. 简述Unix/Linux系统中使用socket库编写服务器端程序的流程,请分别用对应的socket通信函数表示(10分)
TCP socket通信
服务器端流程如下:
1.创建serverSocket
2.初始化 serverAddr(服务器地址)
3.将socket和serverAddr 绑定 bind
4.开始监听 listen
5.进入while循环,不断的accept接入的客户端socket,进行读写操作write和read
6.关闭serverSocket
客户端流程:
1.创建clientSocket
2.初始化 serverAddr
3.链接到服务器 connect
4.利用write和read 进行读写操作
5.关闭clientSocket
这个列表是一个Berkeley套接字API库提供的函数或者方法的概要:
socket() 创建一个新的确定类型的套接字,类型用一个整型数值标识,并为它分配系统资源。
bind() 一般用于服务器端,将一个套接字与一个套接字地址结构相关联,比如,一个指定的本地端口和IP地址。
listen() 用于服务器端,使一个绑定的TCP套接字进入监听状态。
connect() 用于客户端,为一个套接字分配一个自由的本地端口号。 如果是TCP套接字的话,它会试图获得一个新的TCP连接。
accept() 用于服务器端。 它接受一个从远端客户端发出的创建一个新的TCP连接的接入请求,创建一个新的套接字,与该连接相应的套接字地址相关联。
send()和recv(),或者write()和read(),或者recvfrom()和sendto(), 用于往/从远程套接字发送和接受数据。
close() 用于系统释放分配给一个套接字的资源。 如果是TCP,连接会被中断。
gethostbyname()和gethostbyaddr() 用于解析主机名和地址。
select() 用于修整有如下情况的套接字列表: 准备读,准备写或者是有错误。
poll() 用于检查套接字的状态。 套接字可以被测试,看是否可以写入、读取或是有错误。
getsockopt() 用于查询指定的套接字一个特定的套接字选项的当前值。
setsockopt() 用于为指定的套接字设定一个特定的套接字选项。
二、算法与程序设计题(本题共45分)
1. 使用C/C++编写函数,实现字符串反转,要求不使用任何系统函数,且时间复杂度最小,函数原型:char* reverse_str(char* str)。(15分)
获取首尾指针,然后将首尾指针指向的元素交换,将首指针指向下一个,将尾指针指向前一个,交换指针指向的元素,然后重复执行,直到首尾指针相遇。
2. 给定一个如下格式的字符串,(1,(2,3),(4,(5,6),7))括号内的元素可以是数字,也可以是另一个括号,请实现一个算法消除嵌套的括号,比如把上面的表达式变成:(1,2,3,4,5,6,7),如果表达式有误请报错。(15分)
使用栈和队列实现
3. (见下图)

#include <iostream>
#include <vector>
using namespace std;
struct topic_info_t {
int topic_id;
float topic_pr;
};
float similarity(vector<topic_info_t> query_topic_info,
vector<topic_info_t> adword_topic_info)
{
int i = 0, j = 0;
float sim = 0;
while(i < query_topic_info.size() && j < adword_topic_info.size())
{
if(query_topic_info[i].topic_id < adword_topic_info[j].topic_id)
{
i++;
}
else if(query_topic_info[i].topic_id > adword_topic_info[j].topic_id)
{
j++;
}
else
{
sim += query_topic_info[i].topic_pr * adword_topic_info[j].topic_pr;
i++;
j++;
}
}
return sim;
}
// topic_info_t已按id递增排序
float max_sim(const vector<topic_info_t> &query_topic_info,
const vector<topic_info_t> adwords_topic_info[],
int adwords_number)
{
int i;
float max_sim = 0, cur_sim = 0;
for(i = 0; i < adwords_number; i++)
{
cur_sim = similarity(query_topic_info, adwords_topic_info[i]);
cout << "current sim: " << cur_sim << endl;
if(cur_sim > max_sim)
{
max_sim = cur_sim;
}
}
return max_sim;
}
int main()
{
vector<topic_info_t> query_topic_info;
vector<topic_info_t> adwords_topic_info[3];
// 赋值有点傻,应该有更好的赋值方式
struct topic_info_t t = {1, 0.2f};
query_topic_info.push_back(t);
t.topic_id = 2;
t.topic_pr = 0.4f;
query_topic_info.push_back(t);
t.topic_id = 3;
t.topic_pr = 0.6f;
query_topic_info.push_back(t);
t.topic_id = 2;
t.topic_pr = 0.6f;
adwords_topic_info[0].push_back(t);
t.topic_id = 3;
t.topic_pr = 0.7f;
adwords_topic_info[0].push_back(t);
t.topic_id = 4;
t.topic_pr = 0.3f;
adwords_topic_info[0].push_back(t);
t.topic_id = 1;
t.topic_pr = 0.8f;
adwords_topic_info[1].push_back(t);
t.topic_id = 3;
t.topic_pr = 0.7f;
adwords_topic_info[1].push_back(t);
t.topic_id = 4;
t.topic_pr = 0.4f;
adwords_topic_info[1].push_back(t);
t.topic_id = 1;
t.topic_pr = 0.5f;
adwords_topic_info[2].push_back(t);
t.topic_id = 2;
t.topic_pr = 0.9f;
adwords_topic_info[2].push_back(t);
t.topic_id = 4;
t.topic_pr = 0.2f;
adwords_topic_info[2].push_back(t);
cout << "max sim: " << max_sim(query_topic_info, adwords_topic_info, 3) << endl;
return 0;
}
三、系统设计题(本题共25分)
在企业中,对生产数据进行分析具有很重要的意义,但是生产数据通常不能直接用于数据分析,通常需要进行抽取、转换和加载,也就是通常说的ETL。

为了便于开发和维护,并提高数据实时性,通常将一个完整的ETL过程分为多个任务,组成流水线,如下图所示:
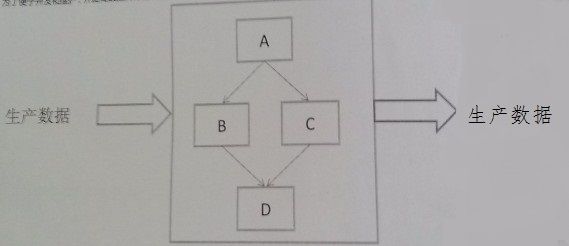
假设任务定义和任务之间的依赖关系都保存在文件中,文件格式分别如下:

问题:
1. 下面是ETL调度系统的模块图,请描述各个模块呃主要职责,以及各个线条的 含义。(10分)

2. 添加依赖关系时要避免出现环,假设系统同一个时刻只允许一个人添加任务依赖,请实现一个函数来检查新的依赖是否导致环,依赖的上游存在环会导致非正常的调度,因此也希望能避免。(10分)
a) 函数名:checkCycle
b) 输入:pairs,已存在的依赖关系((pre,post)……), newPair新的依赖关系(pre,post)
c) 输出:True: 不存在环,False: 存在环
3. 如果调度时,某个任务在其依赖的任务之前执行,必然导致错误,请实现调度算法,确保任务按照依赖顺序执行?(10分)
a) 函数名:schedule
b) 输入1:tasks,整数数组;
c) 输入2:task-relation,二元组数组,每个二元组表示一组关系;
d) 输出:task id序列,并行执行的用","分隔,其他的用";"分隔;
4. 给定一个任务,如何计算出他的最晚完成时间?(10分)
a) 函数名:calMaxEndTime
b) 输入1:tasks,3元组数组,(task_id, start_time, max_run_time);
c) 输入2:task-relations,二元组数组,每个二元组表示一组关系;
d) 输入3:task-id
e) 输出:最晚完成时间;