各位大佬,别再拿人工智能当春药了!
我是个二手的人工智能表演艺术家:从博士毕业开始,就在 MSRA 做了几年语音识别项目的研究。 虽然我们的两任院长——李开复老师和洪小文老师都是语音研究出身,却丝毫不能改变当年这一项目在全院最鸡肋的地位。
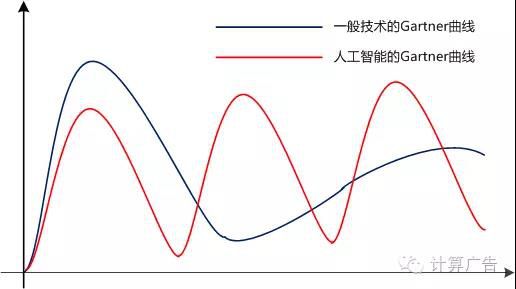
为什么鸡肋呢?因为在当年,各种各样的人工智能应用能真刀真枪上阵的并不多。就拿语音识别来说,从几十年前 IBM 和 AT&T 提出人类用语音与机器交互这一伟大的设想以来,就有无数的业内业外人士为之激动、为之奋斗,也为之失望。我们都知道新技术的发展有条 Gartner 曲线,先被炒得大热,再跌下来,又慢慢爬坡到稳定的状态。
语音识别或人工智能则不然:它被爆炒了好几次,也深深地摔下来好几次。这一方面反映了人工智能问题的巨大吸引力,也体现了它巨大的难度。在我从事语音的那几年,恰逢一个谷底时期,那是有无数的“有识之士”纷纷站出来表达对互联网糙快猛的膜拜,并夹枪带棒地表达对人工智能的鄙夷,认为我们不过是马勺上的苍蝇——混饭吃的。我们要是向互联网界提起自己是做“语音识别”的,也仿佛是在两会会场上偷看了禁片那样无地自容。
然而不得不说,在真正从事人工智能的那几年里,我接触到了到目前为止看来最严谨、最具学者风范的几位良师和益友。比如我的第一任老板,来自 Bell Labs 的资深科学家宋謌平老师;第二任老板,原港大教授霍强老师;以及多年的好友,现科大讯飞执行总裁胡郁等。这些人工智能专家身上都有一种共同的特质:思维深邃又有独立见解,长期甘守寂寞,在人工智能的低潮期从未放弃探索与研究。
那么事情是什么时候发生转折的呢?
2010年前后,我以前微软的同事俞栋老师、邓力老师等,将深度学习在图像领域的突破移植到语音识别领域,一下子把识别错误率降低了 20%以上,这让原来感觉总是差点儿火候的语音识别突然看到了在某些场景下实用的希望。从图像、语音等领域的突破开始,人工智能的一个新春天又悄然来临,同时也搞火了“深度学习”这个词。
“深度学习”这个词儿,实在是太美妙了。深,就意味着莫测,意味着正常人的智商大概难以企及。正常人不明白的事儿从我嘴里说出来,那我不牛逼谁牛逼?就是因为这样一个逼格甚高的词儿(有点儿像广告领域的“程序化交易”),再加上若干人工智能应用确实有了一定的突破,在今天,人工智能已经替代大数据、O2O,成为互联网各位卖野药的、开秀场的、搞劫持的、做流氓软件的诸企业家们最好的兴奋剂。
在人工智能的加持下,大佬们纷纷把自己满肚子的互联网思维呕吐出来,摆出一副智能仁波切的嘴脸,像念“嗡嘛呢叭咪吽”那样把“人工智能、深度学习、机器人、无人驾驶”等词汇摆在嘴边,并且具备了时刻达到高潮的能力。我曾经有幸听过几位大佬有关人工智能的论述和演讲,据说他们都已经成为人工智能先驱者一个多礼拜了。就内容而言,有一种相声演员做政府工作报告的莫名喜感,只不过没有那么密集的包袱罢了。
在智商不够的人看来,一切都是智能的。于是乎,一些充满了邪教气息的论断,在互联网界开始甚嚣尘上,例如:
“机器学习模型依靠左右互搏,可以迅速达到很高的智能水准。”(说他们智商低,是因为这一点他们真信了。)
“人工智能毁灭人类的奇点即将来到!”(我认为机器早就能毁灭人类了,不过这跟人工智能并没有关系。)
“只有人工智能才能拯救人类!”(潜台词是:只有我这样人工智能的使者才能拯救你们!)
“我们的产品融合了大数据和人工智能技术。”(其实多数情况下不过是用 hadoop 跑了个脚本。)
作为一个知识分子,我是不太擅长骂人的。咱们还是先讲讲道理,看看深度学习到底解决了什么,还有哪些挑战。
实际上,到今天为止,无论什么样的机器学习,本质上都是在统计数据,从中归纳出模型。很早以前大家就认识到,深层的神经网络比起浅层的模型,在参数数量相同的情形下,深层模型具有更强的表达能力。这个概念说起来也好理解:用同样的面积的铁皮,做个桶比做个盘子盛的水要多一些。对此,马三立大师早有论述:碗比盘深,盆比碗深,缸比盆深,最浅的是碟子,最深的是缸。而盘子或桶里的水,则类比于模型可以接纳并总结的数据:太浅层的模型,其实很容易自满,即使有大量的数据灌进去,也并没有什么卵用。

既然很早就知道深层模型的表达能力更强,那么为什么近年来深度学习才大放异彩呢?那是因为桶虽然盛水多,我们以前却没有掌握将它高效率地灌满的办法。也就是说,以前对深度神经网络,没有太有效的工程优化方法。一个大桶摆在那儿,却只能用耳挖勺一勺勺的往里灌水,多久才能灌满啊?直到本世纪,Geoffrey Hilton 和他的学生发明了用 GPU 来优化深度神经网络的工程方法,这就好比灌水时发明了水管,极大地提高了效率。这样的工程方法产生后,深度神经网络才变成工业界实用的武器,并且在若干领域都带来了里程碑式的变化。

桶有了,水管也有了,还缺什么呢?当然就是水了。对深度学习模型而言,水就是海量的数据。比方说原来用浅层的模型做人脸识别,训练样本到了一定的规模,再多就没有用了,因为盘子已经灌满了,再灌就盛不下了。可是,改用深度学习,再加上有了水管以后,数据一直往里面灌,模型还是可以继续学习和提高。就拿机器识别物体这样的任务来说,通过数百万幅图片的训练,深度学习模型甚至可以超过肉眼的识别能力,这确实是人工智能在感知类问题上重要的里程碑。

然而,上面的例子提醒我们:人工智能和人的智能,还真的不是一回事。几岁的小孩子,大人给他指过一次猫,下次他十有八九就能认出来。然而不论是多强的人工智能模型,也不可能看几张猫的图片,就能准确地认识猫。也就是说,深度神经网络的“智能”,是建立在海量数据基础之上的,因此,深度学习与大数据,有着非常紧密的内在联系。
关于深度学习,还有一个有趣的现象。就目前情况来看,深度学习技术在互联网应用(例如广告、推荐等)上取得的提高,没有语音图像这些领域那样显著。这里面有什么规律性的解释么?个人认为,自然现象的数据处理,例如语音识别,我们完全可以通过主动的语料采集,让各个 phoneme 甚至 biphone、triphone 都挺有充分的覆盖;而互联网收集的社会行为,例如广告点击、新闻阅读这些数据,Ground truth 并不清晰:即使对于同一个人、同一则广告、同一个广告位,点击与否也是个很不确定的事件,而这样的不确定性即使引入再多的上下文信息,也不可能消除。而引入了大量的上下文信息(即模型需要的feature)后,在每个片段上的数据实际上非常稀少,并不能满足深度学习模型彻底进化的需要。怎么解决这个问题呢?最近爆火的 AlphaGo 采用的 Deep Reinforcement Learning 方法论,或许是个启发。
以上种种人工智能技术经历的磨难与辉煌,乃至更加波澜壮阔的未来,都需要参与者们抱定一颗平常心,以十年磨一剑的决心和毅力去攻克一个个产品与技术难关。因为人工智能不同于卖盒饭或者搞劫持,凡小学肄业以上文化程度,对手段之道德底线无特殊要求者皆可以胜任,它需要对于科学技术真正的信仰与坚持,对于背景理论多年的修养与磨练,远非看上去那样简单美好。
资本与大佬们对于人工智能的追捧,当然不能说是坏事。不过说实话,在里面确实也能多少嗅出一些单纯追逐风口、顺风接屁的恶趣味。这个领域已经被捧杀了好几回,好不容易有些转机,还是给大家正确的普及、合理的预期比较重要。就拿语音识别来说,Benchmark 集合上词正确率的提升,其实并不意味着人机直接用语言进行交流已经可以畅通无阻:各种复杂噪音环境下的鲁棒性问题、自然语言理解的巨大挑战、找到适合语音交流的杀手级应用场景,这些都是当我们推门以为豁然开朗时,又发现横亘在面前的王屋与太行。理性的人工智能从业者,不要轻信各种没有根据的摇旗呐喊——因为你并非正要向终点冲刺,而是刚刚踏上跑道。
那些把人工智能捧成耶和华般的行业分析师与大佬,是十分值得警惕的。我敢断言,当此领域再遇波折,将“人工智能”这四个字踩在脚下、恶狠狠淬上一口的,还会是这一拨人。而其中有些个别人恶俗的热捧,则可以说是人工智能的耻辱——西施长得好不好,是不需要八大胡同的选美比赛来品头论足的。
@北冥乘海生 2018.9
——————
推荐阅读:
《The Coder》9 月刊聚焦程序员的职场江湖