Python探索性数据分析,这样才容易掌握

作者 | Riti Dass
译者 | LJY
整理 | Lemonbit
译文来源 | Python数据之道(ID:PythonDataLab)
导语:理解你的数据的最佳方法是花时间去研究它。
Python探索性数据分析教程
介绍
每个数据科学家都必须掌握的最重要的技能之一是正确研究数据的能力。彻底的探索性数据分析 (EDA, Exploratory Data Analysis) 是必要的,这是为了确保收集数据和执行分析的完整性。
本教程使用的示例是对历史上 SAT 和 ACT 数据的探索性分析,以比较不同州 SAT 和 ACT 考试的参与度和表现。在本教程的最后,我们将获得关于美国标准化测试的潜在问题的数据驱动洞察力。本教程的重点是演示探索性数据分析过程,并为希望练习使用数据的 Python 程序员提供一个示例。
为了这个分析,我在 Jupyter 中检查和操作了包含 2017 年和 2018 年 SAT 和 ACT 数据的 CSV 数据文件。通过构造良好的可视化和描述性统计来研究数据,是了解你正在处理的数据并根据你的观察制定假设的绝佳方法。
探索性数据分析(EDA)目标
1)快速描述一份数据集:行/列数、数据丢失情况、数据的类型、数据预览。
2)清除脏数据:处理丢失的数据、无效的数据类型和不正确的值。
3)可视化数据分布:条形图,直方图,箱型图等。
4)计算并可视化展示变量之间的相关性(关系):热图 (heatmap)。
数据驱动方法的好处
标准化测试程序多年来一直是一个有争议的话题, 已经为众人所知。通过初步研究,我很快发现了 SAT 和 ACT 考试中一些明显的问题。
例如,有些州只要求学生参加 SAT,有些州只要求学生参加 ACT,有些州要求学生两种考试都要参加,还有些州要求选择性标准化考试,或者每个学生都必须参加他们选择的一种标准化考试。
每个州制定的标准化考试预期之间的这种差异,应该被视为州与州之间考试记录存在偏差的一个重要来源,比如参与率和平均成绩。研究可能是重要的,但采取数据驱动的方法来支持基于定性研究的主张(假设)是必要的。采用数据驱动的方法可以验证以前提出的断言/假设,并基于对数据的彻底检查和操作开发新的见解。
入门
请从 GitHub 链接:
https://github.com/cbratkovics/satactanalysis
下载代码或数据,以方便跟随教程:
使用 Python 研究数据的第一步是确保导入了正确的库。
在本文中,我们需要的库是 NumPy,Pandass,Matplotlib 和 Seaborn。导入库时,可以为其分配别名,以减少使用每个库属性所需的键入量。下面的代码显示了必要的 import 语句:

使用 Pandas 库,你可以将数据文件加载到容器对象(称为数据帧, dataframe)中。顾名思义,这种类型的容器是一个框架,它使用 Pandas 方法 pd.read_csv() 读入的数据,该方法是特定于 CSV 文件的。将每个 CSV 文件转换为 Pandas 数据帧对象如下图所示:

检查数据 & 清理脏数据
在进行探索性分析时,了解您所研究的数据是很重要的。幸运的是,数据帧对象有许多有用的属性,这使得这很容易。当基于多个数据集之间比较数据时,标准做法是使用(.shape)属性检查每个数据帧中的行数和列数。如图所示:

注意:左边是行数,右边是列数;(行、列)。
我们这份数据的第一个问题是 ACT 2017 和 ACT 2018 数据集的维度不一致。让我们使用( .head() )来更好地查看数据,通过 Pandas 库展示了每一列的前五行,前五个标签值。我将以 2018 年 ACT 数据为例:

在预览了其他数据的前五行之后,我们推断可能存在一个问题,即各个州的数据集是如何存入的。由于美国有 51 个州,ACT 2017 和 ACT 2018 的“州”栏中很可能有错误或重复的值。然而,在处理数据时,我们不能确定这种推断。我们需要检查有关的数据来确定确切的问题。
首先,让我们使用 .value_counts() 方法检查 ACT 2018 数据中 “State” 列的值,该方法按降序显示数据帧中每个特定值出现的次数:

请注意:“Maine” 在 2018 年 ACT 数据中出现了两次。下一步是确定这些值是重复的还是数据输入不正确引起的。我们将使用一种脱敏技术来实现这一点,它允许我们检查满足指定条件的数据帧中的行。例如,让我们脱敏来查看 2018 ACT 数据中所有 “State” 值为 “Maine” 的行:

现在,已将乱码确认为重复条目。因此,我们可以使用 .drop() 方法,简单地删除值,使用 .reset_index()* 重置数据帧索引,来解决这个问题:
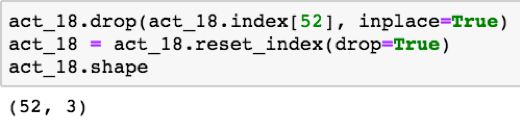
现在我们已经解决了 ACT 数据帧之间行数不一致的问题,然而 SAT 和 ACT 数据帧之间仍然存在行数不一致的问题( ACT 52 行,SAT 51 行)。为了比较州与州之间 SAT 和 ACT 数据,我们需要确保每个州在每个数据帧中都被平等地表示。这是一次创新的机会来考虑如何在数据帧之间检索 “State” 列值、比较这些值并显示结果。我的方法如下图展示:

函数 compare_values() 从两个不同的数据帧中获取一列,临时存储这些值,并显示仅出现在其中一个数据集中的任何值。让我们来看看在比较 2017 年和 2018 年 SAT/ACT “State” 列值时,它是如何工作的:

好吧!现在我们知道,需要删除 ACT 数据集中 “State” 列中的 “National” 值。这可以使用与我们在 2018 年 ACT 数据集 定位和删除重复的 ‘Maine’ 值相同的代码来完成:
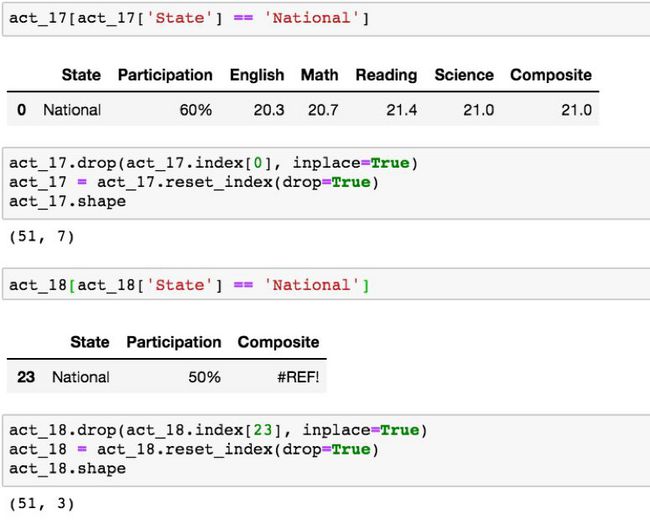
然而,在 2018 年 SAT 和 ACT 数据中仍存在关于 ‘Washington, D.C.’ 和 ‘District of Columbia’ 另一种争议。我们需要从四个数据集中确定能代表华盛顿特区/哥伦比亚特区的一贯值。你所做的选择在这两个选项中都不重要,但是最好选择在数据集中出现率最高的名称。由于 2017 年 SAT 和 2017 年 ACT “州”数据的唯一区别在于“国家”值,我们可以假设'华盛顿特区'和'哥伦比亚特区'在两个数据中的'州'列中是一致的。让我们使用脱敏技术来检查 ‘Washington, D.C.’ 和 ‘District of Columbia’ 哪些值出现在 ACT 2017 的‘State’ 一列中:

现在我们有理由详细在 ACT 2018 数据集中使用 ‘District of Columbia’ 取代 ‘Washington, D.C.’ 是正确的,通过使用 Pandas 库中的 .replace() 函数,我们就可以做到这一点。然后,我们可以使用 compare_values 函数确认我们的更改是否成功:
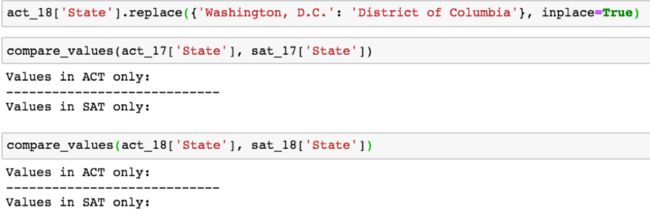
成功了!各个州的值现在在每个数据集是一致的。现在,我们可以解决 ACT 数据集中各个列不一致的问题。让我们使用 .columns 属性比较每个数据帧之间的列名:
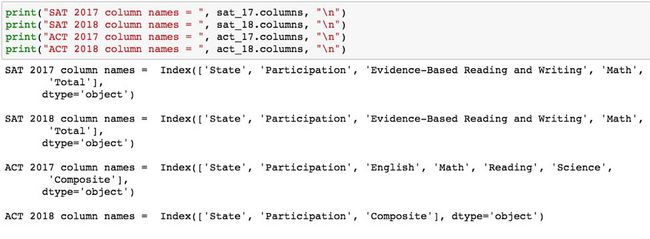
请注意,在显示 print()的输出后,添加 “\ n” 表达式会打印一个新行。
由于这次分析的目的是比较 SAT 和 ACT 数据,我们越能相似地表示每个数据集的值,我们的分析就越有帮助。
因此,我将在每个数据帧中保留的唯一列是 “State”、“Participation”、“Total” (仅SAT) 和 “Composite” (仅ACT)。
请注意,如果你的分析目标是不同的,比如比较 2017 年和 2018 年 SAT 的绩效,那么根据每个表现类别 (e.g. Math) 保存特定的数据将是至关重要的。为了与当前的任务保持一致,我们可以使用 .drop() 方法删除多余的列,如下所示:

现在所有的数据都具有相同的维度! 不幸的是,仍有许多工作要做。让我们看看是否有数据丢失,并查看所有数据的数据类型:

使用 .isnull().sum() 检查丢失的数据

用 .dtypes 检查数据类型
好消息是数据中不存在不存在的值。坏消息是存在数据类型的错误,特别是每个数据帧中的“参与”列都是对象类型,这意味着它被认为是一个字符串。这是有问题的,因为在研究数据时要观察许多有用的可视化,需要数字类型变量才能发挥作用,比如热力图、箱形图和直方图。
同样的问题也出现在两个 ACT 数据集的 ‘Composite’ 列中。让我们来看看 2018 年 SAT 和 ACT 数据的前五行:

2018 年 SAT 数据的前 5 行
2018 ACT 前 5 行数据
你可以看到 “Composite” 和 “Participation” 应该是 float 类型。好的做法是保持要比较的数值数据类型的一致性,因此将 “Total” 转换为 float 类型也是可以接受的,而不会损害数据的完整性(integer = 1166, float = 1166.0)。
这种类型转换的第一步是从每个 ’Participation’ 列中删除 “%” 字符,以便将它们转换为浮点数。下一步将把除每个数据帧中的 “State” 列之外的所有数据转换为浮点数。这可能是乏味的,这给了我们另一个创建函数来节省时间的好机会!我的解决方案如下函数所示:

是时候让这些功能发挥作用了。首先让我们使用 fix_participation() 函数:

现在我们可以使用 convert_to_float() 函数转换所有列的数据类型:

但是等等!运行 convert_to_float() 函数应该会抛出一个错误。错误消息是否有用取决于你使用的 IDE。在 Jupyter Notebook 中,错误将清楚地指引你到 ACT 2017 数据集中的 “Composite” 列。要更仔细地查看这些值,可以使用 .value_counts() 函数:

看起来我们的罪魁祸首是数据中的一个 “x” 字符,很可能是在将数据输入到原始文件时输入错误造成的。要删除它,可以在 .apply() 方法中使用 .strip() 方法,如下所示:
![]()
太棒了!现在再试着运行这段代码,所有的数据都是正确的类型:
在开始可视化数据之前的最后一步是将数据合并到单个数据中。为了实现这一点,我们需要重命名每个数据中的列,以描述它们各自代表的内容。
例如,2018 年 SAT ‘Participation’ 一栏的一个好名字应该是 “satparticipation17”。当数据合并时,这个名称更具描述性。
另一个注意事项是下划线表示法,以消除访问值时繁琐的间距错误,以及用于加速键入的小写约定。数据的命名约定由开发人员决定,但是许多人认为这是一种很好的实践。你可以这样重命名列:

为了合并数据而没有错误,我们需要对齐 “state” 列的索引,以便在数据帧之间保持一致。我们通过对每个数据集中的 “state” 列进行排序,然后从 0 开始重置索引值:

最后,我们可以合并数据。我没有一次合并所有四个数据帧,而是按年一次合并两个数据帧,并确认每次合并都没有出现错误。下面是每次合并的代码:

2017 SAT 与 ACT 合并的数据集

2018 年 SAT 和 ACT 合并数据框架。

最终合并数据集。
一旦你清理了你的数据,保存它是一个好主意,这样你就不用再去整理它了。使用 Pandas 中的 pd.to_csv() 方法:
![]()
设置 index = False 保存没有索引值的数据。
是时候可视化呈现数据了!现在,我们可以使用 Matplotlib 和 Seaborn 更仔细地查看我们已经清洗和组合的数据。在研究直方图和箱形图时,我将着重于可视化参与率的分布。在研究热图时,将考虑所有数据之间的关系。
可视化数据分布- Seaborn 直方图
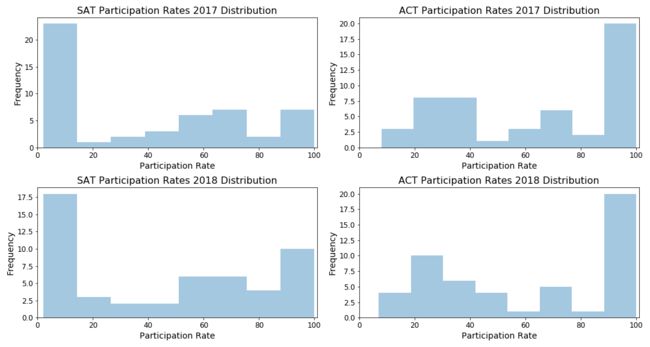
直方图表示数值数据值出现在数据集中指定范围内的频率(例如,数据中有多少值出现在 40%-50% 的范围内)。从直方图中我们可以看出,2017 年和 2018 年,ACT 的参与率在 90%-100% 之间的州更多。相反,2017 年和 2018 年 SAT 考试的参与率为 0 -10% 的州更多。我们可以推断,90%-100% ACT 参与率的州出现频率较高,可能是由于需要采取 ACT 的某些规定引起的。
可视化数据分布- Matplotlib 框图
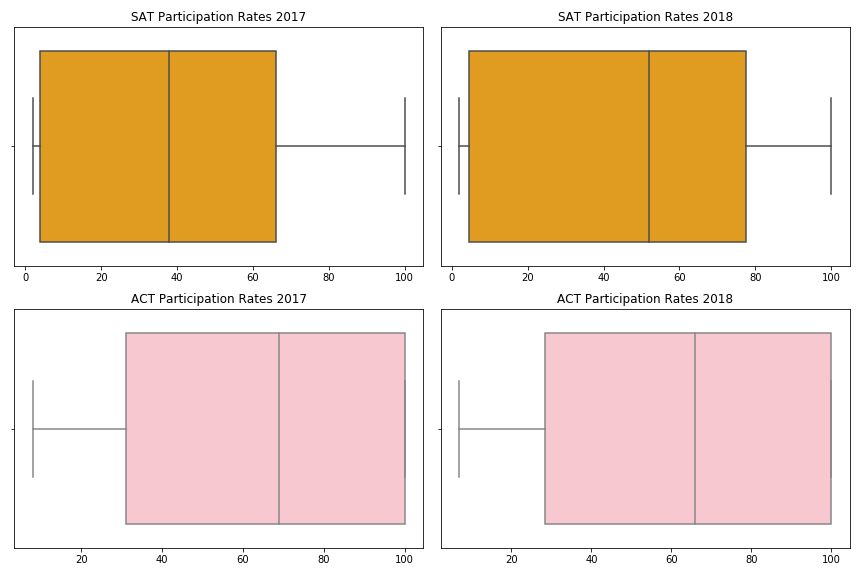
箱形图表示数据的扩展,包括最小、最大和四分位数范围(IQR)。四分位数范围由第一分位数、中位数和第三分位数组成。从上面的方框图可以看出,2017 年到 2018 年 SAT 的整体参与率有所上升。
我们可以注意到的另一件事是 2017 年到 2018 年 ACT 参与率的一致性。这就提出了一个问题,为什么 SAT 的参与率总体上有所上升,尽管 ACT 的参与率并没有显著变化。
计算并可视化相关性-Seaborn Heat Map

更强的关系由热图中的值表示,更接近于负值或正值。较弱的关系由接近于零的值表示。正相关变量,即零和正相关的值,表示一个变量随着另一个变量的增加而增加。负相关变量,负1和0之间的相关性值表示一个变量随着另一个变量的增加而减少。
需要进一步研究的关系较强的变量包括 2017 年 SAT 参与情况和 2018 年 SAT 参与情况、2017 年 ACT 综合得分和 2017 年 ACT 参与情况、2018 年 ACT 参与情况和 2018 年 SAT 参与情况。还有很多关系需要进一步研究,但这些都是很好的起点,可以指导研究为什么这些关系会存在。
总结
彻底的探索性数据分析可确保你的数据清晰,可用,一致且直观可视化。请记住,没有所谓的干净数据,因此在开始使用数据之前探索数据是在数据分析过程中添加完整性和价值的好方法。通过对数据的深入研究来指导外部研究,你将能够有效地获得可证明的见解。
文章来源:
https://towardsdatascience.com/exploratory-data-analysis-tutorial-in-python-15602b417445
(*本文为Python大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
由易观携手CSDN联合主办的第三届易观算法大赛正在火热进行中!冠军奖3万元,每人最多邀请5位用户组队参赛。本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。
推荐阅读
Python内存分配时的小秘密
吐血整理!140种Python标准库、第三方库和外部工具都有了
如何用爬虫技术帮助孩子秒到心仪的幼儿园(基础篇)
Python传奇:30年崛起之路
干货 | Python后台开发的高并发场景优化解决方案
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
阿里巴巴杨群:高并发场景下Python的性能挑战
![]()
你点的每个“在看”,我都认真当成了喜欢