Flink Basic API Concepts 学习笔记&译文
地址:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/api_concepts.html#
Flink也是常规的分布式程序,在分布式数据集上实现了transformation算子,例如: filtering, mapping, updating state, joining, grouping, defining windows, aggregating。数据集初始化一般是读取文件、Kafka、或者内存数据等,结果一般可以写到文件或者终端打印。Flink支持Standalone或者运行在其他框架之上,不同的运行模式下Flink运行在不同的Context中,Flink程序可以执行在本地或者是集群中!
根据数据源的类型,Flink可以开发批处理程序或者Streaming程序,批处理程序使用DataSet API,Streaming程序使用DataStream API 。API具体信息查看: Streaming Guide 和 Batch Guide !
Note:正如前面的example,Streaming程序使用的是StreamingExecutionEnvironment 和DataStream API,批处理使用的是ExecutionEnvironment 和DataSet API。
Flink使用DataSet和DataStream在程序中代表数据,你可以认为他们是可以包含重复数据的不可变的数据集合。DataSet是有限的数据,DataStream是无边界的数据!
数据集和Java collection区别:首先,数据集一旦创建了就无法再add或者remove元素了,同时也无法访问里面的元素(应该指的是不可以想Java集合一样get某一个元素)!
Flink程序一旦创建了数据集,可以根据现有的数据集使用算子生成新的数据集!
execution environment)
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(host: String, port: Int, jarFiles: String*)getExecutionEnvironment方法或根据你的执行环境自动创建一个ExecutionEnvironment,如果你是在IDE中运行你的程序,getExecutionEnvironment方法方法会返回一个 Local environment,如果你对程序打成Jar包之后使用命令行提交到集群运行的话,getExecutionEnvironment方法将会返回一个Cluster environment。
第二步,加载数据集:
可以加载Text或者指定Format加载指定格式数据。
al env = StreamExecutionEnvironment.getExecutionEnvironment()
val text: DataStream[String] = env.readTextFile("file:///path/to/file")val input: DataSet[String] = ...
val mapped = input.map { x => x.toInt }第四步,输出:
writeAsText(path: String)
print()第五步,触发作业执行: 调用 execute()触发作业执行
所有的Flink程序都是延迟执行的,当程序的main方法被执行时候,所有加载数据和transformations 算子都没有开始执行,而是每一个operation 将会创建并且添加到程序Plan中(类似于Spark的Stage)。只有当你明确的调用execute()方法时候,程序才会真正执行!
延迟加载好处:你可以开发复杂的程序,但是Flink可以可以将复杂的程序转成一个Plan,将Plan作为一个整体单元执行!
有些transformations (join, coGroup, keyBy, groupBy) 需要数据集有key,其他的一些transformations (Reduce, GroupReduce, Aggregate, Windows) 可以根据key进行分组:
A DataSet is grouped as
DataSet<...> input = // [...]
DataSet<...> reduced = input
.groupBy(/*define key here*/)
.reduceGroup(/*do something*/);
while a key can be specified on a DataStream using
DataStream<...> input = // [...]
DataStream<...> windowed = input
.keyBy(/*define key here*/)
.window(/*window specification*/);Flink的数据模型不是基于Key/Value的,因此你不必特意将数据集组成Key/Value形式,Flink中的Key是根据实际数据由函数定义的!
如下讨论我们将基于DataStream API 和keyBy,对于DataSet API使用的是DataSet 和 groupBy.
为元组定义Key:
1:单个属性为Key
val input: DataStream[(Int, String, Long)] = // [...]
val keyed = input.keyBy(0)//元组第一个属性被定义为Key这样的话,元组的分组可以根据第一个属性进行分组!
2:多个属性定义组合Key
val input: DataSet[(Int, String, Long)] = // [...]
val grouped = input.groupBy(0,1)这样的话,元组的分组可以根据第一个、第二个属性进行分组!(比Spark算子强大)
使用字段表达式定义Key:
可以使用String类型的字段为 grouping, sorting, joining, or coGrouping算子定义Key ,例如:
我们有一个wc的POJO,它有两个字段:word、count。为了根据word字段进行分许,我们可以传递名字给keyBy定义Key:
// some ordinary POJO (Plain old Java Object)
class WC(var word: String, var count: Int) {
def this() { this("", 0L) }
}
val words: DataStream[WC] = // [...]
val wordCounts = words.keyBy("word").window(/*window specification*/)
// or, as a case class, which is less typing
case class WC(word: String, count: Int)
val words: DataStream[WC] = // [...]
val wordCounts = words.keyBy("word").window(/*window specification*/)
Field Expression Syntax:
-
Select POJO fields by their field name. For example
"user"refers to the “user” field of a POJO type. -
Select Tuple fields by their 1-offset field name or 0-offset field index. For example
"_1"and"5"refer to the first and sixth field of a Scala Tuple type, respectively. -
You can select nested fields in POJOs and Tuples. For example
"user.zip"refers to the “zip” field of a POJO which is stored in the “user” field of a POJO type. Arbitrary nesting and mixing of POJOs and Tuples is supported such as"_2.user.zip"or"user._4.1.zip". -
You can select the full type using the
"_"wildcard expressions. This does also work for types which are not Tuple or POJO types.
Field Expression Example:
class WC(var complex: ComplexNestedClass, var count: Int) {
def this() { this(null, 0) }
}
class ComplexNestedClass(
var someNumber: Int,
someFloat: Float,
word: (Long, Long, String),
hadoopCitizen: IntWritable) {
def this() { this(0, 0, (0, 0, ""), new IntWritable(0)) }
}These are valid field expressions for the example code above:
-
"count": The count field in theWCclass. -
"complex": Recursively selects all fields of the field complex of POJO typeComplexNestedClass. -
"complex.word._3": Selects the last field of the nestedTuple3. -
"complex.hadoopCitizen": Selects the HadoopIntWritabletype.
Define keys using Key Selector Functions(使用Key Selector函数)
// some ordinary case class
case class WC(word: String, count: Int)
val words: DataStream[WC] = // [...]
val keyed = words.keyBy( _.word )Specifying Transformation Functions(为Transformation指定函数)
Lambda Functions
val data: DataSet[String] = // [...]
data.filter { _.startsWith("http://") }val data: DataSet[Int] = // [...]
data.reduce { (i1,i2) => i1 + i2 }
// or
data.reduce { _ + _ }Rich functions
data.map { x => x.toInt }you can write
class MyMapFunction extends RichMapFunction[String, Int] {
def map(in: String):Int = { in.toInt }
}) and pass the function to a map transformation:
data.map(new MyMapFunction())Rich functions can also be defined as an anonymous class:
data.map (new RichMapFunction[String, Int] {
def map(in: String):Int = { in.toInt }
})Supported Data Types
参官方文档Accumulators & Counters(加速器&计数器)
Accumulators are simple constructs with an add operation and a final accumulated result, which is available after the job ended.
The most straightforward accumulator is a counter: You can increment it using the Accumulator.add(V value) method. At the end of the job Flink will sum up (merge) all partial results and send the result to the client. Accumulators are useful during debugging or if you quickly want to find out more about your data.
这个和Spark中的加速器类似,Accumulator是父接口,Counter是其一个简单实现!
Flink目前内置的加速器有如下这些,这些加速器都实现了ccumulator接口。
- IntCounter, LongCounter and DoubleCounter: See below for an example using a counter.
- Histogram: A histogram(直方图) implementation for a discrete(离散值) number of bins. Internally it is just a map from Integer to Integer. You can use this to compute distributions of values, e.g. the distribution of words-per-line for a word count program.(可以用来分布式统计每一行单词数)
private IntCounter numLines = new IntCounter();getRuntimeContext().addAccumulator("num-lines", this.numLines);this.numLines.add(1);JobExecutionResult
对象获取结果:
myJobExecutionResult
= env.execute()
myJobExecutionResult.getAccumulatorResult("num-lines")最后附上一张Flink的结构图:
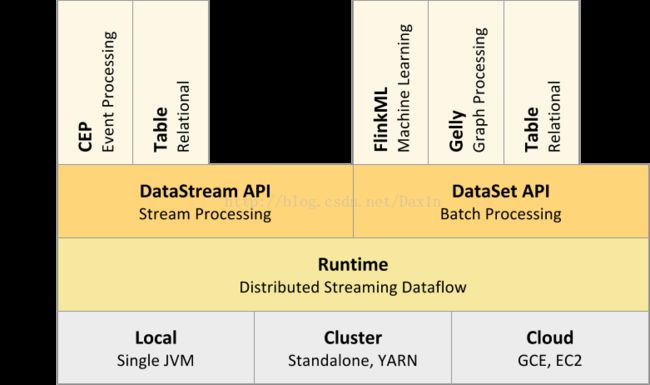
Flink程序执行流程:
