2017-ICCV-Mask R-CNN
本周组会讲Mask R-CNN,借此机会把目标检测R-CNN系列的论文都整理了一遍,除了paper外,主要参考网上的一些博客,如有侵权,请告知,在此十分感谢。
文中如有错误,请积极指出,一起学习,共同进步。
相关论文链接:
R-CNN → SPP Net → Fast R-CNN → Faster R-CNN → Mask R-CNN
YOLO、SSD
FCN、FPN、MNC、FCIS
关于YOLO可参考本人另一篇博客2016-CVPR-YOLO
github代码:
pytorch-faster-rcnn
tensorflow-mask-rcnn
Introduction
Ross Girshick大神:
从DPM,R-CNN,fast R-CNN,faster R-CNN,到mask R-CNN,垄断object detection近10年。
Kaiming He大神:
ResNet系列基本搞定了Image classification。
现在两人联手,开始攻克Instance Segmentation。
Mask R-CNN在不加任何 trick 的情况下超过各种数据增强加持下的 COCO 2016 分割挑战的冠军 FCIS。
Mask R-CNN ICCV 2017 best paper
Scene understanding
Image classification:图像分类,识别出图中的物体类别
Object detection:目标检测,既要识别出图中的物体,又要知道物体的位置,即图像分类+定位
Semantic segmentation:语义分割,除了识别物体类别与位置外,还要标注每个目标的边界,但不区分同类物体,将物体进行像素级别的分割提取
Instance segmentation:实例分割,除了识别物体类别与位置外,还要标注每个目标的边界,且区分同类物体,将物体进行像素级别的分割提取
Mask R-CNN: Motivation and goals
Mask R-CNN的三个目标:
- 视觉场景理解的多任务模型的状态: 同时满足目标检测、分类及实例分割的要求
- 高度模块化,训练简单,相对于Faster R-CNN仅增加一个小的overhead,可以跑到5FPS
- 可以方便的扩展到其他任务,比如人体姿态估计等
R-CNN
步骤:
- 训练(或下载)一个分类模型(比如AlexNet)
- 对模型进行fine-tuning:
- 将分类数1000改为21(有一个类别是背景)
- 去掉最后一个全连接层
- 特征提取:
- 利用selective search算法在图像中从上到下提取约2k个候选区域
- 将每个候选区域wrap成 224∗224 的大小以适合CNN的输入,做一次前向传播,将CNN的fc7层的输出作为特征,保存到硬盘
- 训练一个SVM分类器来判断这个候选框里物体的类别,每个类别对应一个SVM,判断是否属于这个类别,是就是positive,反之就是nagative
- 使用SVM分好类的候选区域做边框回归,用bounding box 回归值校正
该方法在VOC 2011 test数据集上取得了71.8%的检测精度。
Selective search:
这个策略借助了层次聚类的思想,应用到区域的合并上面。
- 假设现在图像上有n个预分割的区域(Efficient Gragh-Based Image Segment),表示为 R=R1,R2,…,Rn
- 计算每个region与它相邻region的相似度,这样会得到一个 n∗n 的相似度矩阵(同一个区域之间和不相邻区域之间的相似度可设为NaN),从矩阵中找出最大相似度值对应的两个区域,将这两个区域合二为一,这时图像上还剩下n-1个区域
- 重复上述过程(只需计算新的区域与它相邻区域的新相似度,其他的不用重复计算),重复一次,区域的总数目就少1,直到最后所有的区域都合并成为了同一个区域

缺点:
- 训练和测试过程分为多个阶段,步骤繁琐:微调网络,得到候选区域,CNN提取特征,SVM分类,SVM边界框回归
- 训练耗时,占用磁盘空间大,5000张图像产生几百G的特征文件
- 测试过程中,每一个候选区域都要提取一遍特征,这些区域有一定重叠度,各个区域的特征提取独立计算,效率不高,使测试一幅图像非常慢
- SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新
因此,把R-CNN的缺点改掉,就成了Fast R-CNN。
Fast R-CNN
Fast R-CNN在R-CNN的基础上采纳了SPP Net方法,对R-CNN作了改进。使用VGG-19网络架构比R-CNN在训练和测试时分别快了9倍和213倍。
步骤:
- 输入测试图像
- 利用selective search算法在图像上从上到下提取约2k个候选区域
- 将整张图片输入CNN,进行特征提取,得到feature map
- 把候选区域映射到CNN的最后一层卷积feature map上
- 通过RoI pooling层使每个候选区域生成固定尺寸的feature map
- 利用Softmax loss(探测分类概率)和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练
相比R-CNN,两处改进:
- CNN最后一层卷积层后加了一个RoI pooling层,可以看做单层SPP Net的网络层,可以把不同大小的输入映射到一个固定尺寸的特征向量。
- 在R-CNN中是先用SVM分类器,再做bbox regression,而在Fast R-CNN中,损失函数使用了multi-task loss,将bbox regression直接加入到CNN网络中训练,并且实验证明这两个任务能够共享卷积特征,相互促进。
Faster R-CNN
步骤:
- 输入测试图像
- 将整张图片输入CNN,进行特征提取
- 用RPN生成候选区域,每张图片生成300个候选区域
- 把候选区域映射到CNN的最后一层卷积feature map上
- 通过RoI pooling层使每个RoI生成固定尺寸的feature map
- 利用Softmax loss(探测分类概率)和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练
相比Fast R-CNN,两处改进:
- 使用RPN(Region Proposal Network)代替原来的Selective Search方法产生候选区域,使得检测速度大幅提高
- 产生候选区域的CNN和目标检测的CNN共享,候选区域的质量也有本质的提高
Mask R-CNN
Mask R-CNN实际上就是Faster R-CNN + Mask branch,RoIAlign的结果。
相比Faster R-CNN,两处改进:
- 把Faster R-CNN里的RoIPool layer改为RoIAlign layer
- 最后多了一个mask branch
RPN
RPN是一个全卷积网络,由于没有全连接层,所以可以输入任意分辨率的图像,经过网络后就得到一个feature map,然后利用这个feature map得到物体的位置和类别。
那么,怎么利用这个feature map得到物体的位置和类别呢?
在conv5-3的卷积feature map上用一个 n∗n(n=3) 的滑动窗口(sliding window)生成一个256维(ZFNet)或512维(VGGNet)长度的全连接特征,然后在这个特征后产生两个分支的全连接层:
- Reg-layer,用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h
- cls-layer,用于判定该proposal是前景还是背景
Anchor:
- 把得到的feature map上的每一个点映射回原图,得到原图上这些点的坐标
- 在这些点周围取一些提前设定好的区域用来训练RPN,这些区域就叫做Anchor boxes
anchor(锚点),位于 n∗n 的滑动窗口的中心处,对于一个滑动窗口,可以同时预测k个候选区域,即k个anchor boxes,每个anchor box可以用一个scale,一个aspect_ratio和滑动窗口中的anchor唯一确定。论文中定义k=9,即3种scales(比如 1282,2562,5122 )和3种aspect_ratio(比如 1:1,1:2,2:1 )确定出当前滑动窗口处对应的9个anchor boxes, 2∗k 个cls-layer的输出和 4∗k 个reg-layer的输出。对于一幅 W∗H 的feature map,对应 W∗H∗k 个anchor boxes。所有的anchors都具有尺度不变性。
IoU:
在计算Loss值之前,作者设置了anchors的标定规则:
- 如果anchor对应的anchor box与ground truth的IoU最大,标记为正样本
- 如果anchor对应的anchor box与ground truth的IoU>0.7,标记为正样本
- 如果anchor对应的anchor box与ground truth的IoU<0.3,标记为负样本
- 剩下的既不是正样本也不是负样本,不用于最终训练
- 训练RPN的Loss是由classification loss(即softmax loss)和regression loss(即L1 loss)按一定比重组成的
Loss functions:
计算softmax loss需要的是anchors对应的groudtruth标定结果和预测结果,计算regression loss需要三组信息:
- 预测框proposal region:即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h
- Anchor box:1个anchor对应9个不同的scale和aspect_ratio的anchor boxes,每一个box都有一个中心点位置坐标 xa,ya 和宽高 wa,ha
- Ground truth:标定的框也对应一个中心点位置坐标 x∗,y∗ 和宽高 w∗,h∗
因此,计算regression loss和总loss算法如下:
RPN训练设置:
- 在训练RPN时,一个mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1
- 如果正样本不足128,则多用一些负样本以满足256个proposal可以用于训练,反之亦然
- 训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化
缺点:
RPN关键在于选取了一些anchor进行pixel-wise的学习,但问题就是对小物体的检测效果很差,假设输入为 512∗512 ,经过网络后得到的feature map是 32∗32 ,那么每一个feature map上的一个点都要负责周围至少是 16∗16 的一个区域的特征表达,那对于在原图上很小的物体它的特征就难以得到充分的表示,因此检测效果比较差。
RoIPool(Fast R-CNN)
在Fast R-CNN和Faster R-CNN中用到的RoI pooling层,其实是借鉴了SPP Net中的思想,所以在介绍RoIPool前,先了解一下SPP Net。
SPP Net:(Spatial Pyramid Pooling,空间金字塔池化)
结合空间金字塔方法实现CNNs的多尺度输入:
R-CNN提取候选框后需要进行crop和wrap来修正尺寸,这样会造成数据的丢失或几何的失真。SPP Net将金字塔思想加入到CNN,在卷积层和全连接层之间加入SPP layer,SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
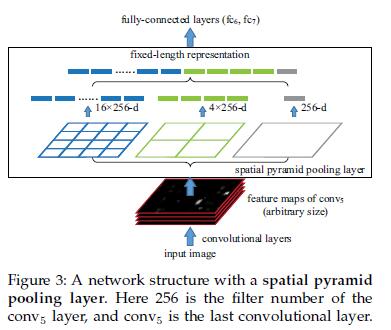
如果原图输入是 224∗224 ,对于conv5出来后的输出,是 13∗13∗256 ,即256个filter,每个filter对应一张 13∗13 的activation map。如果像上图那样将activate map pooling成 4∗4,2∗2,1∗1 三张子图,做max pooling后,出来的特征就是固定长度的 (16+4+1)∗256 那么多维度了。如果原图的输入不是 224∗224 ,出来的特征依然是 (16+4+1)∗256 ;可以理解成将原来固定大小为 3∗3 窗口的pool5改成了自适应窗口大小,窗口的大小和activation map成比例,保证了经过pooling后出来的feature的长度是一致的。
只对原图提取一次卷积特征:
在R-CNN中,每个候选框resize后都要独立经过CNN,这样很低效。SPP Net只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层,这样节省了大量时间,比R-CNN快了100倍左右。
RoI Pool:
Fast R-CNN中使用RoIPool将不同大小的候选区域的特征转化为固定大小的特征图像,其做法是:假设候选区域RoI大小为 h∗w ,要输出的大小为 H∗W ,那么就将RoI分成 (h/H)∗(w/W) ,然后对每一个格子使用max-pooling得到目标大小的特征图像。
RoI pooling layer实际上是SPP Net的一个精简版,SPP Net对每个proposal使用了不同大小的金字塔映射,而RoI pooling layer只需要下采样到一个 7∗7 的特征图。对于VGG-16的网络conv5_3有512个特征图,这样所有region proposal对应了一个 7∗7∗512 维度的特征向量作为全连接层的输入
RoI Pooling就是实现从原图区域映射到conv5区域最后pooling到固定大小的功能。
RoIAlign(Mask R-CNN)
对于每个RoI使用一个FCN来预测 m∗m mask。 m∗m 是一个小的特征图尺寸,如何将这个小的特征图很好的映射到原始图像上?Faster R-CNN不是为网络输入和输出之间的像素到像素对齐而设计的,应用到目标上的核心操作的是粗略的空间量化特征提取,RoIPool不适用于图像分割任务,为了修正错位,Mask R-CNN提出了一个简单的,量化无关的层,称为RoIAlign,可以保留精确的空间位置。
RoIAlign:
RoIPool是从每个RoI提取小特征图(例如, 7∗7 )的标准操作,RoIPool首先将浮点数值的RoI量化成离散颗粒的特征图,然后将量化的RoI分成几个空间的小块(spatial bins),最后汇总每个块覆盖的区域的特征值(通常使用最大池化)。例如,对在连续坐标系上的 x 计算 [x/16] ,其中 16 是feature map的stride, [.] 表示四舍五入。同样地,当对RoI分块时(例如 7∗7 )时也执行同样的计算。这样的计算让RoI与提取的特征错位。虽然这可能不会影响分类,因为分类对小幅度的变换具有一定的鲁棒性,但它对预测像素级精确的掩码有很大的负面影响。
为了解决RoIPool量化引入的问题,提出RoIAlign层,将提取的特征和输入准确对齐。改进:避免对RoI的边界或bins进行量化(避免四舍五入,取 x/16 )。使用双线性插值精确计算每个位置的精确值,并将结果汇总(使用最大池化或平均池化)。
双线性插值:

如图,已知Q12,Q22,Q11,Q21,但是要插值的点为P点,这就要用双线性插值了,首先在x轴方向上,对R1和R2两个点进行插值,这个很简单,然后根据R1和R2对P点进行插值,这就是所谓的双线性插值。
Class prediction & box regression
Segmentation
解耦掩码和分类至关重要:
定义 Lmask 方式使得网络生成每个类别的mask不会受到类别竞争影响,解耦了mask和类别预测。这与通常FCN应用于像素级Softmax和多重交叉熵损失的语义分段的做法不同。在这种情况下,掩码将在不同类别之间竞争。而在mask R-CNN中,使用了其他方法没有的像素级的Sigmoid和二进制损失。
- 全卷积:因为要保存空间信息,所以没有用全连接层把feature map变成向量,而是用全卷积输出m*m的mask。
- 掩码分支对于每个RoI的输出维度是 K∗(m∗m) ,表示k个分辨率为 m∗m 的二值掩码,每个类别1个,k是类别数目。为每个类独立地预测二进制掩码,这样不会跨类别竞争,并且依赖于网络的RoI分类分支来预测类别
- 为每个像素应用 sigmiod,将 Lmask 定义为平均二进制交叉熵损失。对于真实类别为k的RoI,仅在第k个掩码上计算 Lmask (其他掩码输出不计入损失)
Experiments
Dataset & metrics
Related methods: MNC
MNC:
Multi Network Cascade 多任务网络级联,COCO 2015分割挑战的冠军
一个复杂的多级级联模型,从候选框中预测候选分割,然后进行分类。
Related methods: FCIS
FCIS:
fully convolutional instance segmentation 全卷积实例分割,COCO 2016分割挑战的冠军
用全卷积得到一组位置敏感的输出通道候选。这些通道同时处理目标分类,目标检测和掩码,这使系统速度变得更快。但FCIS在重叠实例上出现系统错误,并产生虚假边缘。
以下实验部分请参考论文。
Segmentation results
Detection results
Ablation experiments
Human pose estimation
Wrap up
Mask R-CNN head architectures
网络架构:
为了证明这个方法的普适性,论文中构造了多种不同的Mask R-CNN。
- 用于整个图像上的特征提取的下层卷积网络(ResNet,FPN)
- 用于检测框识别(分类和回归)和掩码预测的上层网络
对于上层网络,扩展了ResNet和FPN中提出的Faster R-CNN上层网络,分别添加了一个掩码分支。图中数字表示分辨率和通道数,箭头表示卷积、反卷积或全连接层,其中卷积减小维度,反卷积增加维度,所有卷积都是 3∗3 ,除了输出层是 1∗1 的,反卷积是 2∗2 ,stride为2,隐藏层使用ReLU。res5表示ResNet的第五阶段,图中修改了第一个卷积操作,使用 7∗7 ,步长为1的RoI代替 14∗14 ,步长为2的RoI。下图中的” ×4 ”表示堆叠的4个连续的卷积。
ResNet-C4的上层网络包括ResNet的第五阶段(即9层的“res5”),对于FPN,下层网络已经包含了res5,因此可以使上层网络包含更少的卷积核而变的更高效。
Feature Pyramid Network
FPN:
Feature Pyramid Network 特征金字塔网络
FPN使用具有横旁路连接的自顶向下架构,以从单尺度输入构建网络中的特征金字塔。使用FPN的Faster R-CNN根据其尺度提取不同级别的金字塔的RoI特征,不过其他部分和平常的ResNet类似。使用ResNet-FPN进行特征提取的Mask R-CNN可以在精度和速度方面获得极大的提升。
参考博客(如有侵权请告知)
基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
目标检测方法简介:RPN(Region Proposal Network) and SSD(Single Shot MultiBox Detector)
CNN目标检测(一):Faster RCNN详解
深度卷积神经网络在目标检测中的进展
faster-rcnn原理及相应概念解释
目标检测分割–Mask R-CNN
Mask R-CNN论文翻译
三十分钟理解:线性插值,双线性插值Bilinear Interpolation算法
文中插图来源:
maskrcnn_slides.pdf