ES 分片和副本数 调整及数据写入、重建索引调优
一、调整副本数
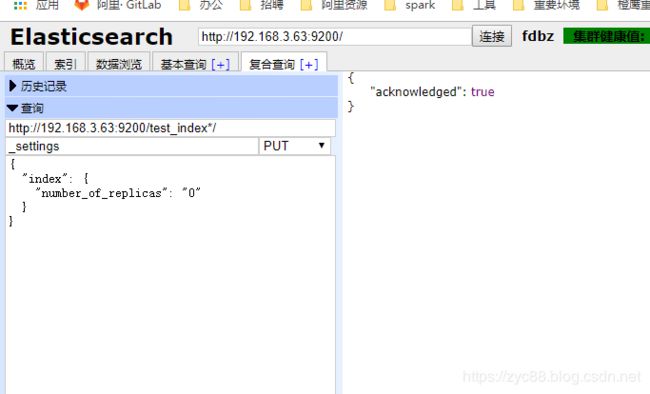
如调整副本数为0
curl -XPUT 'node3:9205/test_index/_settings' -d '{
"index": {
"number_of_replicas": "0"
}
}'
返回
{"acknowledged":true}
二、调整索引分片
索引分片数在索引创建好了之后就不能调整了,只能重建索引
(ES 5.X 版本中有一个缩小分片的api,需要先设置为只读,然后缩减过程需要大量的IO)
先创建索引
curl -XPUT 'http://localhost:9200/wwh_test2/' -d '{
"settings" : {
"index" : {
"number_of_shards" : 2,
"number_of_replicas" : 2
}
}
}'
或者同时指定mappings
curl -XPOST localhost:9200/test -d '{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type1" : {
"properties" : {
"field1" : { "type" : "string", "index" : "not_analyzed" }
}
}
}
}'
之后再进行重新索引
curl -XPOST 'http://localhost:9200/_reindex' -d '{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}'
开关索引
关闭
curl -XPOST 'localhost:9200/lookupindex/_close'
打开
curl -XPOST 'localhost:9200/lookupindex/_open'
关于重建索引调优
参数调优
ES 关键参数的调优。
有很多场景是,我们的 ES 集群占用了多大的 cpu 使用率,该如何调节呢。cpu 使用率高,有可能是写入导致的,也有可能是查询导致的,那要怎么查看呢?
可以先通过 GET _nodes/{node}/hot_threads 查看线程栈,查看是哪个线程占用 cpu 高,如果是 elasticsearch[{node}][search][T#10] 则是查询导致的,如果是 elasticsearch[{node}][bulk][T#1] 则是数据写入导致的。
我在实际调优中,cpu 使用率很高,如果不是 SSD,建议把 index.merge.scheduler.max_thread_count: 1 索引 merge 最大线程数设置为 1 个,该参数可以有效调节写入的性能。因为在存储介质上并发写,由于寻址的原因,写入性能不会提升,只会降低。
还有几个重要参数可以进行设置,各位同学可以视自己的集群情况与数据情况而定。
index.refresh_interval:这个参数的意思是数据写入后几秒可以被搜索到,默认是 1s。每次索引的 refresh 会产生一个新的 lucene 段, 这会导致频繁的合并行为,如果业务需求对实时性要求没那么高,可以将此参数调大,实际调优告诉我,该参数确实很给力,cpu 使用率直线下降。
indices.memory.index_buffer_size:如果我们要进行非常重的高并发写入操作,那么最好将 indices.memory.index_buffer_size 调大一些,index buffer 的大小是所有的 shard 公用的,一般建议(看的大牛博客),对于每个 shard 来说,最多给 512mb,因为再大性能就没什么提升了。ES 会将这个设置作为每个 shard 共享的 index buffer,那些特别活跃的 shard 会更多的使用这个 buffer。默认这个参数的值是 10%,也就是 jvm heap 的 10%。
translog:ES 为了保证数据不丢失,每次 index、bulk、delete、update 完成的时候,一定会触发刷新 translog 到磁盘上。在提高数据安全性的同时当然也降低了一点性能。如果你不在意这点可能性,还是希望性能优先,可以设置如下参数:
"index.translog": {
"sync_interval": "120s", --sync间隔调高
"durability": "async", -– 异步更新
"flush_threshold_size":"1g" --log文件大小
}
这样设定的意思是开启异步写入磁盘,并设定写入的时间间隔与大小,有助于写入性能的提升。
还有一些超时参数的设置:
discovery.zen.ping_timeout判断 master 选举过程中,发现其他 node 存活的超时设置discovery.zen.fd.ping_interval节点被 ping 的频率,检测节点是否存活discovery.zen.fd.ping_timeout节点存活响应的时间,默认为 30s,如果网络可能存在隐患,可以适当调大discovery.zen.fd.ping_retriesping 失败/超时多少导致节点被视为失败,默认为 3
调优主要是重建索引,更改了现有索引的分片数量,经过不断的测试,找到了一个最佳的分片数量,重建索引的时间是漫长的,在此期间,又对 ES 的写入进行了相应的调优,使 cpu 使用率降低下来。附上我的调优参数。
index.merge.scheduler.max_thread_count:1 # 索引 merge 最大线程数
indices.memory.index_buffer_size:30% # 内存
index.translog.durability:async # 这个可以异步写硬盘,增大写的速度
index.translog.sync_interval:120s #translog 间隔时间
discovery.zen.ping_timeout:120s # 心跳超时时间
discovery.zen.fd.ping_interval:120s # 节点检测时间
discovery.zen.fd.ping_timeout:120s #ping 超时时间
discovery.zen.fd.ping_retries:6 # 心跳重试次数
thread_pool.bulk.size:20 # 写入线程个数 由于我们查询线程都是在代码里设定好的,我这里只调节了写入的线程数
thread_pool.bulk.queue_size:1000 # 写入线程队列大小
index.refresh_interval:300s #index 刷新间隔
在重建索引之前,首先要考虑一下重建索引的必要性,因为重建索引是非常耗时的。
ES 的 reindex api 不会去尝试设置目标索引,不会复制源索引的设置,所以我们应该在运行_reindex 操作之前设置目标索引,包括设置映射(mapping),分片,副本等。
第一步,和创建普通索引一样创建新索引。当数据量很大的时候,需要设置刷新时间间隔,把 refresh_intervals 设置为-1,即不刷新,number_of_replicas 副本数设置为 0(因为副本数可以动态调整,这样有助于提升速度)。
{
"settings": {
"number_of_shards": "50",
"number_of_replicas": "0",
"index": {
"refresh_interval": "-1"
}
}
"mappings": {
}
}
第二步,调用 reindex 接口,建议加上 wait_for_completion=false 的参数条件,这样 reindex 将直接返回 taskId。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "old_index", //原有索引
"size": 5000 //一个批次处理的数据量
},
"dest": {
"index": "new_index", //目标索引
}
}
第三步,等待。可以通过 GET _tasks?detailed=true&actions=*reindex 来查询重建的进度。如果要取消 task 则调用_tasks/node_id:task_id/_cancel。
第四步,删除旧索引,释放磁盘空间。更多细节可以查看 ES 官网的 reindex api。
那么有的同学可能会问,如果我此刻 ES 是实时写入的,那咋办呀?
这个时候,我们就要重建索引的时候,在参数里加上上一次重建索引的时间戳,直白的说就是,比如我们的数据是 100G,这时候我们重建索引了,但是这个 100G 在增加,那么我们重建索引的时候,需要记录好重建索引的时间戳,记录时间戳的目的是下一次重建索引跑任务的时候不用全部重建,只需要在此时间戳之后的重建就可以,如此迭代,直到新老索引数据量基本一致,把数据流向切换到新索引的名字。
POST /_reindex
{
"conflicts": "proceed", //意思是冲突以旧索引为准,直接跳过冲突,否则会抛出异常,停止task
"source": {
"index": "old_index" //旧索引
"query": {
"constant_score" : {
"filter" : {
"range" : {
"data_update_time" : {
"gte" : 123456789 //reindex开始时刻前的毫秒时间戳
}
}
}
}
}
},
"dest": {
"index": "new_index", //新索引
"version_type": "external" //以旧索引的数据为准
}
}