爬虫(七)BeautifulSoup4的学习
由于xpath解析数据需要对html结构有深刻的理解, 那么是不是还有其他的解析方法呢? 接下来介绍使用css选择器解析数据的操作库-------- BeautifulSoup4。
1 CSS 选择器:BeautifulSoup4的介绍和安装
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
- 安装:
pip install beautifulsoup4 - 官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
1.1 bs4的基本使用示例:
首先必须要导入 bs4 库
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建 Beautiful Soup 对象
soup = BeautifulSoup(html)
#打开本地 HTML 文件的方式来创建对象
#soup = BeautifulSoup(open('index.html'))
#格式化输出 soup 对象的内容
print soup.prettify()
运行结果:
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
注意:
如果在 Python 下执行,会看到这样一段警告:
意思是,如果没有显式地指定解析器,所以默认使用这个系统的最佳可用HTML解析器(“lxml”)。如果你在另一个系统中运行这段代码,或者在不同的虚拟环境中,使用不同的解析器造成行为不同。
可以通过soup = BeautifulSoup(html,“lxml”)方式指定lxml解析器。
2 搜索文档树
2.1 find_all(name, attrs, recursive, text, **kwargs)
1) name 参数
name 参数可以查找所有名字为 name 的tag
A 传字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签:
soup.find_all('b')
# [The Dormouse's story]
print soup.find_all('a')
#[, Lacie, Tillie]
B 传正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示和标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
C 传列表
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有标签和标签:
soup.find_all(["a", "b"])
# [The Dormouse's story,
# Elsie,
# Lacie,
# Tillie]
2)keyword 参数
soup.find_all(class = "sister")
#[, Lacie, Tillie]
soup.find_all(id='link2')
# [Lacie]
3)text 参数
通过 text 参数可以搜索文档中的字符串内容,与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
[u"The Dormouse's story", u"The Dormouse's story"]
2.2 find
find的用法与find_all一样,区别在于find返回 第一个符合匹配结果,find_all则返回 所有匹配结果的列表
2.3 CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法,也是返回所有匹配结果的列表。
-
写 CSS 时,标签名不加任何修饰,类名前加.,id名前加#
-
在这里也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
(1)通过标签选择器查找
print soup.select('title')
#[The Dormouse's story ]
print soup.select('a')
#[, Lacie, Tillie]
print soup.select('b')
#[The Dormouse's story]
(2)通过类选择器查找
print soup.select('.sister')
#[, Lacie, Tillie]
(3)通过 id 选择器查找
print soup.select('#link1')
#[]
(4)层级选择器 查找
print soup.select('p #link1')
#[]
(5)通过属性选择器查找
print soup.select('a[class="sister"]')
#[, Lacie, Tillie]
print soup.select('a[href="http://example.com/elsie"]')
#[]
(6) 获取文本内容 get_text()
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()
(7) 获取属性 get('属性的名字')
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('a'))
print soup.select('a')[0].get('href')
3 动手
用bs4来做一个简单的爬虫,爬取某个贴吧里的所有帖子,获取每个帖子的标题,连接和帖子中图片
思路分析:
-
推荐使用极速版的页面,响应不包含js,elements和url地址对应的响应一样
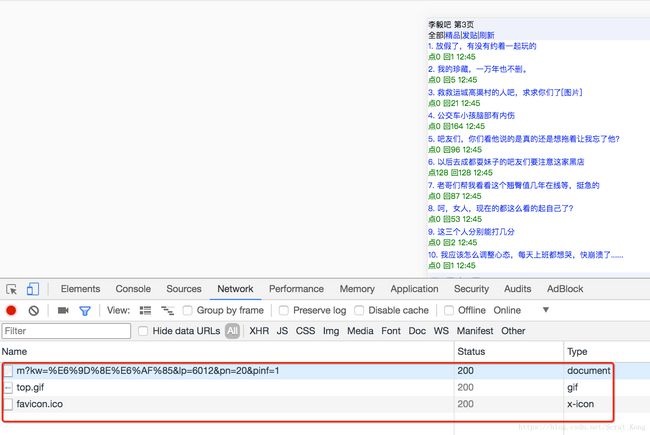
-
获取所有的列表页的数据即连接和标题
2.1. 确定url地址,确定程序停止的条件
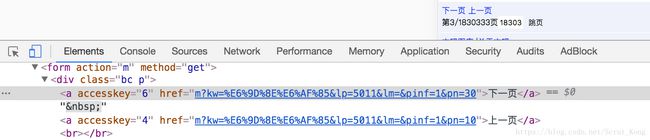
url地址的数量不固定,不能够去构造url列表,需要手动获取下一页的url地址进行翻页
有下一页的情况:
没有下一页的情况:
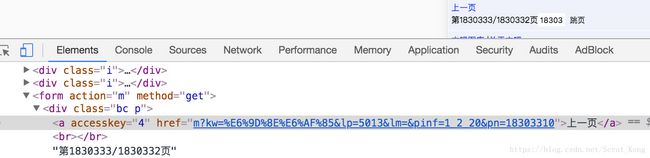
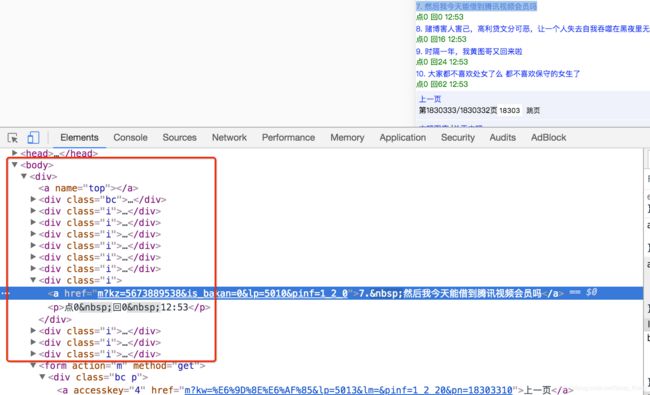
2.2. 确定列表页数据的位置
由于没有js,可以直接从elements中进行数据的提取
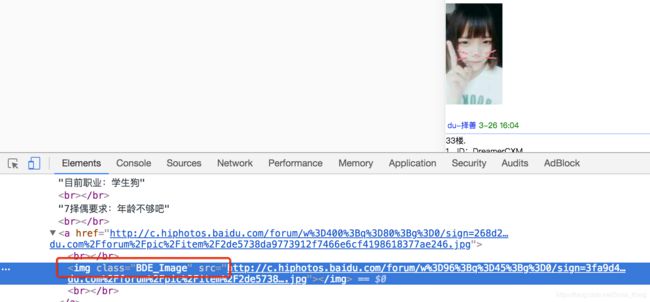
3. 获取帖子中的所有数据
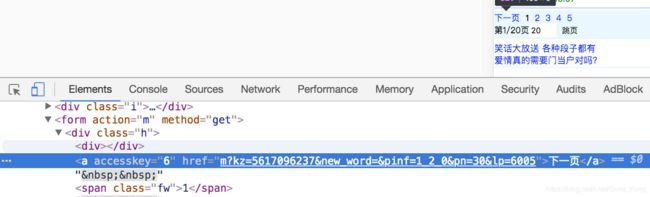
3.1 确定url地址
url详情页的规律和列表页相似
3.2 确定数据的位置
小结
- 安装beautifulsoup4:
pip install beautifulsoup4 - beautifulsoup导包:
from bs4 import BeautifulSoup - beautifulsoup转换类型:
BeautifulSoup(html) - find 方法返回一个解析完毕的对象
- findall 方法返回的是解析列表list
- select 方法返回的是解析列表list
- 获取属性的方法:
get('属性名字') - 和获取文本的方法:
get_text()