《机器学习》周志华西瓜书习题参考答案:第7章 - 贝叶斯分类器
【机器学习】《机器学习》周志华西瓜书 笔记/习题答案 总目录
- https://blog.csdn.net/TeFuirnever/article/details/96178919
——————————————————————————————————————————————————————
- 《机器学习》周志华西瓜书学习笔记(七):贝叶斯分类器
- 《机器学习实战》学习笔记(四):基于概率论的分类方法 - 朴素贝叶斯
习题
![]()
以第一个属性色泽为例,其值计数如下:
| 色泽 | 乌黑 | 浅白 | 青黑 |
|---|---|---|---|
| 好瓜(否) | 2 | 4 | 3 |
| 好瓜(是) | 4 | 1 | 3 |



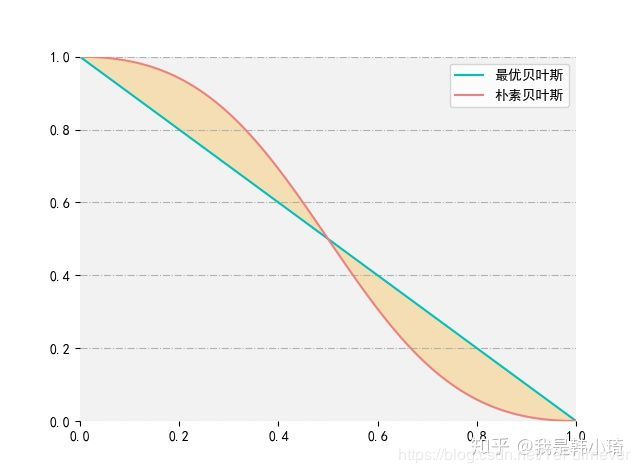
只有在两者决策边界之间(即上图浅黄色区域中),分类情况是不同的;在其他区域中,朴素贝叶斯分类结果和最优贝叶斯的分类结果是相同的,因此即便属性之间独立性假设不成立。
朴素贝叶斯在某些条件(本例中就是属性概率分布在两者相交区域之外)下仍然是最优贝叶斯分类器。
参考:
《On the Optimality of the Simple Bayesian Classifier under Zero-One Loss》

测1的数据:

import numpy as np
import pandas as pd
from sklearn.utils.multiclass import type_of_target
from collections import namedtuple
def train_nb(X, y):
m, n = X.shape
p1 = (len(y[y == '是']) + 1) / (m + 2) # 拉普拉斯平滑
p1_list = [] # 用于保存正例下各属性的条件概率
p0_list = []
X1 = X[y == '是']
X0 = X[y == '否']
m1, _ = X1.shape
m0, _ = X0.shape
for i in range(n):
xi = X.iloc[:, i]
p_xi = namedtuple(X.columns[i], ['is_continuous', 'conditional_pro']) # 用于储存每个变量的情况
is_continuous = type_of_target(xi) == 'continuous'
xi1 = X1.iloc[:, i]
xi0 = X0.iloc[:, i]
if is_continuous: # 连续值时,conditional_pro 储存的就是 [mean, var] 即均值和方差
xi1_mean = np.mean(xi1)
xi1_var = np.var(xi1)
xi0_mean = np.mean(xi0)
xi0_var = np.var(xi0)
p1_list.append(p_xi(is_continuous, [xi1_mean, xi1_var]))
p0_list.append(p_xi(is_continuous, [xi0_mean, xi0_var]))
else: # 离散值时直接计算各类别的条件概率
unique_value = xi.unique() # 取值情况
nvalue = len(unique_value) # 取值个数
# 计算正样本中,该属性每个取值的数量,并且加1,即拉普拉斯平滑
xi1_value_count = pd.value_counts(xi1)[unique_value].fillna(0) + 1
xi0_value_count = pd.value_counts(xi0)[unique_value].fillna(0) + 1
p1_list.append(p_xi(is_continuous, np.log(xi1_value_count / (m1 + nvalue))))
p0_list.append(p_xi(is_continuous, np.log(xi0_value_count / (m0 + nvalue))))
return p1, p1_list, p0_list
def predict_nb(x, p1, p1_list, p0_list):
n = len(x)
x_p1 = np.log(p1)
x_p0 = np.log(1 - p1)
for i in range(n):
p1_xi = p1_list[i]
p0_xi = p0_list[i]
if p1_xi.is_continuous:
mean1, var1 = p1_xi.conditional_pro
mean0, var0 = p0_xi.conditional_pro
x_p1 += np.log(1 / (np.sqrt(2 * np.pi) * var1) * np.exp(- (x[i] - mean1) ** 2 / (2 * var1 ** 2)))
x_p0 += np.log(1 / (np.sqrt(2 * np.pi) * var0) * np.exp(- (x[i] - mean0) ** 2 / (2 * var0 ** 2)))
else:
x_p1 += p1_xi.conditional_pro[x[i]]
x_p0 += p0_xi.conditional_pro[x[i]]
if x_p1 > x_p0:
return '是'
else:
return '否'
if __name__ == '__main__':
data_path = r'C:\Users\hanmi\Documents\xiguabook\watermelon3_0_Ch.csv'
data = pd.read_csv(data_path, index_col=0)
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
p1, p1_list, p0_list = train_nb(X, y)
x_test = X.iloc[0, :] # 书中测1数据,其实就是第一个数据
print(predict_nb(x_test, p1, p1_list, p0_list))
运行结果:
![]()

在博客 《机器学习》周志华西瓜书学习笔记(七):贝叶斯分类器 中提到过,可以使用 对数似然(log-likelihood) 的方法解决 连乘操作容易造成下溢,所以改写成:




这个题有点没推明白,这个答案是参考文章中的过程,先拿过来,等有空我再推一推。。。

''' 目前仅拿西瓜数据集测试过,运行正常,其他数据未测试 '''
import numpy as np
import pandas as pd
from sklearn.utils.multiclass import type_of_target
class AODE(object):
def __init__(self, m):
self.m_hat = m
self.m = None
self.n = None
self.unique_y = None
self.n_class = None
self.is_continuous = None
self.unique_values = None
self.total_p = None
def predict(self, X):
X = np.array(X)
if self.total_p is None:
raise Exception('you have to fit first before predict.')
result = pd.DataFrame(
np.zeros(
(X.shape[0],
self.unique_y.shape[0])),
columns=self.unique_y)
for i in self.total_p.keys():
result += self._spode_predict(X, self.total_p[i], i)
return self.unique_y[np.argmax(result.values, axis=1)]
def fit(self, X, y):
X = np.array(X)
self.m, self.n = X.shape
self.unique_y = np.unique(y)
self.n_class = self.unique_y.size
# 这里转为list, 是因为貌似type_of_target 有bug, 只有在pd.Series类型的时候才能解析为'continuous',
# 在这里转为array类型后解析为 'unknown'了
is_continuous = pd.DataFrame(X).apply(
lambda x: (type_of_target(x.tolist()) == 'continuous'))
self.is_continuous = is_continuous
unique_values = {} # 离散型字段的各取值
for i in is_continuous[~is_continuous].index:
unique_values[i] = np.unique(X[:, i])
self.unique_values = unique_values
# 获取可以作为父节点的属性索引,这里在论文中取值为30; 但在西瓜书中由于样本很少, 所有直接取0就好
parent_attribute_index = self._get_parent_attribute(X)
total_p = {}
for i in parent_attribute_index:
p = self._spode_fit(X, y, i)
total_p[i] = p
self.total_p = total_p
return self
def _spode_fit(self, X, y, xi_index):
p = pd.DataFrame(columns=self.unique_y,
index=self.unique_values[xi_index]) # 储存各取值下的条件概率
nunique_xi = self.unique_values[xi_index].size # 当前属性的取值数量
pc_xi_denominator = self.m + self.n_class * \
nunique_xi # 计算 p(c, xi) 的分母 |D| + N * N_i
for c in self.unique_y:
for xi in self.unique_values[xi_index]:
p_list = [] # 储存y取值为c, Xi取值为xi下各个条件概率p(xj|c, xi)和先验概率p(c, xi)
c_xi = (X[:, xi_index] == xi) & (y == c)
X_c_xi = X[c_xi, :] # y 取值 为c, Xi 取值为xi 的所有数据
pc_xi = (X_c_xi.shape[0] + 1) / pc_xi_denominator # p(c, xi)
# 实际上这里在j = i时, 个人理解应该是可以跳过不计算的,因为p(xi|c, xi) = 1,
# 在计算中都是一样的但这里为了方便实现,就没有跳过了。
for j in range(self.n):
if self.is_continuous[j]: # 字段为连续值, 假设服从高斯分布, 保存均值和方差
# 这里因为样本太少。有时候会出现X_c_xi为空或者只有一个数据的情况, 如何是离散值,依然可以计算;
# 但是连续值的情况下,np.mean会报warning, 只有一个数据时,方差为0
# 所有这时, 均值和方差以类别样本来替代。
if X_c_xi.shape[0] <= 1:
p_list.append(
[np.mean(X[y == c, j]), np.var(X[y == c, j])])
else:
p_list.append(
[np.mean(X_c_xi[:, j]), np.var(X_c_xi[:, j])])
else:
# 计算 p(xj|c, xi)
condi_proba_of_xj = (pd.value_counts(X_c_xi[:, j])[self.unique_values[j]].fillna(
0) + 1) / (X_c_xi.shape[0] + self.unique_values[j].size)
p_list.append(np.log(condi_proba_of_xj))
p_list.append(np.log(pc_xi)) # p(c, xi)在最后的位置
p.loc[xi, c] = p_list
return p
def _spode_predict(self, X, p, xi_index):
assert X.shape[1] == self.n
xi = X[:, xi_index]
result = pd.DataFrame(
np.zeros(
(X.shape[0],
p.shape[1])),
columns=self.unique_y) # 储存每个样本为不同类别的对数概率值
for value in p.index: # 为了可以使用pandas的索引功能, 对于要预测的X值, 每一次循环求同一取值下样本的条件概率和
xi_value = xi == value
X_split = X[xi_value, :]
for c in p.columns:
p_list = p.loc[value, c] # 储存p(xj|c, xi) 和 p(c, xi)的列表
for j in range(self.n): # 遍历所有的条件概率, 将对应的条件概率相加
if self.is_continuous[j]:
mean_, var_ = p_list[j]
result.loc[xi_value,
c] += (-np.log(np.sqrt(2 * np.pi) * var_) - (X_split[:, j] - mean_) ** 2 / (2 * var_ ** 2))
else:
result.loc[xi_value,
c] += p_list[j][X_split[:, j]].values
result.loc[xi_value, c] += p_list[-1] # 最后加上p(c, xi)
return result
def _get_parent_attribute(self, X):
''' 基于属性下各取值的样本数量,决定哪些属性可以作为父属性。 关于连续值的处理,在《机器学习》书中也没有提及,AODE的原论文也没有提及如何处理连续值, 考虑到若将连续值x_j作为父属性时,如何求解p(x_i|c, x_j)条件概率会比较麻烦(可以通过贝叶斯公式求解), 此外AODE本身就是要将取值样本数量低于m的属性去除的,从这个角度来说,连续值就不能作为父属性了。 所以这里连续值不作为父属性 :param X: :return: '''
enough_quantity = pd.DataFrame(X).apply(
lambda x: (
type_of_target(
x.tolist()) != 'continuous') & (
pd.value_counts(x) > self.m_hat).all())
return enough_quantity[enough_quantity].index.tolist()
if __name__ == '__main__':
data_path = r'E:\DAIMA\MachineLearning_Zhouzhihua_ProblemSets-master\data\watermelon3_0_Ch.csv'
data = pd.read_csv(data_path, index_col=0)
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
aode = AODE(0)
print(aode.fit(X, y).predict(X.iloc[[0], :]))
运行结果:
![]()
虽然在样本这么小的情况下,看预测结果实际意义不大,但相比于朴素贝叶斯,AODE对于西瓜数据集的拟合更好(错误率更低)。



书上p157页公式7.26,联合概率分布:



![]()
待填坑。

待填坑。
参考文章
- 机器学习(周志华)课后习题