Linux 安装以及基本使用Hadoop 详解
在 http://archive.apache.org/dist/ 去下载 hadoop,hadoop运行需要安装 JDK
1> 解压软件到目录
$ tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules
2> 删除 hadoop 中的 share/doc 目录,该目录中存放着Hadoop相关文档用的比较少,占用空间有几G且会影响 hadoop 编译
$ cd share
$ rm -rf ./doc/
3> 设置 Java 安装目录
使用远程编辑软件 进入到 modules/hadoop-2.5.0/etc/hadoop
<1> 编辑 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 文件
将文件中 export JAVA_HOME=${JAVA_HOME} 的 ${JAVA_HOME} 替换成Java目录,使用指令 #
echo ${JAVA_HOME} 查看


<2> 编辑 $HADOOP_HOME/etc/hadoop/mapred-env.sh 文件
设置 JAVA_HOME
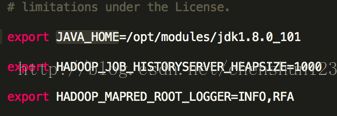
<3> 编辑 $HADOOP_HOME/etc/hadoop/yarn-env.sh 文件
设置 JAVA_HOME

4> 配置 *-site.xml 自定义文件
使用远程编辑软件 进入到 modules/hadoop-2.5.0/etc/hadoop
<1> 编辑 $HADOOP_HOME/etc/hadoop/core-site.sh 文件,指定namenode主节点所在的位置以及交互端口号,设置本机ip地址,使用 $ hostname 查看

注 : 交互的端口号可以修改,由于 apache 一般使用 80 端口号因此此处设置默认端口号 80 开头
fs.defaultFS 默认存放在本地

<2> 修改 hadoop.tmp.dir 的默认临时路径
在 hadoop 跟目录下创建 data/tmp 目录
$ mkdir -p data/tmp
编辑 $HADOOP_HOME/etc/hadoop/core-site.sh 文件,增加如下信息

hadoop.tmp.dir 是默认临时路径,默认在缓存目录,会被清理掉因此需要修改路径
<3> 指定 datanode 从节点所在的位置
编辑 slaves 文件,使用 $hostname 查看机器地址,并设置到文件中
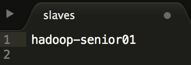
注:slaves 既代表 datanode 又代表 namenode
<4> 指定副本个数
编辑 $HADOOP_HOME/etc/hadoop/hdfs-site.sh 文件

5> 对于NameNode进行格式化操作
$ bin/hdfs namenode -format
注:1> 在 hadoop 根目录中使用 $ bin/hdfs 指令查看所有指令
2> 只需要一次格式化,多次格式化会出错
6> 启动相关的服务进程
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
注:使用 $jps 查看运行的相关进程
通过web浏览器加上50070端口号访问管理界面,访问地址: http://hadoop-senior01:50070/

对于HDFS文件系统进行读写上传下载测试:
$ bin/hdfs dfs -mkdir -p tmp/conf
// 创建目录
$ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/chenshun/tmp/conf
// 上传文件
$ bin/hdfs dfs -cat /user/chenshun/tmp/conf/core-site.xml
// 查看文件
$ bin/hdfs dfs -get /user/chenshun/tmp/conf/core-site.xml /home/chenshun/cs-site.xml
// 下载文件
注 : hdfs也存在用户注目录的概念
报错要首先去看日志文件的报错信息
> hadoop-2.5.0/logs/查看具体的日志文件
> 查看以 .log 结尾的文件
使用 more 指令查看文件
7> reduce获取数据的方式
编辑 $HADOOP_HOME/etc/hadoop/yarn-site.xml 文件,增加如下信息
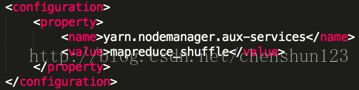
指定ResourceManager的位置,可配可不配
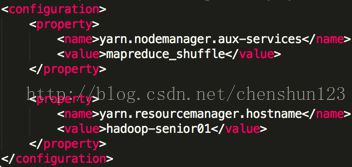
8> 指定 MapReduce 运行在 YARN 上
进入到 $HADOOP_HOME/etc/hadoop/
将 mapred-site.xml.template 重命名为 mapred-site.xml,编辑该文件增加

在主目录下执行如下指令运行 yarn
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
通过web浏览器加上8088端口号访问管理界面,访问地址: http://hadoop-senior01:8088/

YARN:分布式资源管理框架
管理整个集群的资源(内存、CPU核数)
分配调度集群的资源
MapReduce程序打成jar包运行在YARN上
$ bin/hdfs dfs -mkdir -p /user/chenshun/mapreduce/wordcount/input
// 创建输入目录
$ bin/hdfs dfs -put data/tmp/wc.input /user/chenshun/mapreduce/wordcount/input
// 上传文件到目录中
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output
// 打包运行(每次运行输出路径都不能相同)
察看结果
$ bin/hdfs dfs -cat /user/chenshun/mapreduce/wordcount/output/part*
// 察看文本结果
$ bin/hdfs dfs -text /user/chenshun/mapreduce/wordcount/output/part* // 推荐使用,能转换成文本在查看
9> 日志文件
(1)启动日志文件目录 $HADOOP_HOME/logs
(2)分析日志文件格式 log 和 out
.log:通过 log4j 记录的,记录大部分应用程序的日志信息
.out:记录标准输出和标准错误日志,少量记录
(3)日志文件的命名规则:框架名称-用户名-进程名-主机名-日志格式后缀
历史服务器
historyServer : 查看已经完成的历史作业记录
编辑 $HADOOP_HOME/etc/hadoop/mapred-site.xml 文件增加,注可配可不配
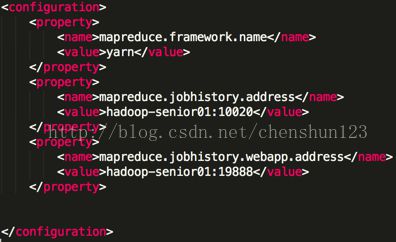
启动历史服务器
$ sbin/mr-jobhistory-daemon.sh start historyserver
在 http://hadoop-senior01:8088/cluster 的运行中点击 History 查看历史信息,查看信息状态
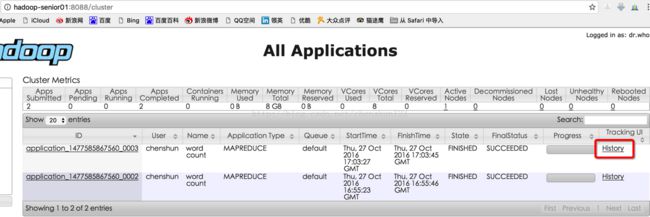
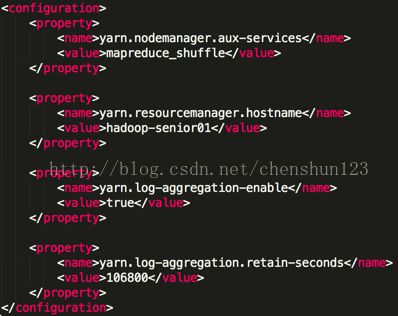
10> 日志聚集
将 mapreduce 产生的日志文件上传到 HDFS 文件系统上,就可以从页面上查看日志文件
编辑 $HADOOP_HOME/etc/hadoop/yarn-site.xml 文件增加
<1> 指定是否开启日志聚集功能,默认为 false
<2> 设置日志在HDFS上保留的时间期限
配置完成之后,需要重启YARN的服务进程,然后重新跑一次任务就可以查看过往的日志信息,historyserver同样也要重启
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/mr-jobhistory-daemon.sh
stop
historyserver
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$
sbin/mr-jobhistory-daemon.sh
start
historyserver
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output3
11> HDFS文件权限检测
<1> 设置不启用HDFS文件系统的权限检查,默认为 true
编辑 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件增加
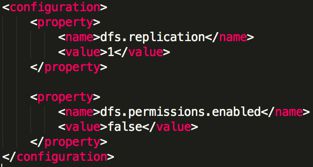
<2> 指定修改 Hadoop静态用户名,默认是 dr.who
编辑 $HADOOP_HOME/etc/hadoop/core-site.xml 文件增加

配置之后需要重启HDFS相关的进程
$ sbin/hadoop-daemon.sh stop namenode
$ sbin/hadoop-daemon.sh stop datanode
$ sbin/mr-jobhistory-daemon.sh
stop
historyserver
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
$ sbin/mr-jobhistory-daemon.sh start historyserver
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
浏览器访问地址 http://hadoop-senior01:19888/
常见错误
1> 格式化错误
2> 集群 id 不一致
注:建议不要切换多用户去操作,否则将会出现异常错误
经常出现的警告
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
在 $HADOOP_HOME/lib/native 目录中,不能获取编译者在什么系统上进行编译的,所以会导致版本不一致,无法加载本地库
解决方法,直接替换改库到指定版本:
$ cd /opt/softwares/
$ tar -zxf native-2.5.0.tar.gz -C /opt/modules/
$ cd /opt/modules/hadoop-2.5.0/lib
$ mv native/ back_native
$ cp -r /opt/modules/native/ /opt/modules/hadoop-2.5.0/lib
在 $HADOOP_HOME 中执行如下指令就不会出现警告
$ bin/hdfs dfs -ls /
12> Hadoop配置文件
1、分为两类:默认配置文件、自定义配置文件
2、第一步加载默认配置文件
3、第二步加载自定义配置文件
4、优先级:自定义的文件优先级高于默认配置文件
HDFS
core-default -site
hdfs-default -site
服务端server
客户端client