maven实现storm实例项目
一:启动zookeeper
在写程序之前需要启动集群中的zookeeper,我这是三台机器,master, DataNode1, DataNode2。每台机器都要启动,启动方式如下图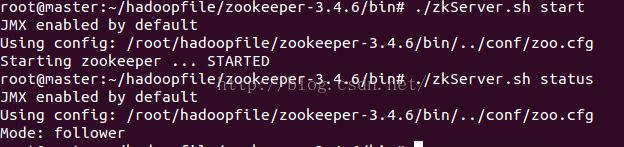
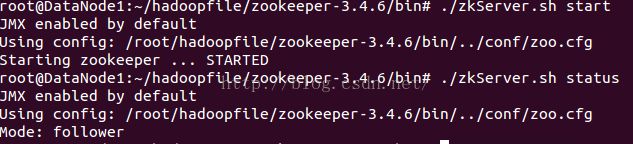
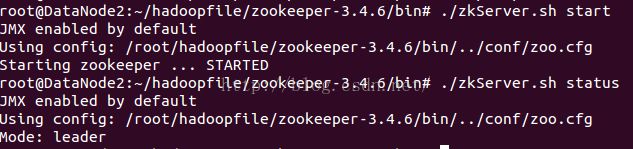
启动后会有一个leader节点和两个follower节点。可以通过zkServer.sh status这个命令查看
二:启动storm 中的nimbus 和 supervisor 和UI
在storm中需要确定一个nimbus节点,然后再启动每个节点上的superivsor,然后在nimbus节点上启动UI
(注:在使用storm命令时应该已经在环境变量中对storm作了配置,并且source了这个文件)
启动命令 storm nimbus & 和 storm supervisor & 和 storm ui &其中“&”表示运行与后台
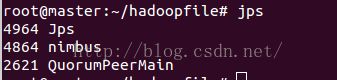
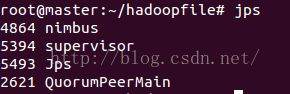
注意,需要启动每个节点上的supervisor。
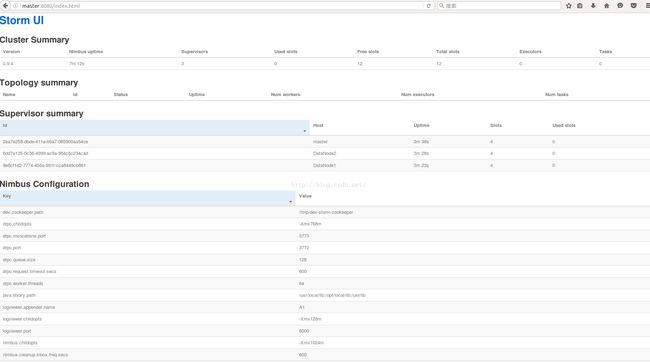
最后启动ui,启动完成后可以通过浏览器访问,地址 : nimbus节点主机名:8080
三: 写程序
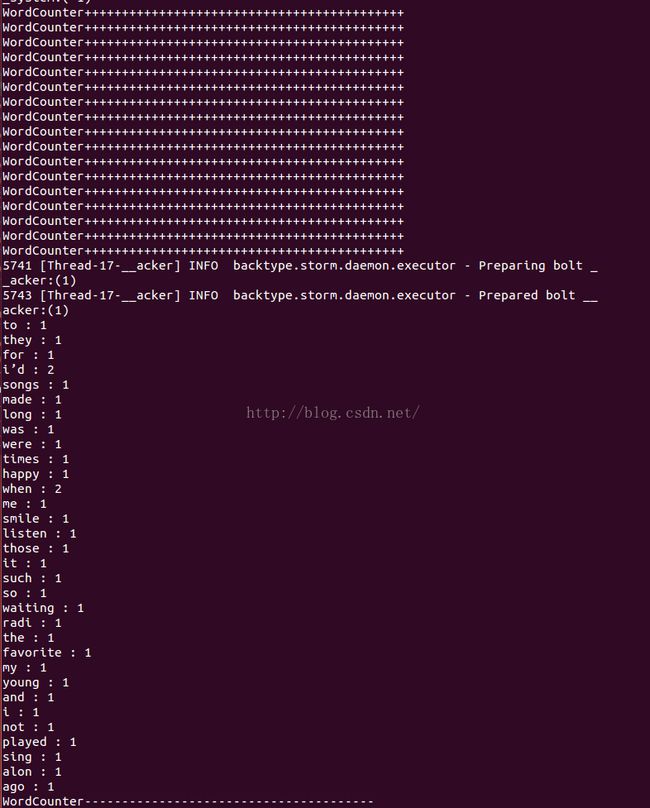
这是一个wordCount的程序,主要是记录输入文本中的单词的个数,并把结果显示在命令行中。
首先确定你电脑上安装了maven,也可以通过eclipse去创建maven工程。(本例是通过eclipse去创建的)
在创建完maven项目后,会在项目中出现一个pom.xml文件,主要是在这个文件中加入一个storm的依赖包
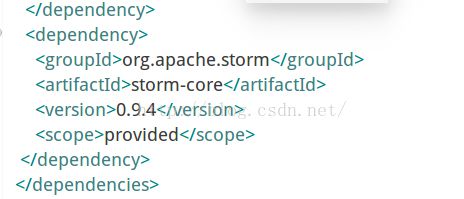
然后就是主要程序,其中包括
一个spout:WordReader.java
两个bolt:WordSpliter.java 和 WordCounter.java
一个topology:WordCountTopology.java
spout中主要是获取数据源。bolt主要是获取spout发过来的tuple,并对句中的每一行按空格分隔成单词,然后对单词进行统计。
topology主要是确定运行逻辑,确定spout 和 bolt 还有分组策略,这里采用的是shuffleGrouping策略。
WordReader.java
package spouts;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.filefilter.FileFilterUtils;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class WordReader extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private String inputPath;
private SpoutOutputCollector collector;
@Override
public void nextTuple() {
//get files
Collection
FileFilterUtils.notFileFilter(FileFilterUtils.suffixFileFilter(".bak")), null);
for(File f:files){
try{
List
for(String line : lines){
//it is unreliable
collector.emit(new Values(line));
}
FileUtils.moveFile(f, new File(f.getPath() + System.currentTimeMillis() + ".bak"));
}catch(IOException e){
e.printStackTrace();
}
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
inputPath = (String)conf.get("INPUT_PATH");
}
//declarer the field
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
WordSpliter.java
package bolts;
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordSpliter extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getString(0);
String[] words = line.split(" ");
for(String word : words){
word = word.trim();
if(StringUtils.isNotBlank(word)){
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCounter.java
package bolts;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class WordCounter extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
private HashMap
private volatile boolean edit = false;
@Override
public void prepare(Map stormConf, TopologyContext context) {
final long timeOffset = Long.parseLong(stormConf.get("TIME_OFFSET").toString());
new Thread(new Runnable(){
@Override
public void run() {
while(true){
if(edit){
for(Entry
System.out.println(entry.getKey() + " : " + entry.getValue());
}
System.out.println("WordCounter---------------------------------------");
edit = false;
}
try {
Thread.sleep(timeOffset * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String str = input.getString(0);
if (!counters.containsKey(str)) {
counters.put(str, 1);
} else {
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
edit = true;
System.out.println("WordCounter+++++++++++++++++++++++++++++++++++++++++++");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}
WordCountTopology.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import bolts.WordCounter;
import bolts.WordSpliter;
import spouts.WordReader;
public class WordCountTopology {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("Usage: inputPaht timeOffset");
System.err.println("such as : java -jar WordCount.jar D://input/ 2");
System.exit(2);
}
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader", new WordReader());
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter()).shuffleGrouping("word-spilter");
String inputPaht = args[0];
String timeOffset = args[1];
Config conf = new Config();
conf.put("INPUT_PATH", inputPaht);
conf.put("TIME_OFFSET", timeOffset);
conf.setDebug(false);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
}
}
运行Storm程序
![]()
运行结果