九、Flink入门--SQL实战
Flink-Sql 实战案例
- 1.环境准备
- 2.实战演示
- 2.1 需求一(出现在纽约的行车记录)
- 2.2 需求二(计算搭载每种乘客数量的行车记录数)
- 2.3 需求三(计算纽约市每个区域5分钟的进入车辆数)
- 2.4 需求四(将每10分钟搭乘的乘客总数写入Kafka)
- 2.5 需求五(将每个区域出发的行车数写入到ES)
1.环境准备
下载代码并安装环境,前提是准备好Docker环境。
git clone [email protected]:ververica/sql-training.git
cd sql-training
docker-compose up -d
会先下载以来镜像,时间比较慢,耐心等待。
接下来进入sql-client
docker-compose exec sql-client ./sql-client.sh
2.实战演示
表定义,Rides表,类型是source表,更新模式为追加。
tables:
- name: Rides #表名
type: source #表类型
update-mode: append #更新模式
schema:
- name: rideId #路线ID
type: LONG
- name: taxiId #出租车ID
type: LONG
- name: isStart #是否出发
type: BOOLEAN
- name: lon #经度
type: FLOAT
- name: lat #纬度
type: FLOAT
- name: rideTime #时间
type: TIMESTAMP
rowtime:
timestamps:
type: "from-field"
from: "eventTime"
watermarks:
type: "periodic-bounded"
delay: "60000"
- name: psgCnt #乘客数量
type: INT
connector:
property-version: 1
type: kafka
version: 0.11
topic: Rides
startup-mode: earliest-offset #kafka offset
properties:
- key: zookeeper.connect
value: ${ZOOKEEPER}:2181
- key: bootstrap.servers
value: ${KAFKA}:9092
- key: group.id
value: testGroup
format:
property-version: 1
type: json
schema: "ROW(rideId LONG, isStart BOOLEAN, eventTime TIMESTAMP, lon FLOAT, lat FLOAT, psgCnt INT, taxiId LONG)"
2.1 需求一(出现在纽约的行车记录)
判断经纬度是否在纽约的UDF函数如下:
public class IsInNYC extends ScalarFunction {
public boolean eval(float lon, float lat) {
return isInNYC(lon, lat);
}
}
UDF加载定义如下:需要在sql-client启动时加载的配置文件中定义
functions:
- name: isInNYC
from: class
class: com.dataartisans.udfs.IsInNYC
查询出现在纽约的行车记录,sql如下:
select * from Rides where isInNYC(lon.lat);
![]()
由于后续我们可能会一直用到纽约市的行车记录,所以我们可以建一个view来方便后续使用,命令如下:
CREATE VIEW nyc_view as select * from Rides where isInNYC(lon.lat);
show tables;
Flink SQL> show tables;
nyc_view
Rides
2.2 需求二(计算搭载每种乘客数量的行车记录数)
sql查询如下:
select psgCnt,count(*) from Rides group by psgCnt;

2.3 需求三(计算纽约市每个区域5分钟的进入车辆数)
首先需要知道一个经纬度是属于哪个区域的,这就需要再来一个UDF,如下:
public class ToAreaId extends ScalarFunction {
public int eval(float lon, float lat) {
return GeoUtils.mapToGridCell(lon, lat);
}
}
配置文件中定义如下:
functions:
- name: toAreaId
from: class
class: com.dataartisans.udfs.ToAreaId
sql实现如下:
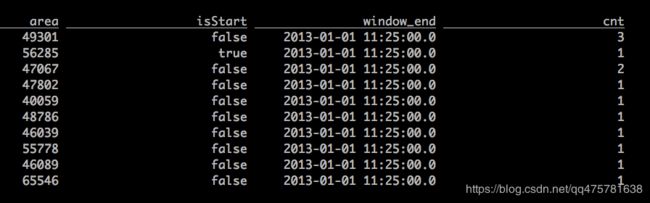
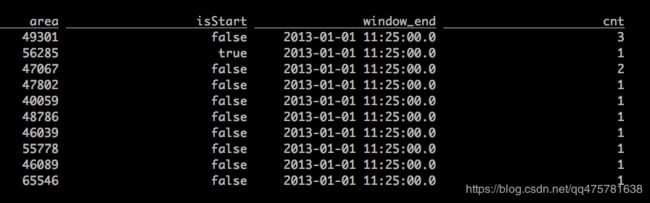
select
toAreaId(lon,lat) as area,
isStart,
TUMBLE_END(rideTime, INTERVAL '5' MINUTE) as window_end,
count(*) as cnt
from Rides
where isInNYC(lon,lat)
group by
toAreaId(lon,lat), isStart, TUMBLE(rideTime, INTERVAL '5' MINUTE);
2.4 需求四(将每10分钟搭乘的乘客总数写入Kafka)
首先我们需要定义一个kafka类型的sink表:
- name: Sink_TenMinPsgCnts #表名
type: sink
update-mode: append #追加模式
schema:
- name: cntStart #开始时间
type: TIMESTAMP
- name: cntEnd #结束时间
type: TIMESTAMP
- name: cnt #总数
type: LONG
connector:
property-version: 1
type: kafka
version: 0.11
topic: TenMinPsgCnts
startup-mode: earliest-offset
properties: #kafka配置
- key: zookeeper.connect
value: zookeeper:2181
- key: bootstrap.servers
value: kafka:9092
- key: group.id
value: trainingGroup
format:
property-version: 1
type: json
schema: "ROW(cntStart TIMESTAMP, cntEnd TIMESTAMP, cnt LONG)"
sql语句实现如下:
INSERT INTO Sink_TenMinPsgCnts
select
TUMBLE_START(rideTime, INTERVAL '10' MINUTE) as cntStart,
TUMBLE_END(rideTime, INTERVAL '10' MINUTE) as cntEnd,
cast(sum(psgCnt) as bigint) as cnt
from Rides
group by TUMBLE(rideTime, INTERVAL '10' MINUTE);
也可以打开kafka consumer的client查看数据进入情况
docker-compose exec sql-client /opt/kafka-client/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic TenMinPsgCnts --from-beginning
2.5 需求五(将每个区域出发的行车数写入到ES)
首先我们需要定义一个Es类型的sink表:
- name: Sink_AreaCnts
type: sink
update-mode: upsert
schema:
- name: areaId
type: INT
- name: cnt
type: LONG
connector:
type: elasticsearch
version: 6
hosts:
- hostname: "elasticsearch"
port: 9200
protocol: "http"
index: "area-cnts"
document-type: "areacnt"
key-delimiter: "$"
format:
property-version: 1
type: json
schema: "ROW(areaId INT, cnt LONG)"
sql语句执行如下:
insert into Sink_AreaCnts
select toAreaId(lon,lat) as areaId,
count(*) as cnt
from Rides
where isStart
group by toAreaId(lon,lat);
可以访问ES的地址http://localhost:9200/_search?pretty=true查看数据的插入情况。