Flink在美团的实践与应用
作者: 刘迪珊
本文整理自8月11日在北京举行的Flink Meetup,分享嘉宾刘迪珊(2015年加入美团数据平台。致力于打造高效、易用的实时计算平台,探索不同场景下实时应用的企业级解决方案及统⼀化服务)。
美团实时计算平台现状和背景
实时平台架构
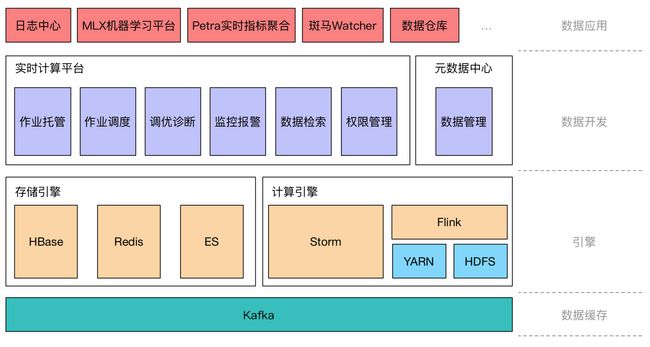
上图呈现的是当前美团实时计算平台的简要架构。最底层是数据缓存层,可以看到美团测的所有日志类的数据,都是通过统一的日志收集系统收集到Kafka。Kafka作为最大的数据中转层,支撑了美团线上的大量业务,包括离线拉取,以及部分实时处理业务等。在数据缓存层之上,是一个引擎层,这一层的左侧是我们目前提供的实时计算引擎,包括Storm和Flink。Storm在此之前是 standalone 模式的部署方式,Flink由于其现在运行的环境,美团选择的是On YARN模式,除了计算引擎之外,我们还提供一些实时存储功能,用于存储计算的中间状态、计算的结果、以及维度数据等,目前这一类存储包含Hbase、Redis以及ES。在计算引擎之上,是趋于五花八门的一层,这一层主要面向数据开发的同学。实时数据开发面临诸多问题,例如在程序的调试调优方面就要比普通的程序开发困难很多。在数据平台这一层,美团面向用户提供的实时计算平台,不仅可以托管作业,还可以实现调优诊断以及监控报警,此外还有实时数据的检索以及权限管理等功能。除了提供面向数据开发同学的实时计算平台,美团现在正在做的事情还包括构建元数据中心。这也是未来我们想做SQL的一个前提,元数据中心是承载实时流系统的一个重要环节,我们可以把它理解为实时系统中的大脑,它可以存储数据的Schema,Meta。架构的最顶层就是我们现在实时计算平台支撑的业务,不仅包含线上业务日志的实时查询和检索,还涵盖当下十分热门的实时机器学习。机器学习经常会涉及到搜索和推荐场景,这两个场景最显著特点:一、会产生海量实时数据;二、流量的QPS相当高。此时就需要实时计算平台承载部分实时特征的提取工作,实现应用的搜索推荐服务。还有一类是比较常见的场景,包括实时的特征聚合,斑马Watcher(可以认为是一个监控类的服务),实时数仓等。
以上就是美团目前实时计算平台的简要架构。
实时平台现状
美团实时计算平台的现状是作业量现在已经达到了近万,集群的节点的规模是千级别的,天级消息量已经达到了万亿级,高峰期的消息量能够达到千万条每秒。

痛点和问题
美团在调研使用Flink之前遇到了一些痛点和问题:
-
实时计算精确性问题:在调研使用Flink之前美团很大规模的作业是基于Storm去开发的,Storm主要的计算语义是At-Least-Once,这种语义在保证正确性上实际上是有一些问题的,在Trident之前Storm是无状态的处理。虽然Storm Trident提供了一个维护状态的精确的开发,但是它是基于串行的Batch提交的,那么遇到问题在处理性能上可能会有一点瓶颈。并且Trident是基于微批的处理,在延迟上没有达到比较高的要求,所以不能满足一些对延迟比较高需求的业务。
-
流处理中的状态管理问题:基于之前的流处理过程中状态管理的问题是非常大的一类问题。状态管理除了会影响到比如说计算状态的一致性,还会影响到实时计算处理的性能以及故障恢复时候的能力。而Flink最突出的一个优势就是状态管理。
-
实时计算表义能力的局限性:在实时计算之前很多公司大部分的数据开发还是面向离线的场景,近几年实时的场景也慢慢火热起来了。那与离线的处理不同的是,实时的场景下,数据处理的表意能力可能有一定的限制,比如说他要进行精确计算以及时间窗口都是需要在此之上去开发很多功能性的东西。
-
开发调试成本高:近千结点的集群上已经跑了近万的作业,分布式的处理的引擎,手工写代码的方式,给数据开发的同学也带来了很高开发和调试的成本,再去维护的时候,运维成本也比较高。
Flink探索关注点
在上面这些痛点和问题的背景下,美团从去年开始进行Flink的探索,关注点主要有以下4个方面:
-
ExactlyOnce计算能力
-
状态管理能力
-
窗口/Join/时间处理等等
-
SQL/TableAPI
Flink在美团的实践
下面带大家来看一下,美团从去年投入生产过程中都遇到了哪些问题,以及一些解决方案,分为下面三个部分:
稳定性实践
稳定性实践-资源隔离
1.资源隔离的考虑:分场景、按业务
-
高峰期不同,运维时间不同;
-
可靠性、延迟需求不同;
-
应用场景,重要性不同;
2.资源隔离的策略:
-
YARN打标签,节点物理隔离;
-
离线DataNode与实时计算节点的隔离;

稳定性实践-智能调度
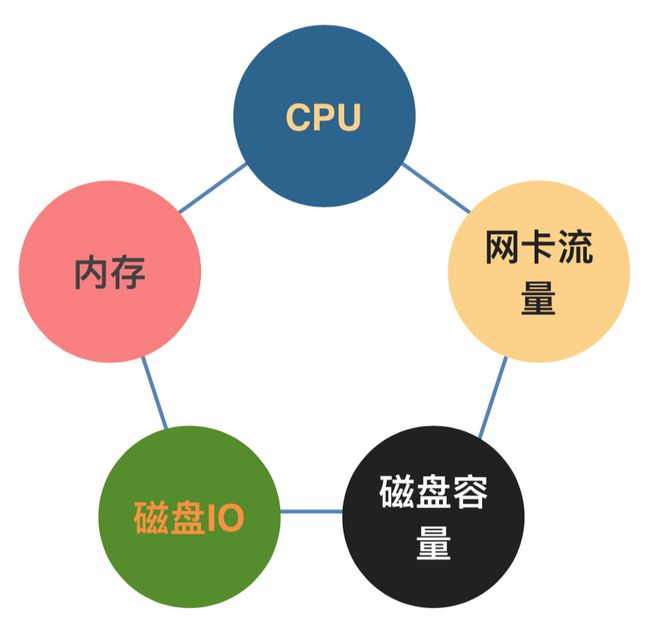
智能调度目的也是为了解决资源不均的问题,现在普通的调度策略就是基于CPU,基于内存去调度的。除此之外,在生产过程中也发现了一些其他的问题,比如说Flink是会依赖本地磁盘,进行依赖本地磁盘做本地的状态的存储,所以磁盘IO,还有磁盘的容量,也是一类考虑的问题点,除此之外还包括网卡流量,因为每个业务的流量的状态是不一样的,分配进来会导致流量的高峰,把某一个网卡打满,从而影响其他业务,所以期望的话是说做一些智能调度化的事情。目前暂时能做到的是从cpu和内存两方面,未来会从其他方面做一些更优的调度策略。
稳定性实践-故障容错
1.节点/网络故障
-
JobManagerHA
-
自动拉起
与Storm不同的是,知道Storm在遇到异常的时候是非常简单粗暴的,比如说有发生了异常,可能用户没有在代码中进行比较规范的异常处理,但是没有关系,因为worker会重启作业还会继续执行,并且他保证的是At-Least-Once这样的语义,比如说一个网络超时的异常对他而言影响可能并没有那么大,但是Flink不同的是他对异常的容忍度是非常的苛刻的,那时候就考虑的是比如说会发生节点或者是网络的故障,那JobManager单点问题可能就是一个瓶颈,JobManager那个如果挂掉的话,那么可能对整个作业的影响就是不可回复的,所以考虑了做HA,另外一个就是会去考虑一些由于运维的因素而导致的那作业,还有除此之外,可能有一些用户作业是没有开启CheckPoint,但如果是因为节点或者是网络故障导致挂掉,希望会在平台内层做一些自动拉起的策略,去保证作业运行的稳定性。
2.上下游容错
- FlinkKafka08异常重试
我们的数据源主要是Kafka,读写Kafka是一类非常常见的实时流处理避不开的一个内容,而Kafka本身的集群规模是非常比较大的,因此节点的故障出现是一个常态问题,在此基础上我们对节点故障进行了一些容错,比如说节点挂掉或者是数据均衡的时候,Leader会切换,那本身Flink的读写对Leader的切换容忍度没有那么高,在此基础上我们对一些特定场景的,以及一些特有的异常做的一些优化,进行了一些重试。
3.容灾
-
多机房
-
流热备
容灾可能大家对考虑的并不多,比如说有没有可能一个机房的所有的节点都挂掉了,或者是无法访问了,虽然它是一个小概率的事件,但它也是会发生的。所以现在也会考虑做多机房的一些部署,包括还有Kafka的一些热备。
Flink平台化
Flink平台化-作业管理
在实践过程中,为了解决作业管理的一些问题,减少用户开发的一些成本,我们做了一些平台化的工作,下图是一个作业提交的界面展示,包括作业的配置,作业生命周期的管理,报警的一些配置,延迟的展示,都是集成在实时计算平台的。
Flink平台化-监控报警
在监控上我们也做了一些事情,对于实时作业来讲,对监控的要求会更高,比如说在作业延迟的时候对业务的影响也比较大,所以做了一些延迟的报警,包括作业状态的报警,比如说作业存活的状态,以及作业运行的状态,还有未来会做一些自定义Metrics的报警。自定义Metrics是未来会考虑基于作业处理本身的内容性,做一些可配置化的一些报警。
Flink平台化-调优诊断
-
实时计算引擎提供统一日志和Metrics方案
-
为业务提供按条件过滤的日志检索
-
为业务提供自定义时间跨度的指标查询
-
基于日志和指标,为业务提供可配置的报警
另外就是刚刚提到说在开发实时作业的时候,调优和诊断是一个比较难的痛点,就是用户不是很难去查看分布式的日志,所以也提供了一套统一的解决方案。这套解决方案主要是针对日志和Metrics,会在针对引擎那一层做一些日志和Metrics的上报,那么它会通过统一的日志收集系统,将这些原始的日志,还有Metrics汇集到Kafka那一层。今后Kafka这一层大家可以发现它有两个下游,一方面是做日志到ES的数据同步,目的的话是说能够进入日志中心去做一些日志的检索,另外一方面是通过一些聚合处理流转到写入到OpenTSDB把数据做依赖,这份聚合后的数据会做一些查询,一方面是Metrics的查询展示,另外一方面就是包括实做的一些相关的报警。
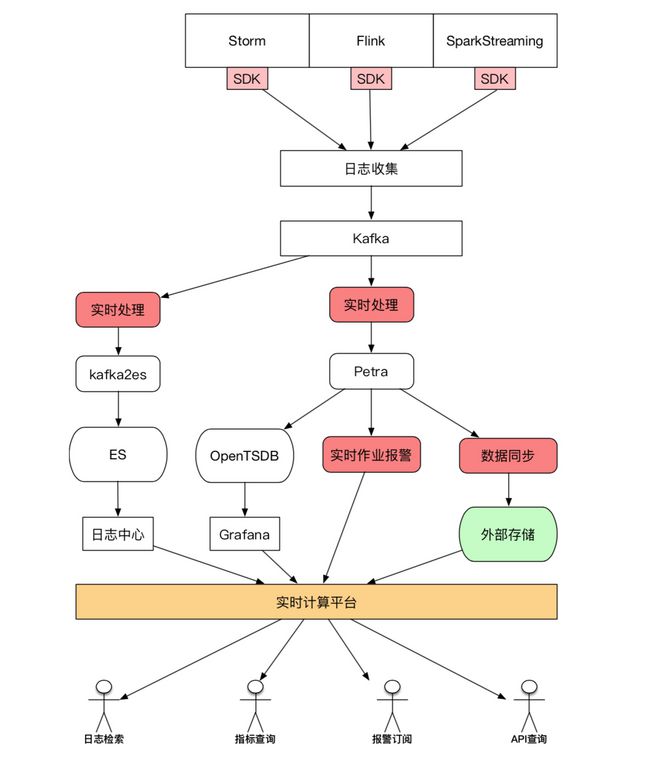
下图是当前某一个作业的一个可支持跨天维度的Metrics的一个查询的页面。可以看到说如果是能够通过纵向的对比,可以发现除了作业在某一个时间点是因为什么情况导致的?比如说延迟啊这样容易帮用户判断一些他的做作业的一些问题。除了作业的运行状态之外,也会先就是采集一些节点的基本信息作为横向的对比
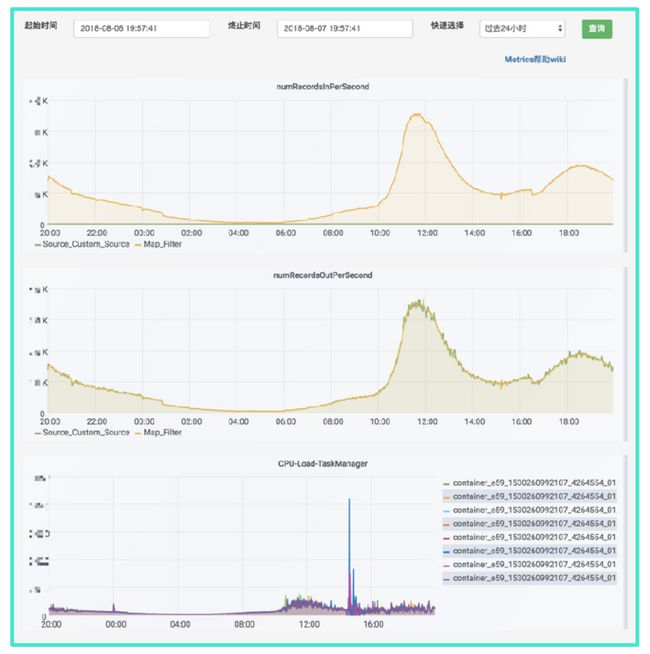
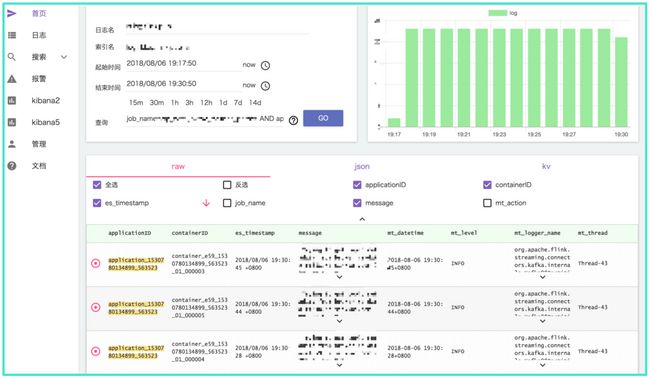
下图是当前的日志的一些查询,它记录了,因为作业在挂掉之后,每一个ApplicationID可能会变化,那么基于作业唯一的唯一的主键作业名去搜集了所有的作业,从创建之初到当前运行的日志,那么可以允许用户的跨Application的日志查询。
生态建设
为了适配这两类MQ做了不同的事情,对于线上的MQ,期望去做一次同步多次消费,目的是避免对线上的业务造成影响,对于的生产类的Kafka就是线下的Kafka,做了一些地址的地址的屏蔽,还有基础基础的一些配置,包括一些权限的管理,还有指标的采集。
Flink在美团的应用
下面会给大家讲两个Flink在美团的真实使用的案例。第一个是Petra,Petra其实是一个实时指标的一个聚合的系统,它其实是面向公司的一个统一化的解决方案。它主要面向的业务场景就是基于业务的时间去统计,还有计算一些实时的指标,要求的话是低时延,他还有一个就是说,因为它是面向的是通用的业务,由于业务可能是各自会有各自不同的维度,每一个业务可能包含了包括应用通道机房,还有其他的各自应用各个业务特有的一些维度,而且这些维度可能涉及到比较多,另外一个就是说它可能是就是业务需要去做一些复合的指标的计算,比如说最常见的交易成功率,他可能需要去计算支付的成功数,还有和下单数的比例。另外一个就是说统一化的指标聚合可能面向的还是一个系统,比如说是一些B端或者是R段的一些监控类的系统,那么系统对于指标系统的诉求,就是说我希望指标聚合能够最真最实时最精确的能够产生一些结果,数据保证说它的下游系统能够真实的监控到当前的信息。右边图是我当一个Metrics展示的一个事例。可以看到其他其实跟刚刚讲也是比较类似的,就是说包含了业务的不同维度的一些指标汇聚的结果。
Petra实时指标聚合
1.业务场景:
-
基于业务时间(事件时间)
-
多业务维度:如应用、通道、机房等
-
复合指标计算:如交易成功率=支付成功数/下单数
-
低延迟:秒级结果输出
2.Exactlyonce的精确性保障
- Flinkcheckpoint机制
3.维度计算中数据倾斜
- 热点key散列
4.对晚到数据的容忍能力
- 窗口的设置与资源的权衡
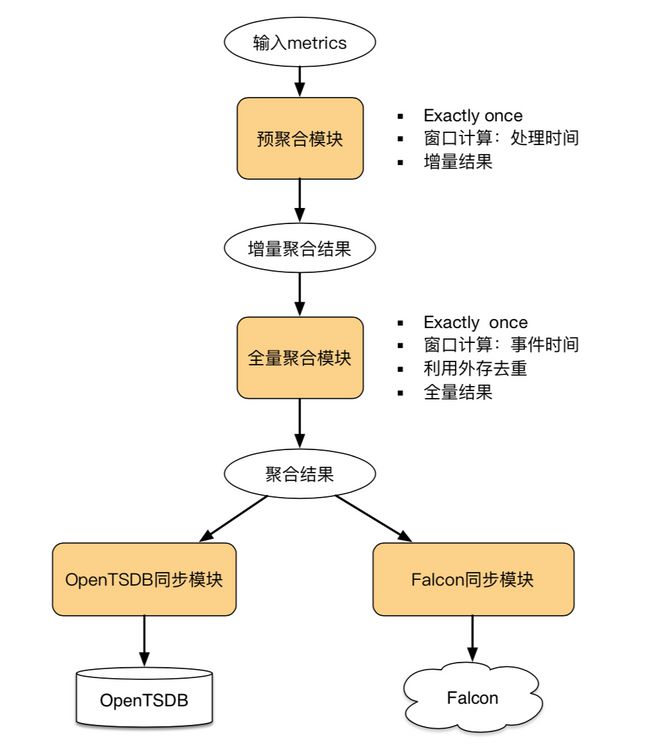
在用Flink去做实时指标复核的系统的时候,着重从这几方面去考虑了。第一个方面是说精确的计算,包括使用了FLink和CheckPoint的机制去保证说我能做到不丢不重的计算,第一个首先是由统一化的Metrics流入到一个预聚合的模块,预聚合的模块主要去做一些初始化的一些聚合,其中的为什么会分预聚合和全量聚合主要的解决一类问题,包括就刚刚那位同学问的一个问题,就是数据倾斜的问题,比如说在热点K发生的时候,当前的解决方案也是通过预聚合的方式去做一些缓冲,让尽量把K去打散,再聚合全量聚合模块去做汇聚。那其实也是只能解决一部分问题,所以后面也考虑说在性能的优化上包括去探索状态存储的性能。下面的话还是包含晚到数据的容忍能力,因为指标汇聚可能刚刚也提到说要包含一些复合的指标,那么符合的指标所依赖的数据可能来自于不同的流,即便来自于同一个流,可能每一个数据上报的时候,可能也会有晚到的情况发生,那时候需要去对数据关联做晚到的容忍,容忍的一方面是说可以设置晚到的Lateness的延迟,另一方面是可以设置窗口的长度,但是其实在现实的应用场景上,其实还有一方面考虑就是说除了去尽量的去拉长时间,还要考虑真正的计算成本,所以在这方面也做了一些权衡,那么指标基本就是经过全量聚合之后,聚合结果会回写Kafka,经过数据同步的模块写到OpenTSDB去做,最后去grafana那做指标的展示,另一方面可能去应用到通过Facebook包同步的模块去同步到报警的系统里面去做一些指标,基于指标的报警。
下图是现在提供的产品化的Petra的一个展示的机示意图,可以看到目前的话就是定义了某一些常用的算子,以及维度的配置,允许用户进行配置话的处理,直接去能够获取到他期望要的指标的一个展示和汇聚的结果。目前还在探索说为Petra基于Sql做一些事情,因为很多用户也比较就是在就是习惯上也可以倾向于说我要去写Sql去完成这样的统计,所以也会基于此说依赖Flink的本身的对SQl还有TableAPI的支持,也会在Sql的场景上进行一些探索。
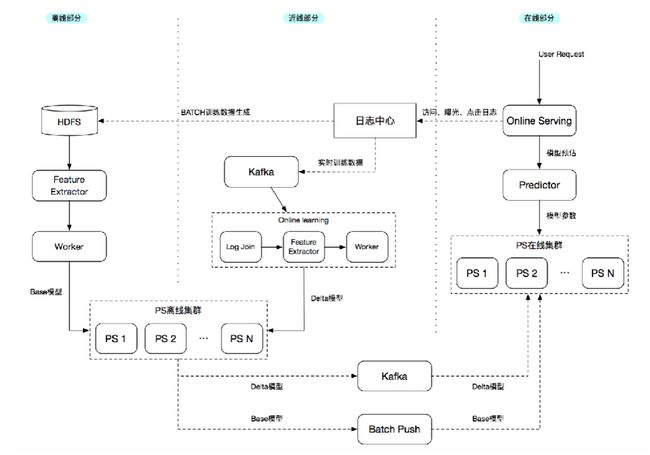
MLX机器学习平台
第二类应用就是机器学习的一个场景,机器学习的场景可能会依赖离线的特征数据以及实时的特征数据。一个是基于现有的离线场景下的特征提取,经过了批处理,流转到了离线的集群。另外一个就是近线模式,近线模式出的数据就是现有的从日志收集系统流转过来的统一的日志,经过Flink的处理,就是包括流的关联以及特征的提取,再做模型的训练,流转到最终的训练的集群,训练的集群会产出P的特征,还有都是Delta的特征,最终将这些特征影响到线上的线上的特征的一个训练的一个服务上。这是一个比较常见的,比如说比较就是通用的也是比较通用的一个场景,目前的话主要应用的方可能包含了搜索还有推荐,以及一些其他的业务。
未来展望
未来的话可能也是通过也是期望在这三方面进行做一些更多的事情,刚刚也提到了包括状态的管理,第一个是状态的统一的,比如说Sql化的统一的管理,希望有统一的配置,帮用户去选择一些期望的回滚点。另外一个就是大状态的性能优化,因为比如说像做一些流量数据的双流的关联的时候,现在也遇到了一些性能瓶颈的问题,对于说啊基于内存型的状态,基于内存型的数据的处理,以及基于RocksDB的状态的处理,做过性能的比较,发现其实性能的差异还是有一些大的,所以希望说在基于RocksDBBackend的上面能够去尽量去更多的做一些优化,从而提升作业处理的性能。第二方面就是Sql,Sql的话应该是每一个位就是当前可能各个公司都在做的一个方向,因为之前也有对Sql做一些探索,包括提供了基于Storm的一些Sql的表示,但是可能对于之前的话对于与语义的表达可能会有一些欠缺,所以希望说在基于Flink可去解决这些方面的事情,以及包括Sql的并发度的一些配置的优化,包括Sql的查询的一些优化,都希望说在Flink未来能够去优化更多的东西,去真正能使Sql应用到生产的环境。
另外一方面的话就是会进行新的场景的也在做新的场景的一些探索,期望是比如说包括刚刚也提到说除了流式的处理,也期望说把离线的场景下的数据进行一些合并,通过统一的Sql的API去提供给业务做更多的服务,包括流处理,还有批处理的结合。
更多资讯请访问 Apache Flink 中文社区网站