【机器学习】使用R语言进行机器学习特征选择
通过R语言进行机器学习中的特征选择
特征选择是实用机器学习的重要一步,一般数据集都带有太多的特征用于模型构建,如何找出有用特征是值得关注的重要内容。
基于caret包,使用递归特征消除法,其中rfe参数如下:
- x,预测变量的矩阵或数据框
- y,输出结果向量(数值型或因子型)
- sizes,用于测试的特定子集大小的整型向量
- rfeControl,用于指定预测模型和方法的一系列选项
一些列函数可以用于rfeControl$functions,包括:线性回归(lmFuncs),随机森林(rfFuncs),朴素贝叶斯(nbFuncs),bagged trees(treebagFuncs)和可以用于caret的train函数的函数(caretFuncs)。
移除冗余特征,移除高度关联的特征
set.seed(1234)
library(mlbench)
library(caret)
data(PimaIndiansDiabetes)
Matrix <- PimaIndiansDiabetes[,1:8]
library(Hmisc)
up_CorMatrix <- function(cor,p) {ut <- upper.tri(cor)
data.frame(row = rownames(cor)[row(cor)[ut]] ,
column = rownames(cor)[col(cor)[ut]],
cor =(cor)[ut] ) }
res <- rcorr(as.matrix(Matrix))
cor_data <- up_CorMatrix (res$r)
cor_data <- subset(cor_data, cor_data$cor > 0.5)
cor_data
row column cor
22 pregnant age 0.5443412
根据重要性进行特征排序
特征重要性可以通过构建模型获取。一些模型,诸如决策树,内建有特征重要性的获取机制。另一些模型,每个特征重要性利用ROC曲线分析获取。
下例加载Pima Indians Diabetes数据集,构建一个Learning Vector Quantization(LVQ)模型。varImp用于获取特征重要性。从图中可以看出glucose, mass和age是前三个最重要的特征,insulin是最不重要的特征。
# ensure results are repeatable
set.seed(1234)
# load the library
library(mlbench)
library(caret)
# load the dataset
data(PimaIndiansDiabetes)
# prepare training scheme
control <- trainControl(method="repeatedcv", number=10, repeats=3)
# train the model
model <- train(diabetes~., data=PimaIndiansDiabetes, method="lvq", preProcess="scale", trControl=control)
# estimate variable importance
importance <- varImp(model, scale=FALSE)
# summarize importance
print(importance)
# plot importance
plot(importance)
ROC curve variable importance
Importance
glucose 0.7881
mass 0.6876
age 0.6869
pregnant 0.6195
pedigree 0.6062
pressure 0.5865
triceps 0.5536
insulin 0.5379

特征选择
自动特征选择用于构建不同子集的许多模型,识别哪些特征有助于构建准确模型,哪些特征没什么帮助。特征选择的一个流行的自动方法称为 递归特征消除(Recursive Feature Elimination)或RFE。
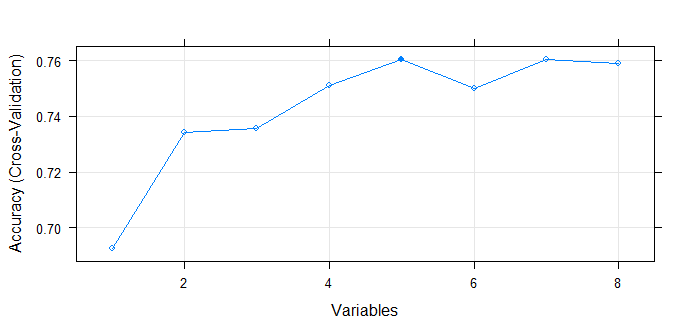
下例在Pima Indians Diabetes数据集上提供RFE方法例子。随机森林算法用于每一轮迭代中评估模型的方法。该算法用于探索所有可能的特征子集。从图中可以看出当使用5个特征时即可获取与最高性能相差无几的结果。
# ensure the results are repeatable
set.seed(7)
# load the library
library(mlbench)
library(caret)
# load the data
data(PimaIndiansDiabetes)
# define the control using a random forest selection function
control <- rfeControl(functions=rfFuncs, method="cv", number=10)
# run the RFE algorithm
results <- rfe(PimaIndiansDiabetes[,1:8], PimaIndiansDiabetes[,9], sizes=c(1:8), rfeControl=control)
# summarize the results
print(results)
# list the chosen features
predictors(results)
# plot the results
plot(results, type=c("g", "o"))
Recursive feature selection
Outer resampling method: Cross-Validated (10 fold)
Resampling performance over subset size:
Variables Accuracy Kappa AccuracySD KappaSD Selected
1 0.6926 0.2653 0.04916 0.10925
2 0.7343 0.3906 0.04725 0.10847
3 0.7356 0.4058 0.05105 0.11126
4 0.7513 0.4435 0.04222 0.09472
5 0.7604 0.4539 0.05007 0.11691 *
6 0.7499 0.4364 0.04327 0.09967
7 0.7603 0.4574 0.04052 0.09838
8 0.7590 0.4549 0.04804 0.10781
The top 5 variables (out of 5):
glucose, mass, age, pregnant, insulin
实例
1.特征工程概述
特征工程,即最大限度地从原始数据中提取有用信息以供算法和模型使用,通过寻求最优特征子集等方法使模型预测性能最高。
以经典的鸢尾花数据iris为例,分别根据已有的特征选择的框架图,结合网络上给出的python代码总结,添加了运用R实现特征选择的方法,来对比两种语言的差异。
1.导入数据
data("iris")
# 特征矩阵
iris.data <- iris[, -length(iris)]
# 目标向量
iris.targer <- iris[, length(iris)]
2.数据预处理
- 标准化(要求数据符合正态分布)
scale(iris.data, center = TRUE, scale = TRUE)
# 或者运用BBmisc包中的normalize函数
library(BBmisc)
normalize(iris.data)
- 放缩(依据公式构建区间放缩函数)
maxmin <- function(col) { maxmin <- (col - min(col))/(max(col) - min(col)) return(maxmin)} maxmin(iris.data) - 归一化
归一化是指依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。归一化后样本各属性的平方和为1。
norm <- function(data) {
norm = apply(data, 1, function(x) {
x/sqrt(sum(x^2))
})
norm = t(norm)
return(norm)}
norm(iris.data)
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布。
归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]区间内,因此区间放缩法是归一化的一种。
3.特征选择
Filter(过滤法):
按照变量内部特征或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数选择特征.与特定的学习算法无关,因此具有较好的通用性,作为特征的预筛选器非常合适。缺点主要是由于算法的评价标准独立于特定的学习算法,所选的特征子集在分类准确率方面通常低于Wrapper方法。
方差选择法:计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征.
library(mlr)
# 创建task
train.task <- makeClassifTask(data = iris, target = "Species")
# 查看变量选择可选方法listFilterMethods()
# 选择计算方差,进行特征选择
var_imp <- generateFilterValuesData(train.task, method = "variance", nselect = 3)
var_imp
# 对衡量特征指标进行绘图
plotFilterValues(var_imp, feat.type.cols = TRUE, n.show = 3)