mysql 读写分离 amoeba实现
读写分离 这里使用amoeba实现 amoeba是用java写的 所以必须先装好jdk 然后配好环境变量
我这里是在java官网下的jdl1.8 的rpm包 直接yum安装 默认安装在/usr/java/jdk1.8.0_161/
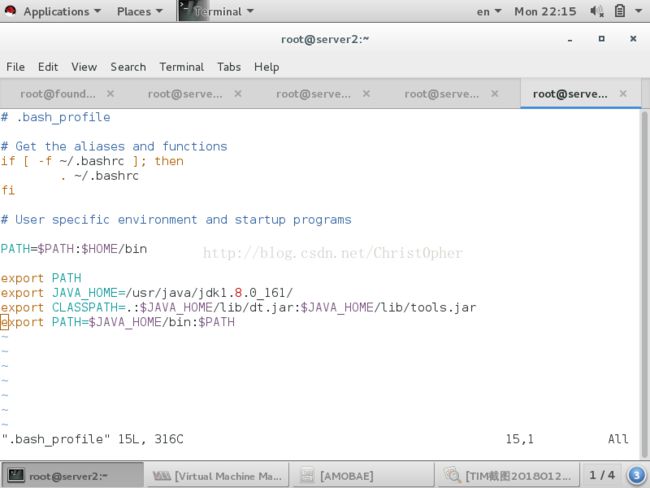
配好环境变量后 命令行 java -version 查看java版本
并且 java在命令行也可以补齐了
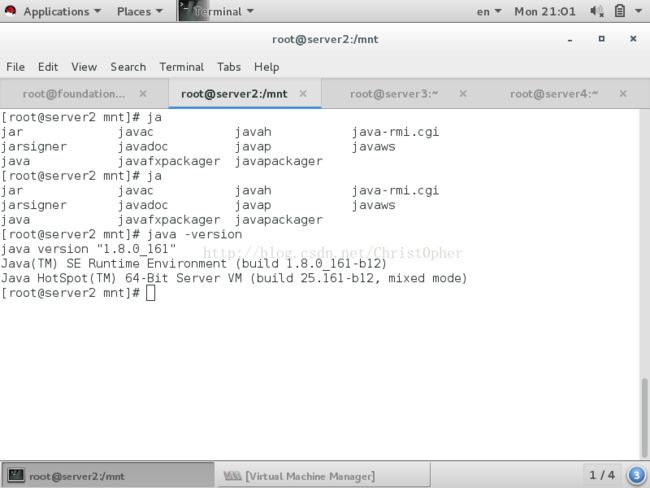
java弄好之后 我们要找到 amoeba的包 我这里是用的amoeba-mysql-3.0.5-RC 这个版本
本来有用的是2.0.1版本 但是当时启动amoeba的时候总是提示stack size too small at least 228k
然后解决方法是编辑amoeba安装目录下的一个 jvm.properties 这个文件 改一个-Xss196 的参数 改成 -Xss256
然而我在2.0.1的版本下并没有找到这个文件 很尬 所以使用了3.0.5版本 这个地方我觉得就是这个opensource作者的问题了
这个文件是amoeba自带的配置文件 跟jdk一点关系都没有 你用这个配置起得来你自己写的软件你自己不知道么?真的很无语
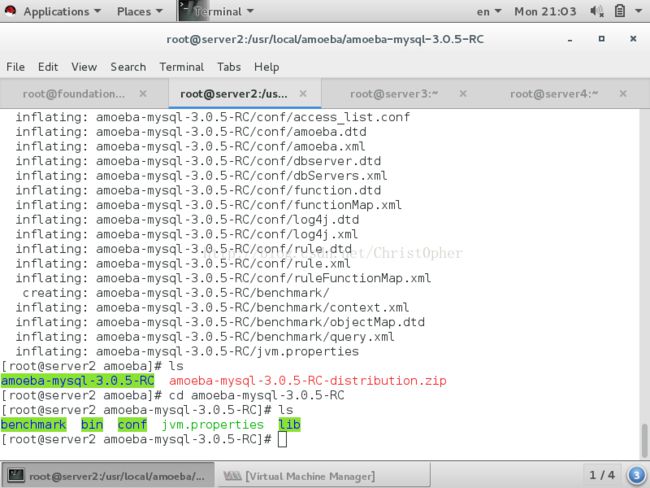
然后我们需要在主从数据库mysql上 建立一个供amoeba使用的至少可以远程连接的账户 这个账户很关键 一会会写进amoeba的.xml配置文件里面
注意 在所有的后端数据库上都必须建立这个账户 因为这是amoeba接受前端的请求后 在后端进行操作实际所使用的身份
那个db上没有 amoeba就访问操作不了这个db
关键的来了
然后我们要在amoeba上做配置了
cd /usr/loca/amoeba(这个是我amoeba的解压目录)
vim dbServer.xml #这个是amoeba的第一个关键配置文件
定义了 后端的节点 amoeba的访问 以及slave集群
要点1:
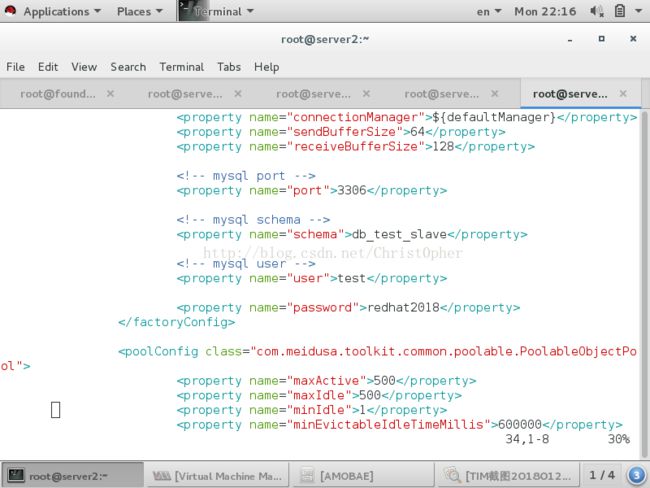
schema这个参数指定amoeba可以控制的库 这里amoeba是不能控制除了这个参数里写的库的其他的库 所以我们刚刚的用户授权也是基于这个库的
讲道理这里应该可写 * 表示 反正这里怎么写 授权就要怎么给
要点2:
紧随其后的user & password 参数 我们给的就是刚刚在所有后端授权建立的账户 的用户名 密码 这个是amoeba能成功访问后端的关键
要点3:
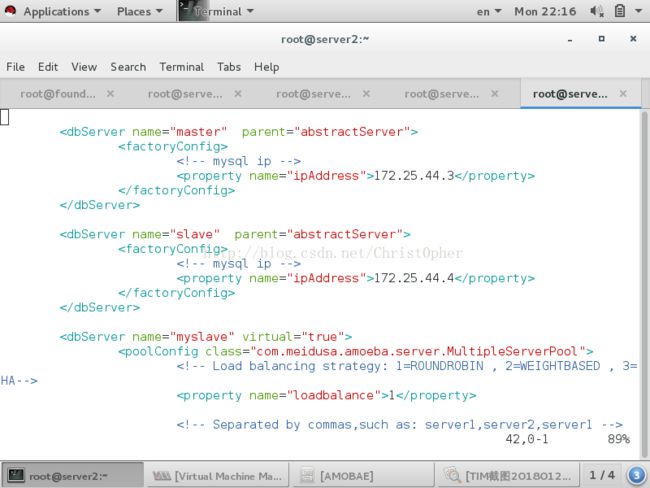
下面的dbServer语句块 定义了后端的节点库 这个名字可以随意 但是要和后面的 amoeba.xml里面的规则保持一致
我们在这里给出两个 一个master 以及它的IP ,一个slave 以及它的IP
要点4:
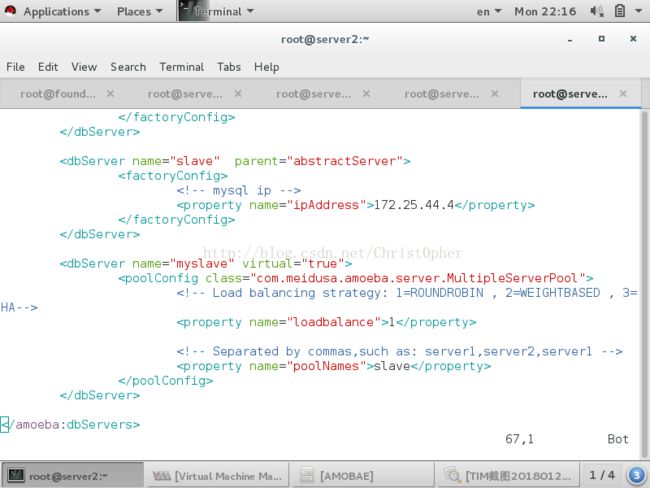
其实amoeba默认好像是用于这种一主多从模式的 配置文件默认有slave集群的语句块 并且还可以实现loadbalance
这里参数1 表示roundrobin 轮叫
这里也可以仿照这个模式定义master的集群 一样的
要是你有多个slave 可以按照注释那样 逗号隔开 全部加入 poolname这个参数后面 表示他加入这个池 多个master同理
至于哪个池怎么工作 则是在amoeba.xml里面定义
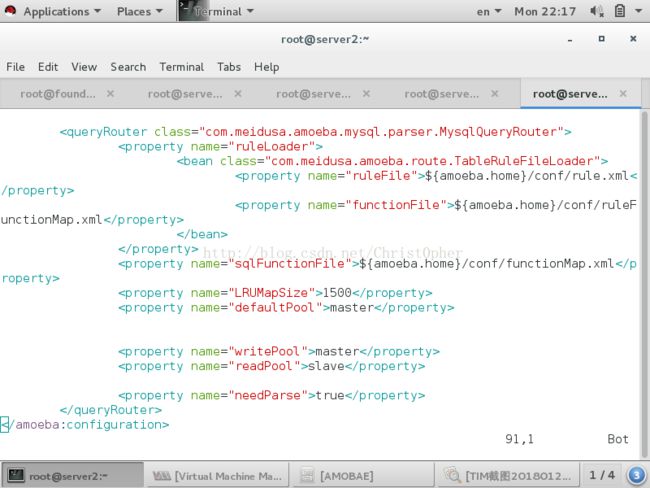
下面这个就是amoeba.xml的配置了
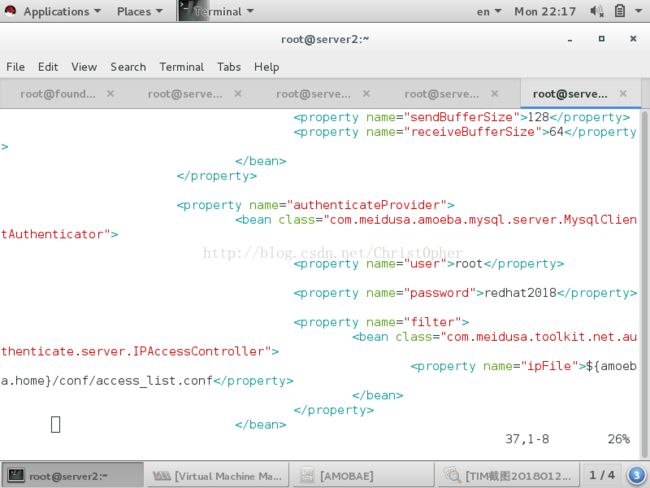
这里定义了 用户访问amoeba时候所用的虚拟账户 注意 这个账户是amoeba的账户 并不是真实的mysql的账户 只是用户用它登陆amoeba
amoeba相当于一个代理 将来就用这个虚拟的账户登陆amoeba 然后amoeba用上面授权了建立的真实数据库账户 在各个后端数据库里访问 操作
这一块 就是定义那个后端怎么工作了
defaultpool 表示默认池 默认其他操作在这个池中的后端数据库里面做
readpool 读池 writeool 写池
我这里只有两个数据库 就直接写上面dbServer里定义的server了 如果你上面定义了master&slave 池的话 这里写池也是可以的
然后我们到amoeba的安装目录下 cd /bin
直接./lancher 运行启动脚本
果不其然报错 栈空间不足 果断返回amoeba的主目录
vim jvm.properties 然后如下图设置参数
重新启动脚本
虽然他看上去好像有报错 但是确实启动了 /尬
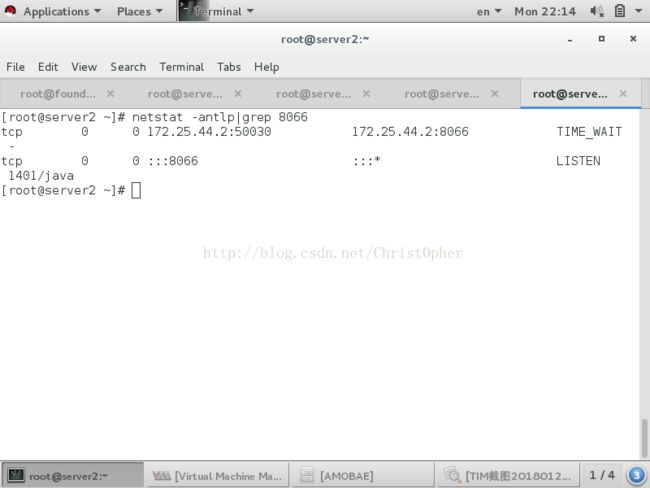
查看下amoeba的默认listen端口 没毛病
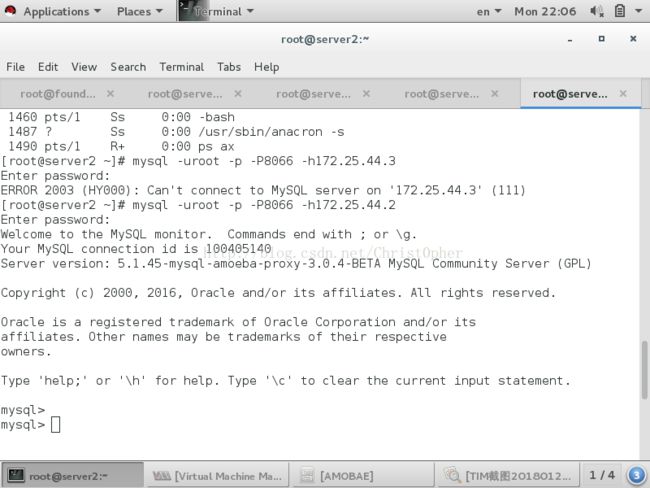
然后我们直接在安装amoeba的这台主机上 虽然没有装数据库 但居然能直接使用mysql 命令
直接远程登录 amoeba服务 使用amoeba虚拟账号 -P参数表示请求端口8066 必加!
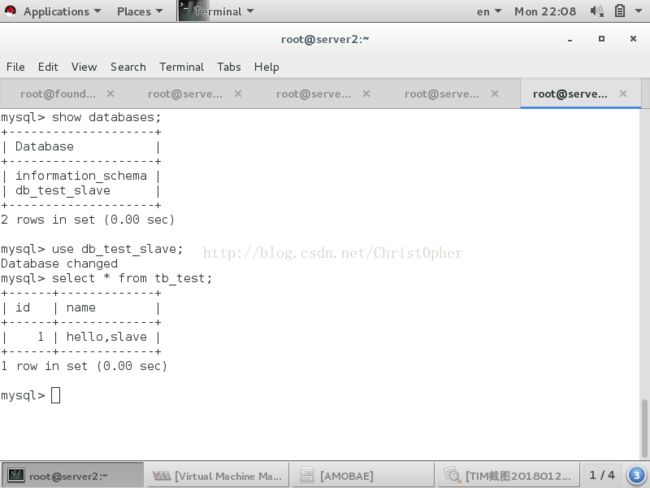
stop掉读池中的db(slave) select操作报错
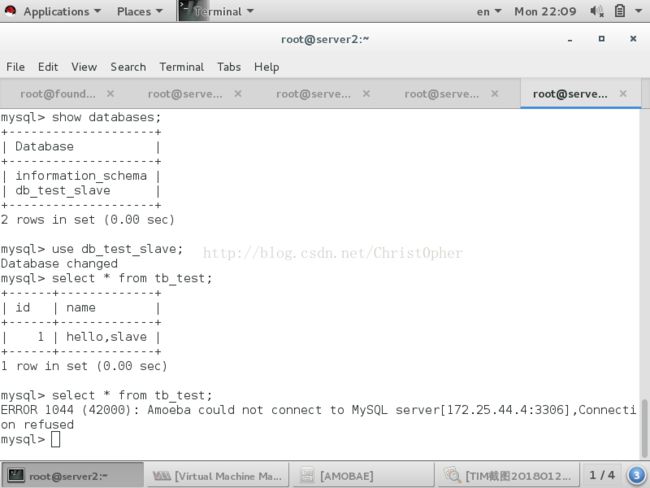
stop掉写池中的db(master) insert 操作报错
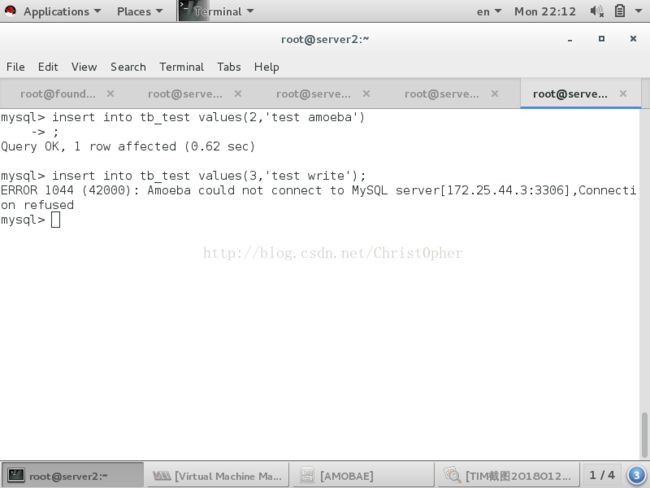
看到这样的结果 表示完成了读写分离