Antlr4学习1-基本概念和入门示例
Antlr4学习1-基本概念和入门示例
0x00 系列文章目录
- Antlr4学习1-基本概念和入门示例
- Antlr4学习2-Java开发
0x01 摘要
ANTLR (ANother Tool for Language Recognition) 是一个强大的解析器的生成器,可以用来读取、处理、执行或翻译结构化文本或二进制文件。他被广泛用来构建语言,工具和框架。ANTLR可以从语法上来生成一个可以构建和遍历解析树的解析器。
Hive和Spark中使用antlr来生成词法和语法的解析器。
Antlr官网
0x02 安装ANTLR
ANTLR由两部分组成:
- 一个将用户自定义语法翻译成Java中的解析器/词法分析器的工具
- 一个用于生成解析器/词法分析器的runtime
所以,就算你是使用ANTLR的idea插件或者是ANTLRWorks来运行ANTLR工具,生成的代码依然需要运行时库。
2.1 插件安装
首先我们需要下载安装一个ANTLR开发工具的插件。
访问下载界面
所有用户都应该下载ANTLR工具本身,然后选择一个语言运行时目标,除非您使用的是工具jar中内置的Java。
这里我选择的是java,所以我是直接在IntelliJ IDEA里面安装的ANTLR v4 grammar plugin。
IntelliJ Idea Plugin for ANTLR v4
2.2 运行环境安装
我是mac系统,所以这里用的以下命令安装:
2.2.1 下载
cd /System/Library/Frameworks
curl -O http://www.antlr.org/download/antlr-4.7.1-complete.jar
2.2.2 设置CLASSPATH和ALIAS
将以下语句加入.bash_profile:
export CLASSPATH=".:/System/Library/Frameworks/antlr-4.7.1-complete.jar:$CLASSPATH"
alias antlr4='java -jar /System/Library/Frameworks/antlr-4.7.1-complete.jar'
alias grun='java org.antlr.v4.runtime.misc.TestRig'
2.2.3 安装成果检验
现在我们试试ANTLR安装成果,先来试试org.antlr.v4.Tool:
chengcdeMacBook-Pro:apps chengc$ java org.antlr.v4.Tool
ANTLR Parser Generator Version 4.7.1
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
-message-format ___ specify output style for messages in antlr, gnu, vs2005
-long-messages show exception details when available for errors and warnings
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener -visitor generate parse tree visitor -no-visitor don't generate parse tree visitor (default)
-package ___ specify a package/namespace for the generated code
-depend generate file dependencies
-D<option>=value set/override a grammar-level option
-Werror treat warnings as errors
-XdbgST launch StringTemplate visualizer on generated code
-XdbgSTWait wait for STViz to close before continuing
-Xforce-atn use the ATN simulator for all predictions
-Xlog dump lots of logging info to antlr-timestamp.log
-Xexact-output-dir all output goes into -o dir regardless of paths/package
也可以用java -jar /System/Library/Frameworks/antlr-4.7.1-complete.jar
0x03 示例
3.1 创建语法定义文件
创建一个语法定义文件:Hello.g4,内容如下:
// Define a grammar called Hello
grammar Hello;
r : 'hello' ID ; // 匹配关键字'hello'后面跟随一个ID
ID : [a-z]+ ; // 匹配小写字符组成的ID
WS : [ \t\r\n]+ -> skip ; // 匹配时跳过空格、tabs、换行符
3.2 ANTLR处理语法文件
然后使用ANTLR工具进行处理:
antlr4 Hello.g4
生成了若干java文件如下:
-rw-r--r-- 1 chengc admin 238 9 17 00:31 Hello.g4
-rw-r--r-- 1 chengc admin 308 9 17 00:34 Hello.interp
-rw-r--r-- 1 chengc admin 27 9 17 00:34 Hello.tokens
-rw-r--r-- 1 chengc admin 1304 9 17 00:34 HelloBaseListener.java
-rw-r--r-- 1 chengc admin 1055 9 17 00:34 HelloLexer.interp
-rw-r--r-- 1 chengc admin 3287 9 17 00:34 HelloLexer.java
-rw-r--r-- 1 chengc admin 27 9 17 00:34 HelloLexer.tokens
-rw-r--r-- 1 chengc admin 536 9 17 00:34 HelloListener.java
-rw-r--r-- 1 chengc admin 3578 9 17 00:34 HelloParser.java
3.3 编译生成的java类
再用javac进行编译javac Hello*.java。
3.4 测试
最后,我们进行测试:
3.4.1 解析树打印
首先是-tree参数会以LISP表示法打印解析树:
chengcdeMacBook-Pro:antlr4 chengc$ grun Hello r -tree
Warning: TestRig moved to org.antlr.v4.gui.TestRig; calling automatically
hello world
(r hello world)
注意,在输入关键字后要按control+D,下面的方式也需要同样输入。
3.4.2 解析树图形化展示
再试试-gui方式:
chengcdeMacBook-Pro:antlr4 chengc$ grun Hello r -gui
Warning: TestRig moved to org.antlr.v4.gui.TestRig; calling automatically
hello world
^D
会弹出一个界面展示了规则r匹配到了关键字hello且跟随一个标识符world:

3.4.3 token流展示
chengcdeMacBook-Pro:antlr4 chengc$ grun Hello r -tokens
Warning: TestRig moved to org.antlr.v4.gui.TestRig; calling automatically
hello world
[@0,0:4='hello',<'hello'>,1:0]
[@1,6:10='world',<ID>,1:6]
[@2,12:11='' ,<EOF>,2:0]
0x04 Grammar-语法
4.1 语法
一个语法定义文件一般来说有一个通用的结构如下:
/** 可根据需要撰写 javadoc 风格的注释,可以是单行、多行*/
grammar Name;
//注意以下options imports tokens actions指定顺序可以任意调换
options {name1=value1; ... nameN=valueN;}
import ... ;
tokens { Token1, ..., TokenN }
channels {...} // 只能是词法分析时才能定义
@actionName {...}
rule1 // 语法和词法分析规则定义,也有可能是混合在一起的规则定义
...
ruleN
4.1.1 grammar
定义语法名称。需要注意的是文件名X.g4必须与grammar X相同。
4.1.2 options
用来在grammar级别指定Antlr通过grammar文件生成代码的规则,如语言选项,输出选项,回溯选项,记忆选项等:
options { output=AST; language=Java; }
options { tokenVocab=MySqlLexer; }
4.1.3 import
可以用import将一个语法分割成多个逻辑上的、可复用的块。在antlr中,import语法很像面向对象编程语言中的超类的概念。一个grammar会继承用 import导入的grammar 的所有规则、tokens specifications以及actions。但是main grammar(也就是我们自己定义的grammar)内可以重写规则来覆盖继承的规则以实现继承。
下面是一个MyElang中import了Elang的示意图:

可以看到,MyElang中虽通过继承得到若干规则,但也重写了expr规则并增加了INT规则。
被import的grammar也可以import其他grammar,ANTLR采用深度优先的方式向上搜索。如多个grammar定义了同一个规则,ANTLR会选择第一个找到的规则。
下面是一个示例:
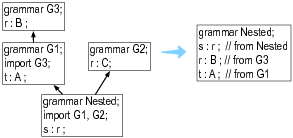
可以看到,规则r的确是基于搜读优先的原则选择了grammar G3中的值B。
还有一个例子,一个main grammar中定义了一个规则IF : 'if';,同时一个imported grammar定义了一个规则:ID : [a-z]+;。显然这个规则也会匹配到小写字符串if。那么这个imported的ID是不会将IF规则隐藏掉。
请记住import的原则:Lexer的只能import Lexer;Parser只能importParser;Combined grammar可以import 没有modes的 Parser或Lexer。
如果在main grammar或者importd 其他grammar中有modes,那么import过程中会引入他们然后合并而不是覆写。
如果指定了tokens,main grammar会将他们全部合并;
如果存在channel,那么main grammar会合并他们;
如果存在已命名的actions如@members会被合并。总的来说说,应该避免命名的actions或是存在于规则中的actions,以免重用性受限;
ANTLR会忽略所有在imported grammars中的options。
4.1.4 tokens
tokens块的目的是为那些没有关联词法规则的grammar来定义tokens的类型。许多时候,tokens被用来定义actions,下面是一个例子:
// explicitly define keyword token types to avoid implicit definition warnings
tokens { BEGIN, END, IF, THEN, WHILE }
@lexer::members { // keywords map used in lexer to assign token types
Map<String,Integer> keywords = new HashMap<String,Integer>() {{
put("begin", KeywordsParser.BEGIN);
put("end", KeywordsParser.END);
...
}};
}
4.1.5 channels
只有词法分析器的grammar中才能包含自定义的channels,下面是一个例子:
channels {
WHITESPACE_CHANNEL,
COMMENTS_CHANNEL
}
上面定义的channels可以在词法分析规则中像枚举一样使用:
WS : [ \r\t\n]+ -> channel(WHITESPACE_CHANNEL) ;
4.1.6 @actionName
用来定义一些动作。目前只有两个为java 目标定义的已命名actions,可以在外部grammar规则中使用,分别是@header和@members。
-
@header:会在recognizer class定义之前将代码注入生成的recognizer class`文件中。 -
@members:将代码作为值域和方法注入到recognizer class定义中。
下面是个小例子:
grammar SelectExample1;
@header {
package demos.antlr;
}
@members {
private String name = "chengc";
}
select : 'select' WHAT 'from' WHAT;
WHAT : [a-z]+ ;
WHERE : [a-z]+ ;
WS : [ \t\r\n]+ -> skip ; // 匹配时跳过空格、tabs、换行符
然后执行antlr4 SelectExample1.g4,观察生成的java类,可以看到在类开头加入了一行:
package demos.antlr;
还有在类定义中加入了以下内容:
private String name = "chengc";
4.1.7 rule
这里的rule指的就是各种parser和lexer规则。
rule的书写规范是以 : 开头 ,以 ; 结尾。多行规则以"|"竖线符号分隔。
- lexer
lexer定义时名字以大写字母开头。lexer用作词法分析。 - parser
parser定义时名字以小写字母开头。parser用作句法分析,是字符串和lexer的组合,用来匹配分析一个句子。
下面是一个例子:
grammar Hello;
r : 'hello' ID ; // parser. 匹配关键字'hello'后面跟随一个ID
ID : [a-z]+ ; // lexer. 匹配小写字符组成的ID
WS : [ \t\r\n]+ -> skip ; //lexer. 匹配时跳过空格、tabs、换行符
type // parser
: type ARRAY
| ARRAY '<' type '>'
| MAP '<' type ',' type '>'
| ROW '(' identifier type (',' identifier type)* ')'
| baseType ('(' typeParameter (',' typeParameter)* ')')?
;
0xFE 总结
本文主要介绍了antlr4的一些基本概念和安装运行方法,下一章继续讲java编程相关内容,请点击:Antlr4学习2-Java开发
0xFF 参考文献
Antlr官网
Antlr4-github
Antlr4-官方指南
IntelliJ Idea Plugin for ANTLR v4
语法例子
Antlr4 入门